







一、使用方式
一般,我们按照如下形式进行交叉熵损失的计算:
- crossentropyloss=nn.CrossEntropyLoss()
- crossentropyloss_output=crossentropyloss(logits,labels)
需要注意的是:
- 上述的参数labels 不是one-hot形式,而是原始的数字标签(一维)。
- nn.CrossEntropyLoss()默认对batch中的n个样本的交叉损失求均值。 一般来说,我们都是采用默认的这种方式,即没有reduction参数。
- 如果出现了reduction参数,即 nn.CrossEntropyLoss(reduction=‘none’),则直接返回该批数据中的n个样本的交叉熵损失,不做任何处理。
- 如果reduction参数为sum,即 nn.CrossEntropyLoss(reduction=‘sum’),则表示对batch中的n个样本的交叉熵损失求和。
二、计算过程
nn.CrossEntropyLoss()交叉熵损失公式 首先对logits进行softmax处理, 然后 再根据真实标签对应的logits分量进行交叉熵损失的计算,最后 默认返回该批样本损失的均值。
三、实例讲解
import torch
import torch.nn as nn
import numpy as np
import math
# 使用nn.CrossEntropyLoss()函数求交叉熵损失
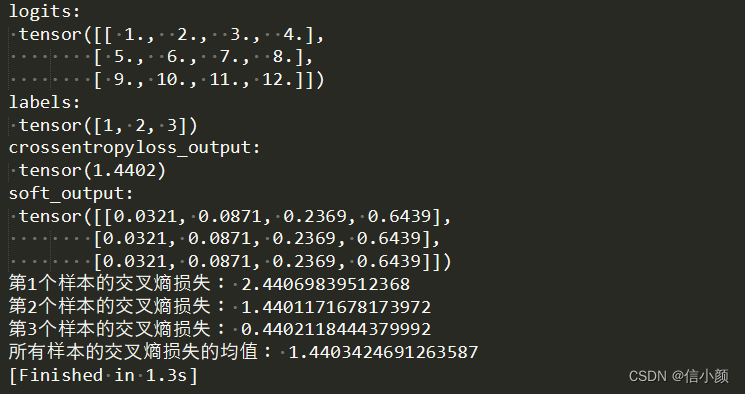
a = np.arange(1,13).reshape(3,4)
b = torch.from_numpy(a)
logits = b.float()
print('logits:\n',logits)
# print(logits.shape) # torch.Size([3, 4])
labels = torch.tensor([1,2,3])
print('labels:\n',labels)
# 注意:reduction参数如果为sum,则表示对batch中的n个样本的交叉熵损失求和。
# reduction参数如果为none,则直接返回该批数据中的n个样本的交叉熵损失,不做任何处理。
# 如果没有reduction参数,则默认对batch中的n个样本的交叉损失求均值。
crossentropyloss=nn.CrossEntropyLoss() # tensor(1.4402)
# crossentropyloss=nn.CrossEntropyLoss(reduction='none') # tensor([2.4402, 1.4402, 0.4402])
# crossentropyloss=nn.CrossEntropyLoss(reduction='sum') # tensor(4.3206)
crossentropyloss_output=crossentropyloss(logits,labels)
print('crossentropyloss_output:\n',crossentropyloss_output)
# 验证交叉熵的计算过程
softmax_func=nn.Softmax(dim=1)
# 关于softmax函数的具体使用可以参考链接 https://zhuanlan.zhihu.com/p/397695655
soft_output=softmax_func(logits)
print('soft_output:\n',soft_output)
print("第1个样本的交叉熵损失:",-math.log(0.0871))
print("第2个样本的交叉熵损失:",-math.log(0.2369))
print("第3个样本的交叉熵损失:",-math.log(0.6439))
print("所有样本的交叉熵损失的均值:",(-math.log(0.0871)-math.log(0.2369)-math.log(0.6439))/3)















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











