







 本文详细介绍了树莓派CM4的硬件配置,包括四核Cortex-A72 CPU和ARMv8架构,强调了ARM64与X8664指令集的区别。文章深入探讨了ARM微架构,特别是Cortex-A72的流水线和向量计算能力,以及SIMD技术在Neon的实现。还提到了Neon的四种使用途径,包括汇编、内联汇编、向量化编译器和优化库。此外,讨论了内存特性,如原子操作、内存序和内存屏障,以及如何针对多核和并发优化代码。最后,提到了GCC的大小端编译选项、分支预测和CPU Cache的利用策略。
本文详细介绍了树莓派CM4的硬件配置,包括四核Cortex-A72 CPU和ARMv8架构,强调了ARM64与X8664指令集的区别。文章深入探讨了ARM微架构,特别是Cortex-A72的流水线和向量计算能力,以及SIMD技术在Neon的实现。还提到了Neon的四种使用途径,包括汇编、内联汇编、向量化编译器和优化库。此外,讨论了内存特性,如原子操作、内存序和内存屏障,以及如何针对多核和并发优化代码。最后,提到了GCC的大小端编译选项、分支预测和CPU Cache的利用策略。
目录
基础知识
树莓派CM4
| 说明 | |
|---|---|
| 开发板型号 | 树莓派module 4 |
| CPU型号 | BCM2711 |
| Processor | Quad-coreCortex-A72(ARM v8)64-bit SoC @ 1.5 GHz |
| CPU架构 | ARMv8-A architecture |
| Memory | Accesses up to 8GB LPDDR4-2400 SDRAM(depending on model) |
| Caches | 32 KB data + 48KB instruction L1 cache per core. 1MB L2 cache |
ARM64与X86 64区别
| ARM | X86 |
|---|---|
| 精简指令集(RISC) | 复杂指令集(CISC) |
| 一个生命周期执行一条指令 | 一个生命周期执行很复杂的指令 |
| 需要更大的内存 | 需要更多的寄存器 |
| 很多流水线执行 | 很少存在流水线执行 |
ARM微架构/内核/芯片
- ARM架构:ARM指令集,例如ARMv7、ARMv8;
- ARM内核:包括了寄存器组、指令集、总线等,例如Cortex-A57、Cortex-A72等;
- ARM芯片:指将ARM内核和各种外设集成到一个芯片上,例如博通BCM2711、高通801、麒麟950.
Cortex-A72
- 对称4核
- cache
- L1:48KB I-Cache,32KB D-Cache
- L2:512KB,1MB,2MB, or 4MB
- 主要模块:
- Instruction fetch
- Instruction decode
- Instruction dispatch
- Integer execute
- Load/Store unit
- L2 memory system
- Advanced SIMD and Floating-point unit
流水线
- 串行和并行两个阶段
- 并行阶段:8个pipeline并行执行
- 两条并行的整型计算
- 两条并行的向量计算
向量计算
SISD和SIMD
SISD:单指令对单个数据源上执行指定的操作;
SIMD:但指令对多个相同数据类型的数据执行相同的操作。
ARM向量计算技术演进:
- SIMD:ARMv6,32bit整型运算
- NEON:ARMv8,128bit浮点运算
- SVE2:ARMv9,2048bit浮点运算
ARMv8 Neon基础
ARMv8有32*128bit向量寄存器。
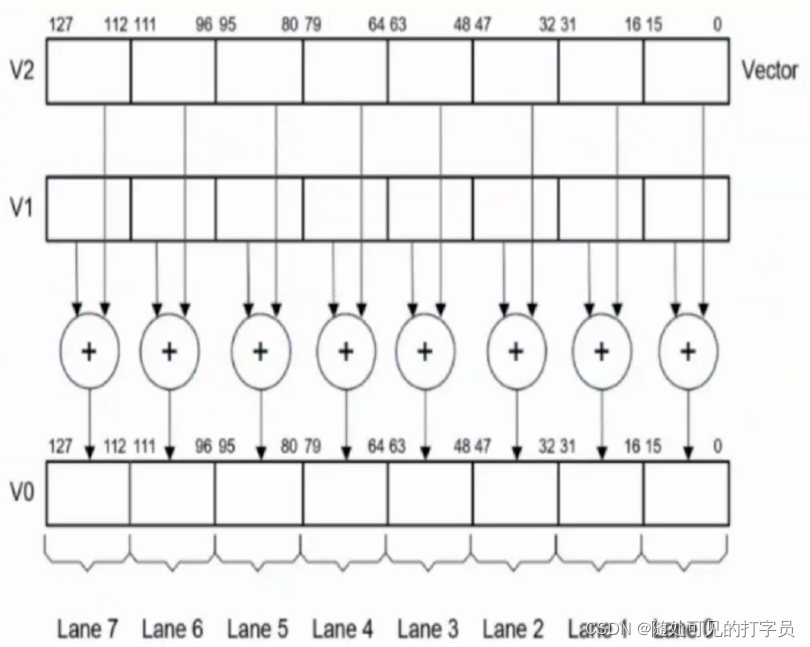
- Vector:128bit寄存器上同时包含相同类型的n个数据,称之为一个向量vector;
- Lane:每条Neno指令都会导致n个操作数并发执行,每个操作称之为Lane。
使用Neon的四种途径
Neon assembly
使用汇编语言编写程序。
优点:精准控制,性能高。
缺点:难写而且容易出错,不易移植。
Arm A64 Instruction Set Architecture
Neon intrinsics
汇编语言封装的C函数接口。
优点:
- 编写容易,不用复杂的汇编指令;
- 不依赖具体硬件,移植容易。
缺点:
- 不能精确控制使用的寄存器,有可能因为过度使用内存导致性能下降;
- 过于底层,没有更高级函数封装,如FFT等。
使用建议:
- 支持饱和计算等特色的函数;
- 要求处理的数据连续存储;
- 由于Load/store内存原因,性能有可能低于常规程序,所以必须做对比测试;
如性能较低,需要编译出汇编代码,进行分析。
Vectorizing compilers
在GCC中添加矢量化选项可以帮助C代码生成Neon代码。
To enable sutomatic vectorization in GCC, use the command line options:
-ftree-vectorize
-mfpu=neon
-mcpu to specify the core or architecture.
at optimization level-03 implies -ftree-vectorize
Neon optimized libraries
在代码中直接使用Neon优化过的库函数。

其他ARM高性能库:
- arm computelibrary:基础数学库,图像处理,计算机视觉,深度学习算法库等;
- NE10:提供数学库,图像处理,FFT等优化函数;
- 其他高性能的商业或开源的数学库
内存特性
原子操作
多核系统上,可以多个CPU核并行执行,即使实在单核系统上,也可以通过中断的方式模拟并行执行。但是内存只有一个,或者确切的说,某一个地址上的数据在内存里只有一个,当有可能出现多个线程对某一个内存地址上的数据同时进行操作。
由于这个操作一般会被翻译成CPU的多个指令,让这多个指令的执行不能被中断,或者同一个内存地址当当前线程在操作的时候其他CPU核不能访问,即使被中断了,或者被其他核访问了,对当前线程也没有任何影响的操作。
作用:全局计数器的实现、自旋锁、信号量等多线程同步。
无锁方法:通过采用原子操作,线程可以不受任何阻碍地自由运行。
弱内存序
内存序:CPU访问内存的顺序。
简单的例子如下:
a = 1
b = 2
c = a + b
强内存序的机器,就会按顺序执行:a=1,b=2,c=a+b,但是弱内存序的机器,有可能会执行成:b=2,a=1,c=a+b。
因为a=1和b=2之间先后没有什么逻辑依赖,先执行哪个,都不会导致结果有问题,编译器或者CPU就会自动的做一些优化。
根据现代CPU结构的设计,指令执行流水线的重新排序或者乱序执行可能会带来性能的提升。这就是弱内存序。
对于弱内存序的机器,如果代码是多线程的,就有可能会出现问题。
内存屏障
编译器内存屏障
保证了编译器变异出来的汇编指令,但是无法避免弱内存序的问题。
CPU内存屏障
- 读内存屏障:本线程所有后续的读操作均在本条指令以后执行;
- 写内存屏障:本线程所有后续的写操作均在本条指令以后执行;
- 读写内存屏障
X86上的的CPU内存屏障:
- Ifence:读屏障
- sfence:写屏障
- mfence:读写屏障
ARM上的CPU内存屏障:
- DMB:数据内存屏障
- DSB:数据同步屏障
- ISB:指令集同步屏障
编程建议
- C和C++多线程编程,如果不了解弱内存序的知识,很可能产生一些难以定位的bug;
- 如果一些软件一开始只支持了X86,并且使用了底层的原子操作,如果想要软件兼容ARM,就要对这些原子操作汇编指令等等进行对应的移植和优化;
- 有时候有些软件的内存序使用过于严格,也需要进行优化,会对软件的性能有一定的提升,例如一些mysql上的优化工作,再如有些原子变量的自增,并不需要依赖上下文,就可以不需要严格的内存屏障语义。
其他
需要注意的问题
- 本机的可执行程序需要与本机的CPU架构相统一
- 多台主机使用socket通讯
- 发送方:数据转换成大端模式(网络字节序)
- 接收方:数据转换成与本接收主机一致的字节序
网络字节序和主机字节序可能不一致,需要转换。
GCC大小端编译选项
- 小端模式(默认):-EL
- 大端模式:-EB
流水线分支预测
优化建议:
- 有序数据
- 使用likely和unlikely:用于修饰if/else if分支,表示该分支的条件更有可能被/不被满足
高效利用CPU的Cache
优化建议:
- 数据块大小是cache_line的整数倍
- 多层循环嵌套把小数量级的循环放在最外面,减少CPU环境变量切换次数
# 查看cache_line方法
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
常用查看cache命中率工具:
- cachestat:提供了整个操作系统缓存的读写命中情况
- cachetop:提供了每个进程的缓存命中情况
ARM并发负载优化
优化建议:
- 进程数量是CPU核数的N-1
- 程序的线程总数量不要超过(N-1)*8
- 解耦线程间的读写操作并发
- 增大进程间同类数据的读写操作
- 减小上下文切换消耗时间
- CPU核较多时,建议进行绑核运行
加密与CRC
优化建议:
- 硬件上支持AES加解密(AESD,AESE,AESIMC,AESMC)、SHA1和SHA256指令
- 硬件上支持CRC32,CRC32C指令



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











