







2D/3D/1*1/Ttransposed/Dilated/Spatially Separable/Depthwise Separable/Flattened/Grouped/Shuffled Grouped Convolution
概述
卷积的目的:从输入中提取到有用特征。
卷积核相当于滤波器。
利用不同的卷积核可以得到不同的特征,卷积核的权重(w)在训练期间自动学习。
优势
- 权重共享
- 平移不变性
- 局部感受野
单通道卷积

在深度学习中,卷积是元素对元素的加法和乘法。卷积核滑过输入,对于3×3的卷积核,每次覆盖输入的9个值,这9个值与卷积核点乘相加,得到一个结果数字,作为输出特征图的一个值。
举例:12.0 = 3 × 0 + 3 × 1 + 2 × 2 + 0 × 2 + 0 × 2 + 1 × 0 + 3 × 0 + 1 × 1 + 2 × 2
其中,[[0, 1, 2], [2, 2, 0], [0, 1, 2]] 为卷积核C,Y中每一个值都受到X中9个邻域的影响(局部感受野)。且Y中的每一个值都是由X与卷积核点乘相加,即权重共享。Y为特征图。
卷积核
- Kernel size(卷积核大小):卷积核大小定义了卷积的视图
- Stride(步长):定义了卷积核在图像中移动的每一步大小。例如stride=2,那么卷积核在图像中就是按2个像素移动。
- Padding:在图像外围补充一些像素点,例如0,目的是为了保持空间的输出维度等于输入图像。
例如下图,Kernel size=3,Stride=1,Padding=1:

计算公式
输入图像大小为n, kernel size = k, padding = p, stride = s, 输出为y
y
=
l
o
w
e
r
b
o
u
n
d
(
i
+
2
p
−
k
s
)
+
1
y = lower_bound(\frac{i+2p-k}{s})+1
y=lowerbound(si+2p−k)+1
多通道卷积(2D卷积)
在计算机视觉等领域,很多输入都不是单通道,而是多通道。例如RGB图像就是3通道。
相关术语
- layers(层):一层可以有多个通道
- channels(通道):常被用来描述“layer”的结构
- feature maps(特征图)
- filters(滤波器):卷积核集合
- kernels(卷积核):常被用来描述"filter"的结构
举例


- 输入:5×5×3的矩阵,3个通道
- 滤波器:3×3×3的矩阵,3个卷积核
卷积过程
- filter中的每个卷积核分别应用于输入层中的三个通道。执行三次卷积,产生3个3x3的通道。
- 这三个通道相加(矩阵加法),得到一个3x3x1的单通道。这个通道就是在输入层(5x5x3矩阵)应用filter(3x3x3矩阵)的结果。

2D卷积
此外,这也可以看做是一个3D滤波器矩阵划过输入层。输入层和滤波器有相同的深度(通道数量 = 卷积核数量)
3Dfilter只需要在2维方向上移动,图像的高和宽。这也是为什么这种操作被称为2D卷积,尽管是使用的3D滤波器来处理3D数据。在每一个滑动位置,我们执行卷积,得到一个数字。就像上面的例子中体现的,滑动水平的5个位置和垂直的5个位置进行。总之,我们得到了一个单一通道输出。
不同层深度之间的转换
假设输入层为Hin × Win × Din, 共有Din个通道,我们想得到Hout × Wout × Dout的输出,共有Dout个通道。我们只需要将Dout filters应用到输入层。
- 每一个 filter有Din个卷积核。
- 每个filter提供一个单一的通道输出。
- 完成该过程,将结果堆叠在一起形成输出层。
卷积核大小为m×n×Din×Dout
代码
3D卷积
上节中的2D卷积实质上就是3D卷积,但在深度学习中,我们把它看作是2D卷积。
深度学习中 的3D卷积是指滤波器的深度小于输入层的深度,此时滤波器不能像在2D卷积中一样,只在两个维度方向上移动,而是在数据的三个维度上移动。在滤波器移动的每个位置,执行一次卷积,得到一个数字。当滤波器滑过整个3D空间,输出的结果也是一个3D的。

1×1 卷积
输入的数据是尺寸是H x W x D,滤波器尺寸是1 x 1x D,输出通道尺寸是H x W x 1。如果我们执行N次1x1卷积,并将结果连接在一起,那可以得到一个H x W x N的输出。

优势
- 降维以实现高效计算
- 高效的低维嵌入,或特征池
- 卷积后再次应用非线性
转置卷积(Transposed Convolution)
【举例】输入是2 x 2,填充2 x 2的0边缘,3 x 3的卷积核,stride=1。上采样输出大小是4 x 4。

空洞卷积(Dilated Convolution)
计算公式:
(
F
∗
l
k
)
(
p
)
=
∑
s
+
l
t
=
p
F
(
s
)
k
(
t
)
(F *_l k)(p) = \sum_{s+lt=p}F(s)k(t)
(F∗lk)(p)=s+lt=p∑F(s)k(t)
当 l = 1 时,称为标准离散卷积
空洞卷积通过在卷积核元素之间插入空格来“扩张”卷积核。扩充的参数取决于我们像如何扩大卷积核。内核元素之间通常会插入 l-1 个空格。如下图:

优势:在不增加参数量的同时,增加感受野
分离卷积(Separable Convolution)
空间分离卷积(Spatially Separable Convolution)
在图像的2D空间维度上操作。
从概念上说,可以将该卷积操作分为两步。
即3×3的卷积核可以由两个卷积核相乘得到,例如:
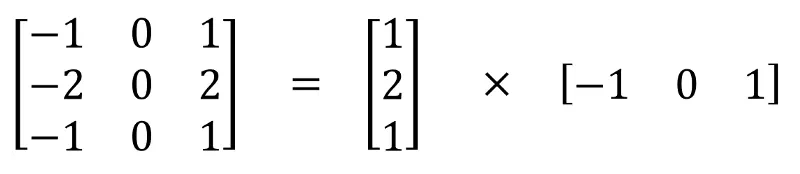
这样,只需要6个参数就可以搞定了。
【举例】
一个5 x 5的图像,3 x 3的卷积核(stride=1,padding=0),需要水平扫描三次,垂直扫描三次。有9个位置,可以看下图。在每个位置,9个元素要进行乘法。所以总共是要执行9 x 9=81次乘法。

而空间分离卷积的操作如下:
首先应用3 x 1的filter在5 x 5图像上。那么应该是水平扫描5个位置,垂直扫描3个位置。那么总共应该是5 x 3=15个位置,如下方有黄点的图所示。在每个位置,完成3次乘法,总共是15 x 3=45次乘法。现在我们得到的是一个3 x 5的矩阵。然后再在3 x 5矩阵上应用1 x 3kernel,那么需要水平扫描3个位置和垂直扫描3个位置。总共9个位置,每个位置执行3次乘法,那么是9 x 3=27次,所以完成一次Spatially Separable Convolution总共是执行了45+27=72次乘法,这比一般卷积要少。

总结
应用卷积在一个N x N的图像上,kernel尺寸为m x m,stride=1,padding=0。传统卷积需要(N-2) x (N-2) x m+(N-2)x(N-2)xm=(2N-2)x(N-2)xm次乘法。
标准卷积和Spatially Separable Convolution的计算成本比为:
2
m
+
2
m
(
N
−
2
)
\frac{2}{m}+\frac{2}{m(N-2)}
m2+m(N−2)2
当有的层,图像的尺寸N远远大于过滤器的尺寸m(N>>m)时,上面的等式就可以简化为2/m。这意味着,在该种情况下,如果kernel大小为3 x 3,那么Spatially Separable Convolution的计算成本是传统卷积的2/3。
虽然Spatially Separable Convolution可以节省成本,但是它却很少在深度学习中使用。最主要的原因是,不是所有的kernel都可以被分为两个更小的kernel的。如果我们将所有传统卷积用Spatially Separable Convolution替代,那么这将限制在训练过程中找到所有可能的kernels。找到的结果也许就不是最优的。
优势:减少参数
Depthwise Separable Convolution
【举例】
-
标准2D卷积
输入的大小是7 x 7 x 3(高、宽、通道数)。卷积核大小3 x 3 x 3。完成2D卷积操作之后,输出是5 x 5 x 1(只有一个通道)。

一般的,两个网络层之间会有多个过滤器。这里我们有128个过滤器。在应用128个2D卷积后,我们有128个5 x 5 x 1的输出特征图。我们然后将这些特征图堆叠到单层,大小为5 x 5 x 128。通过该操作,我们将输入(7 x 7 x 3)的转换成了5 x 5 x 128的输出。在空间上,高度和宽度都压缩了,但是深度拓展了。

-
depthwise separable convolution
首先,我们将deothwise convolution应用到输入层。和使用单一3 x 3 x 3filter在2D卷积上不同,我们使用3个分开的kernel。每个kernel的尺寸是3 x 3 x 1。每个kernel只完成输入的单通道卷积。每个这样的卷积操作会得到一个5 x 5 x 1的特征图。然后,我们将三个特征图堆叠到一起,得到一个5 x 5 x 3的图像。操作结束,输出的大小为5 x 5 x 3。我们压缩了空间维度,但是输出的深度和输入是一样的。

depthwise separable convolution的第二步是,扩充深度,我们使用大小为1 x 1 x 3的kernel,完成1 x 1卷积。最后得到5 x 5 x 1的特征图。

在完成128个1 x 1卷积操作之后,我们得到了5 x 5 x 128的层。

通过上面的两步,deothwise separable convolution将输入(7 x 7 x 3)的转换成了5 x 5 x 128的输出。
整个过程如下图:

优势:效率 -
2D卷积的计算消耗:有128个3 x 3 x 3卷积核,移动5 x 5次。一共要执行128 x 3 x 3 x 3 x 5 x 5=86400乘法。
-
separable convolution:在第一步deothwise convolution中,这里有3个3 x 3 x 1kernel,移动5 x 5次,一共是675次乘法。在第二步中,128个1 x 1 x 3卷积核移动5 x 5次,一共9600次乘法。总的计算消耗是675+9600=10275次乘法。消耗仅仅只有2D卷积的12%。
劣势:减少了卷积的参数
如果是一个较小的模型,那么模型的空间将显著减小。这造成的结果就是,模型得到的结果并不是最优。
参考:一文带你了解深度学习中的各种卷积(上)
https://blog.csdn.net/weixin_35479108/article/details/84629464














 2915
2915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









