







talk
Lecun组的, Barlow Twins的后续工作,在Barlow Twins的基础上增加了一个 variance损失
1.model
encoder是Siamese网络,共享参数。 作者在文中也说可以是 不同的 网络结构,但他们采用simamese网络,有个类似projection的part,只是预训练的时候用。之后就采用encoder的表征作为下游任务。作者说: 第二项 采用标准差而并非方差很关键,如果是采用方差,当两个x很接近,梯度就变成0,模型就崩了。 同时文章计算的时候不需要进行正则。
1.1整体
采用裁剪,颜色失真来生成两个视图,经过encoder 学到h。 h经过expander学到z,z计算损失
1.2 损失
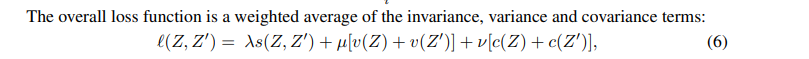
第一项损失:不变项 invariance。
样本对之间均方误差。两个视图Z进行表征相减。
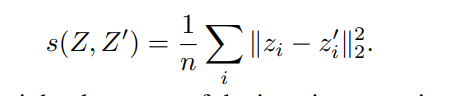
核心:第二项损失
variance项,来保证模型不崩塌(不映射到相同的向量)。 两个表征自身 、
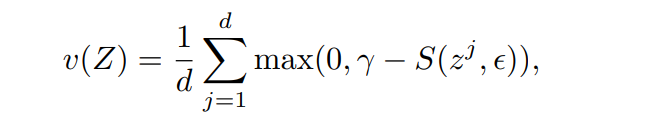
hinge损失,zj是z的第j维,相当于是每个维度都进行变化,S是标准差,ε是小常数来防止数值上不稳定。
损失使得 每个batch的 variance都等于γ,γ是一个目标常数(对于标准差)。这里S的计算是采用这样的标准差,而非方差,防止了样本梯度=0,模型崩塌。
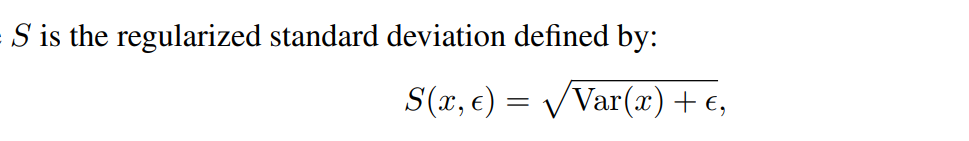
第三项损失: covariance损失 – BT的损失
表征非对角元素和。这个损失使得 表征不同 维度(特征)不相关,防止不同维度编码相似信息。
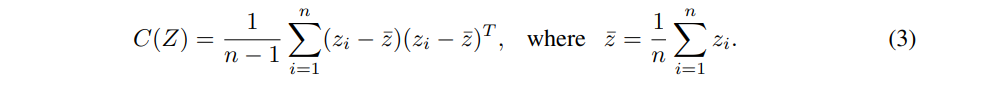
协方差矩阵,损失是 矩阵的非对角元素之和。

















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









