







文章目录
- Apache Hadoop集群搭建
-
- 一、Hadoop集群简介
- 二、Hadoop集群模式安装(Cluster mode)
-
- 思路
- Hadoop源码编译
- Step1:集群角色规划
- Step2:服务器基础环境准备
- Step3:上传安装包、解压安装包
- Step4:Hadoop安装包目录结构
- Step5:编辑Hadoop配置文件(0)
- Step5:编辑Hadoop配置文件(1)
- Step5:编辑Hadoop配置文件(2)
- Step5:编辑Hadoop配置文件(3)
- Step5:编辑Hadoop配置文件(4)
- Step5:编辑Hadoop配置文件(5)
- Step5:编辑Hadoop配置文件(6)
- Step6:分发同步安装包
- Step7:配置Hadoop环境变量
- 总结
- Step8:NameNode format(格式化操作)
- 总结
- 三、Hadoop集群启停命令、Web UI
- 四、Hadoop初体验
Apache Hadoop集群搭建
一、Hadoop集群简介
Hadoop集群整体概述
- Hadoop集群包括两个集群:HDFS集群、YARN集群
- 两个集群逻辑上分离、通常物理上在一起
- 两个集群都是标准的主从架构集群
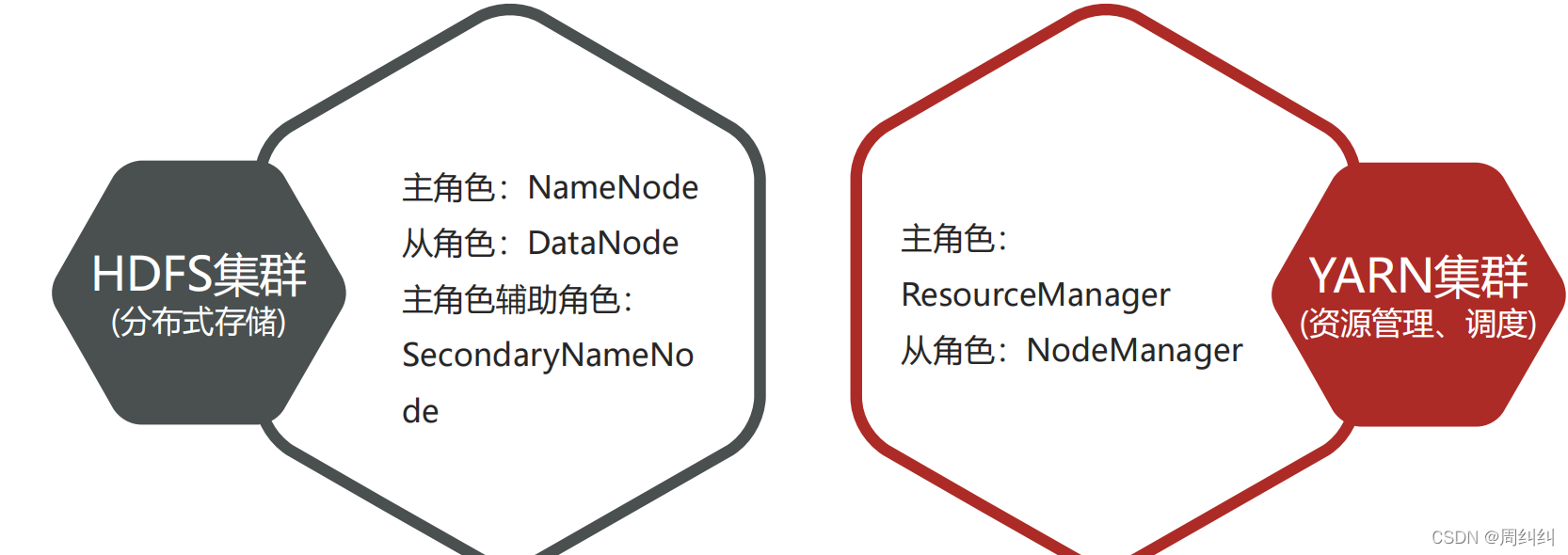
HDFS集群:NN,DN,SNN
YARN集群:RM,NM
思考
- 如何理解两个集群逻辑上分离?
- 如何理解两个集群物理上在一起?
- 为什么没有MapReduce集群?有这样的说法吗?
Hadoop集群简介

例中所配置的HDFS集群:一个主角色NN,一个辅助SNN,三个从角色DN
YARN集群:一个主角色RM,三个从角色NM
两个组件共同构成Hadoop集群
- 逻辑上分离
两个集群互相之间没有依赖、互不影响(启动互不影响) - 物理上在一起
某些角色进程往往部署在同一台物理服务器上 - MapReduce集群呢?
MapReduce是计算框架、代码层面的组件没有集群之说
二、Hadoop集群模式安装(Cluster mode)
思路
- 可以根据课程一步一步自己动手搭建Hadoop集群。
- 也可以直接使用虚拟机快照切换至搭建好的环境。
Hadoop源码编译

Step1:集群角色规划
- 角色规划的准则
根据软件工作特性和服务器硬件资源情况合理分配
比如依赖内存工作的NameNode是不是部署在大内存机器上? - 角色规划注意事项
资源上有抢夺冲突的,尽量不要部署在一起
工作上需要互相配合的。尽量部署在一起

Step2:服务器基础环境准备
打开软件 FinalShell
- 都发送 点击下面命令,输入命令,设置发送至全部会话
- 1、主机名(3台机器都验证一下)
vim /etc/hostname
[root@node3 ~]# cat /etc/hostname
node3.itcast.cn
您在 /var/spool/mail/root 中有新邮件
- 2、Hosts映射(3台机器验证)
cat /etc/hosts
[root@node3 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.88.151 node1 node1.itcast.cn
192.168.88.152 node2 node2.itcast.cn
192.168.88.153 node3 node3.itcast.cn
- 3、防火墙关闭(3台机器)
systemctl stop firewalld.service #关闭防火墙(当前)
systemctl disable firewalld.service #禁止防火墙开启自启(永久)
systemctl status firewalld.service #验证
[root@node3 ~]# systemctl stop firewalld.service
您在 /var/spool/mail/root 中有新邮件
[root@node3 ~]# systemctl disable firewalld.service
[root@node3 ~]# systemctl status firewalld.service #验证
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
- 4、ssh免密登录(node1执行->node1|node2|node3) 从一台机器访问另一台机器免密登录
ssh-keygen #4个回车 生成公钥、私钥
ssh-copy-id node1、ssh-copy-id node2、ssh-copy-id node3 #
验证:
ssh node1
exit
ssh node2
- 5、集群时间同步(3台机器)
yum -y install ntpdate
ntpdate ntp4.aliyun.com
ntpdate ntp5.aliyun.com
[root@node1 ~]# ntpdate ntp5.aliyun.com
7 May 21:25:29 ntpdate[11515]: adjust time server 203.107.6.88 offset -0.134916 sec
[root@node1 ~]# date
2022年 05月 07日 星期六 21:26:21 CST
您在 /var/spool/mail/root 中有新邮件
- 6、创建统一工作目录(3台机器)
mkdir -p /export/server/ #软件安装路径
mkdir -p /export/data/ #数据存储路径
mkdir -p /export/software/ #安装包存放路径
验证
[root@node1 ~]# ls /export/
data server software
Step3:上传安装包、解压安装包
- 上传、解压jdk安装包(node1)上传安装包到/export/server 解压
上传:打开下方目录,点击export/server,将课程资料“jdk-8u241-linux-x64.tar.gz”拖拉进去
查看:cd /export/server
[root@node1 ~]# cd /export/server
您在 /var/spool/mail/root 中有新邮件
[root@node1 server]# ll
总用量 189988
-rw-r--r-- 1 root root 194545143 5月 7 21:31 jdk-8u241-linux-x64.tar.gz
解压
tar -zxvf jdk-8u241-linux-x64.tar.gz
删除安装包
[root@node1 server]# rm -rf jdk-8u241-linux-x64.tar.gz
- 配置环境变量
vim /etc/profile
使用快捷键大G小o跳转到最后一行的下一行进行编辑
将下面的代码复制到最后
export JAVA_HOME=/export/server/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
shift +zz 保存退出(esc 命令格式)
重新加载环境变量文件,让其生效
source /etc/profile
- 验证
[root@node1 server]# java -version
java version "1.8.0_241"
Java(TM) SE Runtime Environment (build 1.8.0_241-b07)
Java HotSpot(TM) 64-Bit Server VM (build 25.241-b07, mixed mode)
您在 /var/spool/mail/root 中有新邮件
- 远程拷贝给其它两台机器
scp -r /export/server/jdk1.8.0_241/ root@node2:/export/server/
scp -r /export/server/jdk1.8.0_241/ root@node3:/export/server/
拷贝环境变量
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 475
475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









