






1. motivation
文章 argue了 之前的 over-smoothing现象。 前面很多工作都从 随机游走,markov,能量,图扩散角度都会说出 多层gcn会 到达一个稳态。这是正确的,但是 实际上 gcn在7,8层就会很差了,k=8 远远小于 ∞,因此,作者说出 这是训练的原因: 包括 1.前向传播的 特征amplifiy 2.反向传播 梯度得消失
note:文章二作 是 EGNN的作者(迪利克雷能量),一作 吉大, 文章和迪利克雷能量那篇文章有相似之处, 都是对参数矩阵W进行处理,同时对后续训练过程中的W施加 正交化范数限制。两篇文章的MPNN和 GCNII都很相似,采用 I 矩阵。 同时点出 解耦 AX XW的必要性。 XW导致 难训练
2. Forward and Backward Signaling Analysis
2.1 正向
这一部分就是分析 前向传播和 反向传播 会出现的问题
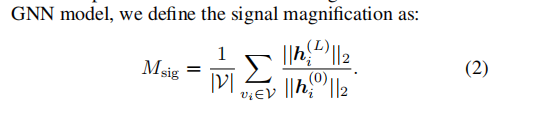
前向过程 Msig 是 后续层和第一层 hi的2范数比值之和。 作者 画出了 gcn和所提出model的。gcn会让表征一直放大
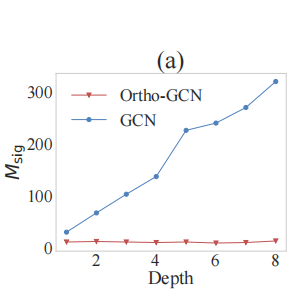
论点: 注释中的两点,因此本文目的是不让传播过程指数增长
2.2 反向
去掉非线性激活函数进行分析

定理1 表明了gcn梯度更新的问题

methodology
1. Hybrid weight initialization
参数矩阵 = 采用glorot初始化的参数 + 一个单位 初始化 很像 GCNII

2. Orthogonal transformation
采用一个额外的正交转化层来使得 W在 XW之前正交。
正交转化 包括两部分 1 通过对Q进行F范数约束 2 通过Q形成W。但计算 M的平方根 是 指数复杂的,采用牛顿迭代法计算

最终 W 通过 下面的 公式进行计算

3. Orthogonal regularization
这里说出 尽管 对W正交,由推导可得,上一层表征矩阵的F范数是 大于等于 下一层。。。 但这和前面 向量的 2范数推出的不矛盾吗?

作者对于后续层 的 W 仍然 施加正则约束。 这里和 EGNN的做法很像,EGNN的W-I,是正交化的一种特例

实验
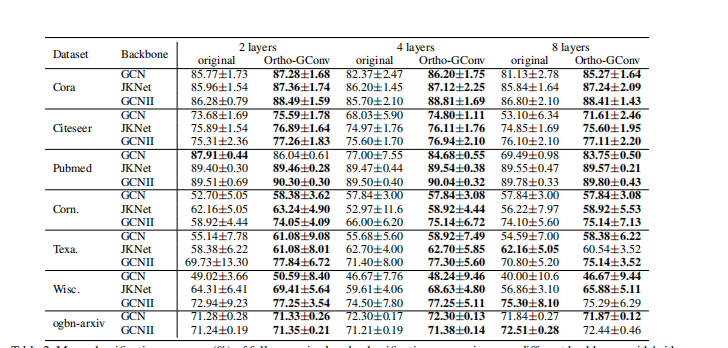
有一定效果,但是半监督节点分类,效果还是会掉 (层数多的时候)、

代码
本文的代码是 在 GCNII 原作者的代码基础上进行修改

model.py
GCN 包括输入输出,参数初始化,这里没有 采用 linear来构造层,而是通过tensor parameter

多种初始化参数矩阵的方法
正交转化层:
54-56 对这个 Z初始化,形成S(论文中的P) S是 Z和Z的转置 + eps的单位矩阵,即原论文公式4 norm_s 是S的F范数。 62行计算出 Qhat。
63-66 是初始化 每一层的Bt,从而通过67行计算出 W

网络定义 通过 nn.moduleList 来堆叠 一般 顺序 dropout+conv+act 输出为 log_softmax

正交损失:迫使后续层的w 和w的转置 和 单位矩阵的 范数 相接近。 对应原文的公式7
















 5826
5826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









