









talk
这篇文章没有什么特别新颖的,一作是北大的硕士,查询过程中好像没有其他工作,18年硕士,文章采用重构损失(A,X)+互信息。 主要看点:graphsaint在图采样上的实现,不是利用 pytorch_geometry
model
总体上 来说 : 采样graphsaint来进行无偏采样,之后对采样后的子图进行对比学习(DGI)
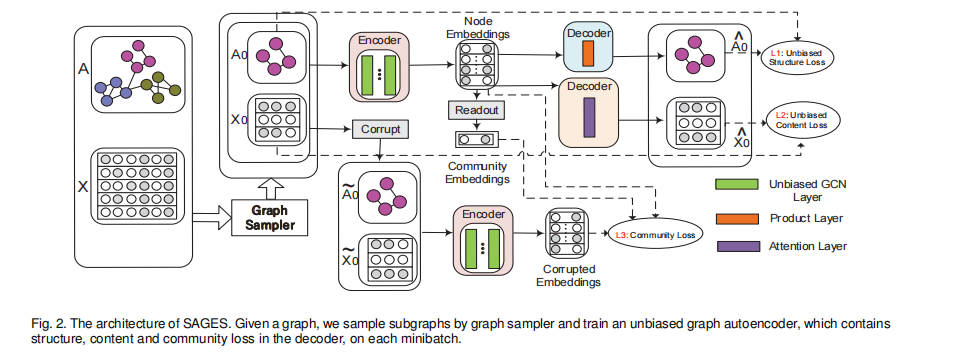
损失
1. A的重构损失(GAE常用)

2. 特征矩阵X的重构损失
作者声称 采样 会破坏结构,因此邻接矩阵重构不一定充分,这里考虑重构特征矩阵。
和ARGAX里面不同的是,这里采用 attention
分三步
latent Z和 Watt相乘 非线性激活后和vs向量乘 获得一个 attention向量
这个向量和 At进行哈达玛积 形成 Ms
Mr同理,两者求和后激活softmax 形成C,C和X 通过14 来形成decoder
这里还是有点维度问题不明白 Ct和 Zt 能形成 X重构的X’吗? 看代码再说

3. 互信息 节点和子图级 文中称 community-specifc
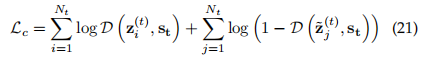
整体损失 remark :

前两项λ 的数值,根据预处理 实验中获取的pv puv设置
前面无偏采样


实验
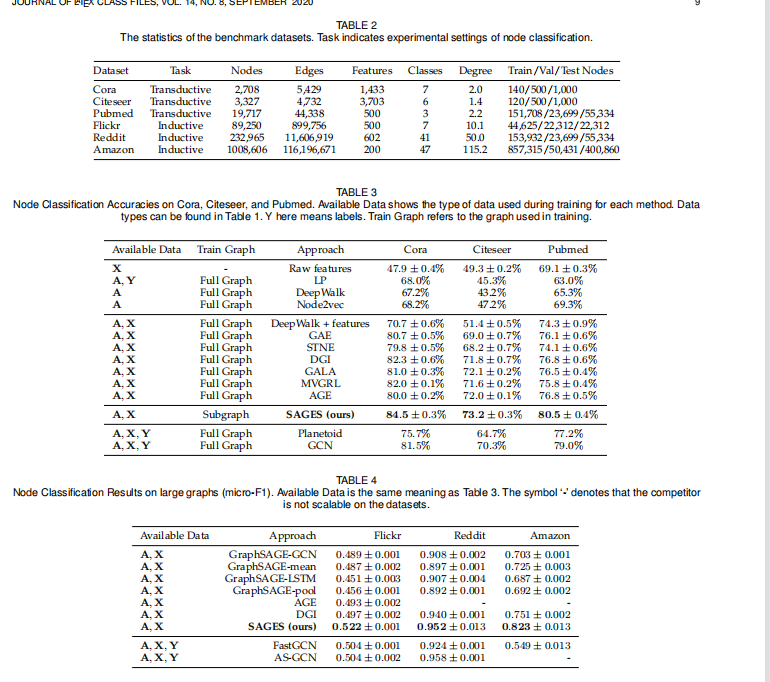
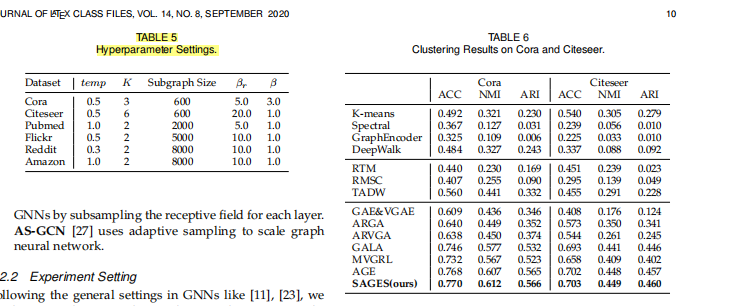
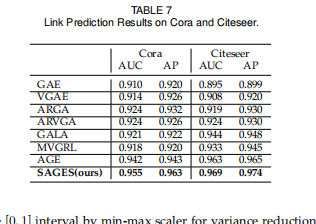
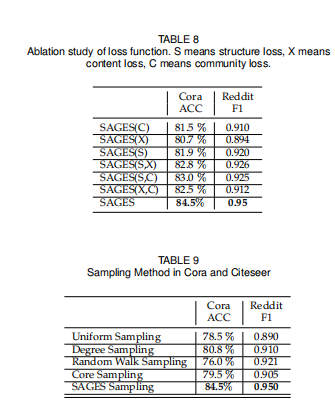
实验部分还是比较完善的,节点分类,聚类,连接预测,超参数分析,可视化,消融,不同采样策略分析
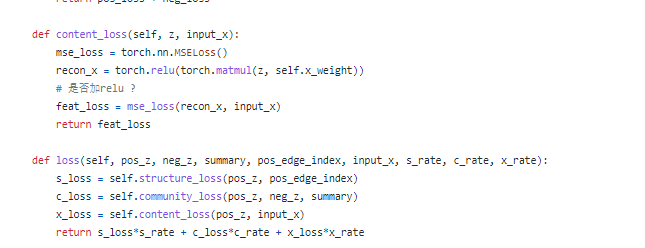
代码
基于 PYG的 DGI+graphsaint 实现。
重构邻接矩阵,直接就是 通过 self.x_weight把 Z的维度 转换到和 输入X相同的维度,并没有 采用so-called的 attention。。
rethink
全文除了 graphsaint采样 利用了 概率论的一些知识(graphsaint原文应该有)。其余部分很简单,GAE+重构x+ DGI














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









