







论文地址:https://arxiv.org/abs/2307.08621
目录
2.2Gated Multi-Scale Retention
2.3Overall Architecture of Retention Networks
2.4Relation to and Differences from Previous Methods
3.2Comparisons with Transformer
3.5Comparison with Transformer Variants

Abstract
- 翻译
在这项工作中,我们提出了保留网络(RETNET)作为大型语言模型的基础架构,同时实现训练并行性、低成本推理和良好性能。我们从理论上推导了循环和注意力之间的关系。然后,我们为序列建模提出了保留机制,支持三种计算范式,即并行、递归和分块递归。具体而言,并行表示允许进行训练并行性。递归表示使得低成本的O(1)推理成为可能,这提高了解码吞吐量、延迟和GPU内存,而不牺牲性能。分块递归表示有助于使用线性复杂性进行高效的长序列建模,其中每个分块在并行编码的同时递归地总结这些分块。在语言建模的实验结果表明,RETNET取得了有利的扩展结果,实现了并行训练、低成本部署和高效推理。这些引人注目的特性使RETNET成为大型语言模型的Transformer的强有力的继任者。
- 精读
RetNet弥补神经网络中并行性差,推理成本高和性能较差的缺点,通过推导NN中的循环与Attention之间的关系提出保留机制,以支持
1.并行:允许训练并行进行
2.递归:interface成本为o(1),在不牺牲性能的前提下,提高decoder吞吐量,延迟和降低GPU内存
3.分块递归:有助于使用线性复杂性口模型高效的长建模
三种计算范式
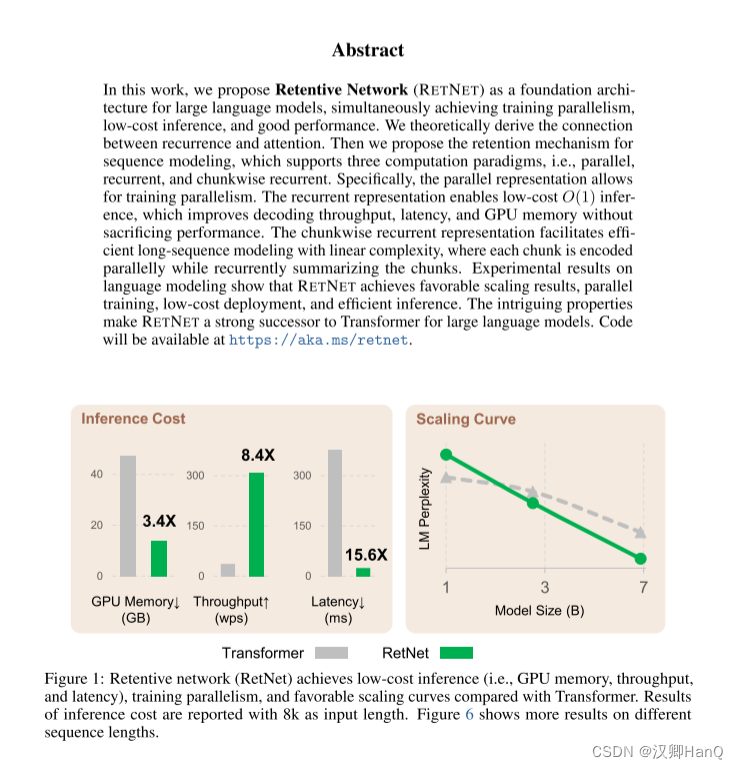
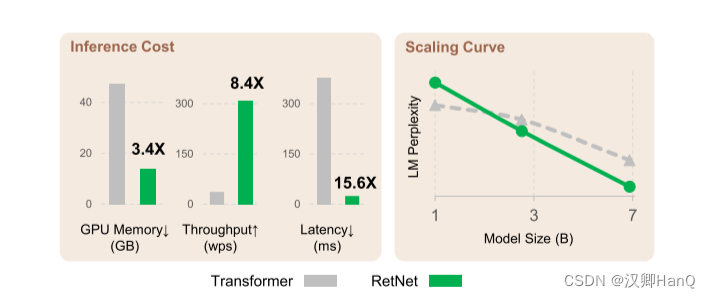
通过上述改进,RetNet较Transformer相比,在8k的输入序列长度,其显存下降3.4倍,吞吐量提高了8.4倍,延迟下降了15.6倍。当随着数据下降,模型LM Perplexity比Transformer更低
一.Introduction

- 翻译
Transformer已成为大型语言模型的事实标准架构,最初是为了克服递归模型的序列训练问题而提出的。然而,Transformer的训练并行性是以低效的推理为代价的,这是因为每个步骤的O(N)复杂度和受内存限制的键值缓存,这使得Transformer在部署方面不太友好。不断增长的序列长度会增加GPU内存消耗,同时也会增加延迟,降低推理速度。
下一代架构的开发仍在继续,旨在保持训练并行性和transformer 的竞争性能,同时有高效的 O(1)推理。同时实现上述目标具有挑战性,即图 2 所示的所谓的“不可能的三角形”。
有三个主要的研究方向。首先,线性化注意力近似标准注意力分数exp(q · k)与核ϕ(q) · ϕ(k),以便将自回归推理重写为循环形式。然而,这种模型的建模能力和性能都不及Transformer,从而阻碍了该方法的普及。第二个方向回归到递归模型以实现高效推理,但会牺牲训练并行性。作为补救,使用元素级操作符进行加速,但这会损害表示能力和性能。第三个研究方向探索将注意力替换为其他机制,如S4以及其变体。然而,之前的研究都无法突破不可能的三角形,因此与Transformer相比没有明确的胜者。
在这项工作中,我们提出了保留网络(RetNet),同时实现了低成本推理、高效的长序列建模、与Transformer相媲美的性能以及并行模型训练。具体而言,我们引入了多尺度的保留机制来替代多头注意力,该机制具有并行、递归和分块递归表示三种计算范式。首先,通过并行表示,我们实现了充分利用GPU设备的训练并行性。其次,递归表示使得在内存和计算方面都能实现高效的O(1)推理。部署成本和延迟得以显著降低,此外,实现过程大大简化,无需使用键值缓存技巧。第三,分块递归表示能够进行高效的长序列建模。我们通过并行编码每个局部块来提高计算速度,同时通过递归编码全局块来节省GPU内存。
我们进行了大量实验,将RetNet与Transformer及其变体进行了比较。在语言建模的实验结果中,RetNet在规模曲线和上下文学习方面始终具有竞争力。此外,RetNet的推理成本与序列长度无关。对于一个7B模型和8k序列长度,RetNet的解码速度比使用键值缓存的Transformer快8.4倍,并节省了70%的内存。在训练过程中,RetNet的内存节省和加速效果也比标准Transformer以及高度优化的FlashAttention [DFE+22]都要好,分别达到25-50%和7倍。此外,RetNet的推理延迟不受批量大小的影响,可以实现巨大的吞吐量。这些引人注目的特性使得RetNet成为大型语言模型的Transformer的有力继任者。
- 精读
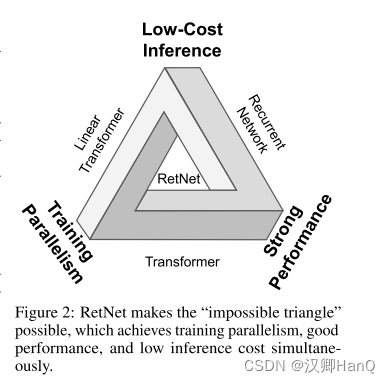
在神经网络上,有一个不可能三角,即低成本推理,并行性和强大的扩展能力,以往的模型架构只能满足三者中的其二。例如Transformer其并行处理机制是以低效推理为代价的,每个步骤的复杂度为O(N);Transformer是内存密集型模型,序列越长,占用的内存越多。
然而,RetNet打破了这个不可能三角
RetNet引入多尺度保留Retentive代替自注意力机制,通过Retentive中三种计算范式来实现不可能三角:
1.并行:赋予训练并行性以充分利用GPU设备。
2.循环:在内存和计算方面实现interface O(1) 在没有键值缓冲下,显著降低部署成本和延迟。
3.分块递归:对每个局部模块并行编码提高计算速度,同时对全局进行递归编码以节省GPU内存
二.Retentive Networks

- 翻译
Retentive network (RetNet)由 L 个相同的块堆叠而成,其布局与 Transformer [VSP+17]类似(即剩余连接和 pre-LayerNorm)。每个RetNet 块包含两个模块:多尺度保持(MSR)模块和前馈网络(FFN)模块。我们将在下面的章节中介绍MSR模块。给定一个输入序列x = x1···x|x|,RetNet 以自回归的方式对序列进行编码。输入向量{xi}i=1 |x|首先被打包成X0 = [x1,···,x|x|]∈R|x×dmodel,其中dmodel 为隐维。然后我们计算上下文化的向量表示
2.1Retention


- 翻译
在本节中,我们介绍了一种具有递归和并行性双重形式的保留机制。因此,我们可以以并行方式训练模型,同时进行递归地推理。给定输入X ∈ R|x|×dmodel,我们将其投影到一维函数v(n) = Xn · wV。考虑一个序列建模问题,通过状态sn将v(n)映射到o(n)。为简单起见,记vn和on分别表示v(n)和o(n)。我们以递归方式表达这种映射:
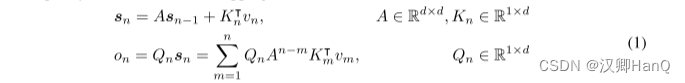
我们在这里映射vn对状态向量sn,然后实现线性变换,对序列信息进行递归编码。
接下来,我们做投影Qn, kn 内容感知:

我们对矩阵A进行对角化,得到A = Λ(γeiθ)Λ−1,其中γ,θ ∈ Rd。然后我们得到An−m = Λ(γeiθ)n−mΛ−1。通过将Λ吸收到WQ和WK中,我们可以将方程(1)重新写成:
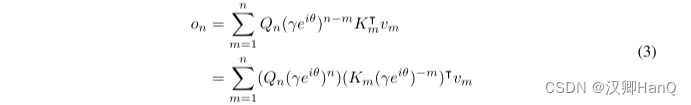
其中,Qn, Km称为xPos [SDP+22],即为Transformer 提出的相对位置嵌入。进一步将γ化简为标量,式(3)为:

其中✝为共轭转置,该公式很容易在训练中并行化。
综上所述,我们从(1)循环建模开始,直至推导(4)的并行表达式.我们将原始映射v(n)->o(n)视为向量,得到retention机制如下:
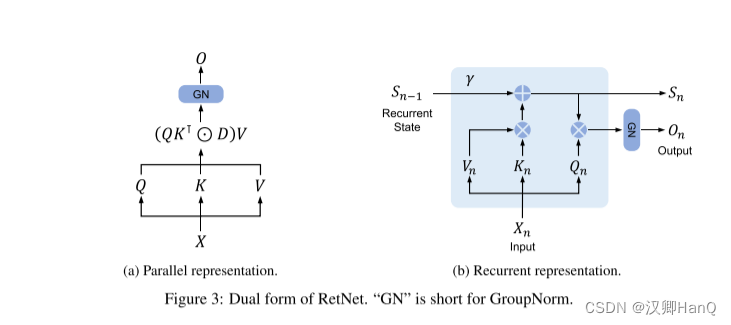
retention的并行表示 如图3a所示,保留层被定义为:
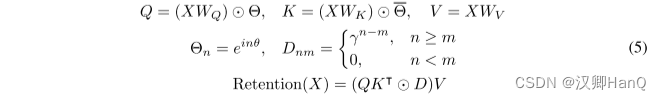
其中,θ^-是θ的共轭复数,D ∈ R|x|×|x| 将因果屏蔽和相对距离的指数衰减结合为一个矩阵。类似于自注意力,这种并行表示使我们能够有效地使用GPU训练模型。
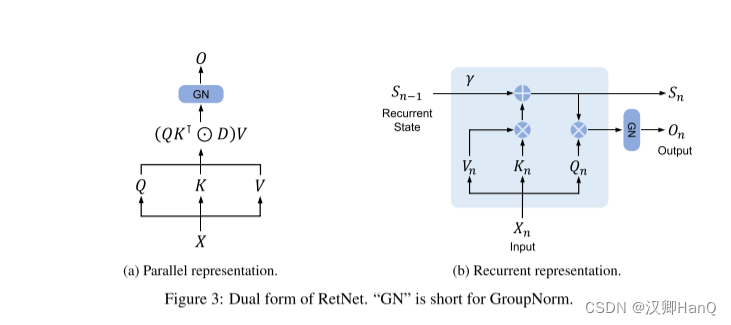
如图3b所示,所提出的机制也可以写成递归神经网络(rnn),这有利于推理。对于第n次时间步,我们递归地得到输出为:
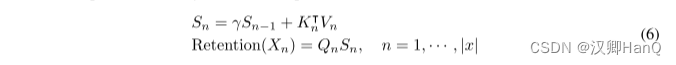
式中,Q、K、V、γ与式(5)相同。
并行表示和循环表示的混合形式可以加速训练,特别是对长序列的训练。我们把输入序列分成块。在每个 chunk内,我们按照并行表示(式(5))进行计算。而跨块信息则按照循环表示进行传递(式(6))。具体来说,设 B表示块长度。我们通过以下方法计算第 i 块的保留输出:
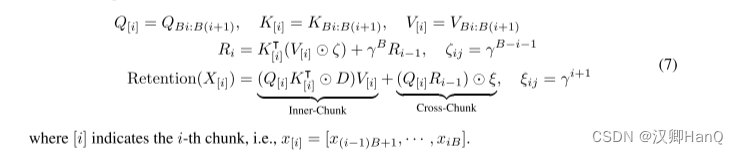
- 精读
2.2Gated Multi-Scale Retention

- 翻译
在每个层中,我们使用h = dmodel/d 的保留头(retention heads),其中d是头的维度。这些头使用不同的参数矩阵WQ、WK、WV ∈ Rd×d。此外,多尺度保留(MSR)为每个头分配不同的γ。为简单起见,我们在不同层之间设置相同的γ,并保持其不变。此外,我们添加了一个swish门(swish gate)[HG16,RZL17]以增加保留层的非线性。形式上,给定输入X,我们将层定义为:
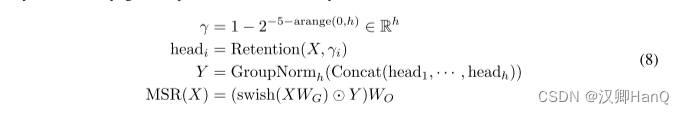
其中WG, WO∈Rdmodel×dmodel 是可学习参数,GroupNorm [WH18]对每个头的输出进行归一化,遵循在[SPP+19]。注意,头部使用多个γ 尺度,这导致不同的方差统计。所以我们分别归一化头部的输出。
我们利用 GroupNorm的尺度不变性质来提高保留层的数值精度。具体而言,在GroupNorm中乘以一个标量值不会影响输出和反向梯度,即GroupNorm(α ∗ headi) = GroupNorm(headi)。我们在公式(5)中实现了三个归一化因子。首先,我们将QK⊺归一化为QK⊺/ √ d。其次,我们用D˜nm = Dnm / √Pn i=1 Dni代替D。第三,设R表示保留分数,即R = QK⊺ ⊙ D,我们将其归一化为R˜nm = Rnm /max(| Pn i=1 Rni|,1)。然后保留输出变为Retention(X) = ˜RV。上述技巧不会影响最终结果,同时稳定了前向和后向传递的数值流动,这是由于尺度不变特性。
- 精读
2.3Overall Architecture of Retention Networks
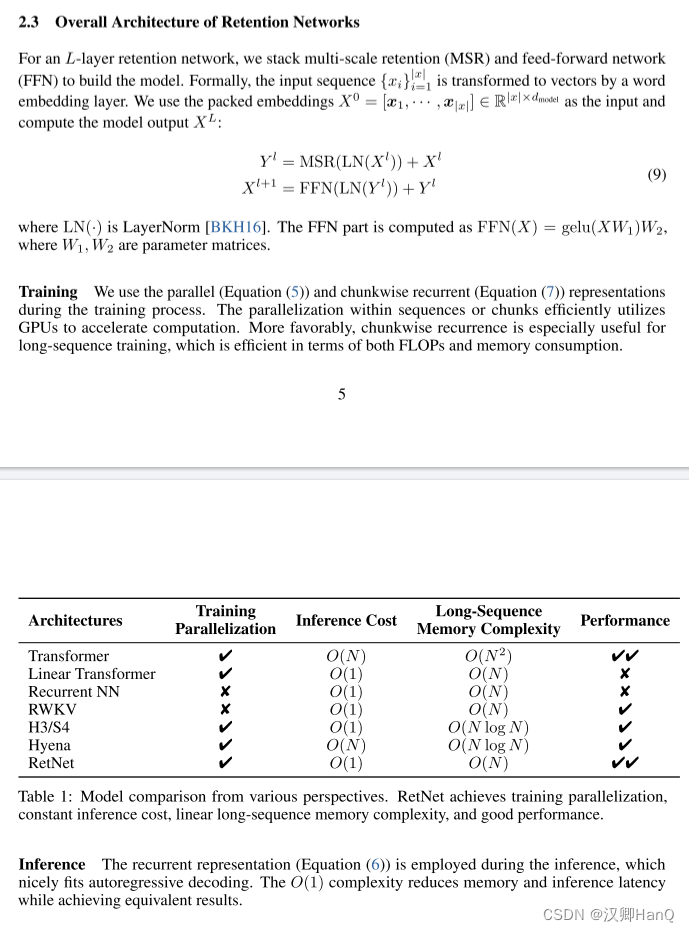
- 翻译
对于一个L层的保留网络,我们堆叠多尺度保留(MSR)和前馈网络(FFN)来构建模型。形式上,输入序列{xi}|x| i=1通过一个词嵌入层转化为向量。我们使用打包的嵌入X0 = [x1, · · · , x|x|] ∈ R|x|×dmodel 计算模型输出XL:
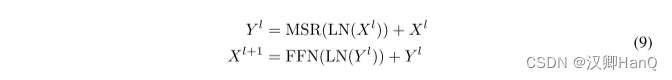
其中,LN为LayerNorm,FNN计算公式为FFN(X) = gelu(XW1) w2,其中W1, w2 是参数矩阵。
训练过程中我们使用并行表示(公式(5))和分块递归表示(公式(7))。在序列或分块内部进行的并行计算充分利用了GPU来加速计算。而且,分块递归特别适用于长序列的训练,这在FLOP和内存消耗方面都是高效的。
推理过程中我们使用递归表示(公式(6)),这非常适用于自回归解码。O(1)的复杂度降低了内存占用和推理延迟,同时实现了等效的结果。
- 精读
2.4Relation to and Differences from Previous Methods


- 翻译
表1从各个角度比较了RetNet与以前的方法。比较结果呼应了图2中呈现的“不可能三角形”。此外,由于分块递归表示,RetNet对于长序列具有线性的内存复杂度。我们还总结了与具体方法的比较如下:
Transformer:The parallel representation of retention与Transformers [VSP+17]有着相似的思想。最相关的Transformer变体是Lex Transformer [SDP+22],它实现了xPos作为位置嵌入。如公式(3)所述,保留的推导与xPos是相符的。与注意力相比,保留去除了softmax,并启用了递归公式,这在推理方面有着显著的优势。
S4:与公式(2)不同,如果Qn和Kn不考虑内容,该公式可以退化为S4。
Linear Attention:这些变体通常使用各种核函数

来替代softmax函数。然而,线性注意力在有效编码位置信息方面存在困难,使模型的性能较差。此外,我们重新审视了序列建模,而不是旨在近似softmax。
AFT/RWKV:无注意力Transformer(AFT)将点积注意力简化为逐元素操作,并将softmax移到键向量中。RWKV使用指数衰减替换了AFT的位置嵌入,并在训练和推理过程中递归运行模型。相比之下,保留保留了高维状态以编码序列信息,这有助于表达能力和更好的性能。
xPos/RoPE:与为Transformers提出的相对位置嵌入方法相比,公式(3)呈现了与xPos [SDP+22]和RoPE [SLP+21]类似的公式。
Sub-LayerNorm:如公式(8)所示,保留层使用Sub-LayerNorm [WMH+22]来对输出进行归一化。由于多尺度建模导致头部之间的方差不同,我们用GroupNorm替换了原始的LayerNorm。
- 精读
三.Experiments

我们进行语言建模实验来评估RetNet。我们对提议进行评估具有各种基准的体系结构,例如,语言建模性能,以及零/少命中率学习下游的任务。此外,在训练和推理方面,我们比较速度和记忆力消耗和延迟。
3.1Setup

- 翻译
参数分配:我们重新分配了MSR和FFN中的参数,以进行公平比较。在这里,我们用d来表示dmodel。在Transformers中,自注意力层中大约有4d2个参数,其中WQ、WK、WV、WO ∈ Rd×d,以及FFN层中有8d2个参数,其中中间维度为4d。相比之下,RetNet在保留层中有8d2个参数,其中WQ、WK ∈ Rd×d,WG、WV ∈ Rd×2d,WO ∈ R2d×d。请注意,V的头维度是Q和K的两倍。扩展的维度通过WO投影回d。为了保持与Transformer相同的参数数量,RetNet中的FFN中间维度为2d。同时,我们在实验中将头维度设置为256,即查询和键为256,值为512。为了公平比较,我们在不同的模型尺寸中保持γ相同,其中γ = 1 − elinspace(log 1/32,log 1/512,h) ∈ Rh,而不是公式(8)中的默认值。
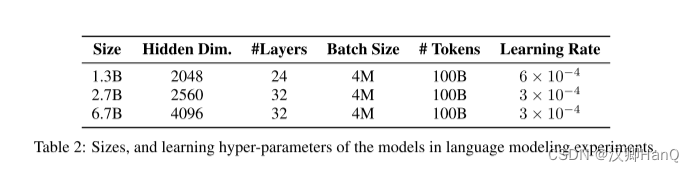
语言模型训练:如表2所示,我们从头开始训练不同规模的语言模型(即1.3B、2.7B和6.7B)。训练语料库是The Pile [GBB+20]、C4 [DMI+21]和The Stack [KLBA+22]的精选汇编。我们在序列的开头添加了<bos>标记以表示序列的开始。训练的批次大小为4M个标记,最大长度为2048。我们用100B个标记(即25k步)来训练模型。我们使用AdamW [LH19]优化器,其中β1 = 0.9,β2 = 0.98,并且权重衰减设置为0.05。预热步数为375,采用线性学习率衰减。参数的初始化遵循DeepNet [WMD+22]以确保训练稳定。实现基于TorchScale [MWH+22]。我们使用512个AMD MI200 GPU来训练模型。
- 精读
3.2Comparisons with Transformer

- 翻译
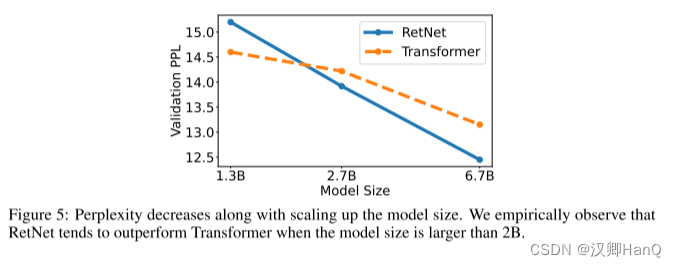
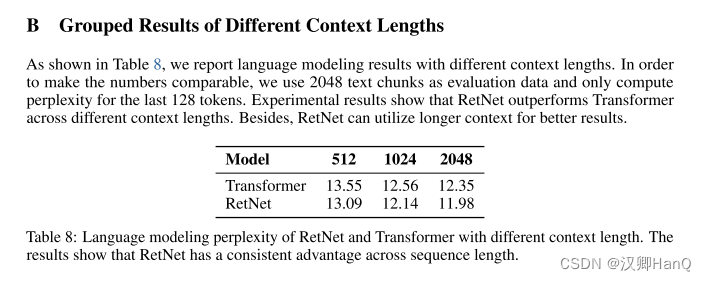
语言模型:如图5所示,我们在验证集上报告了基于Transformer和RetNet的语言模型的困惑度。我们展示了三个模型大小的规模曲线,即1.3B、2.7B和6.7B。RetNet在与Transformer相当的结果上取得了可比的效果。更重要的是,结果表明RetNet在规模扩展方面更有优势。除了性能外,我们的实验中RetNet的训练非常稳定。实验结果表明,对于大型语言模型,RetNet是Transformer的有力竞争者。经验证实,当模型大小大于2B时,RetNet开始胜过Transformer。我们还在附录B中总结了不同上下文长度的语言建模结果。
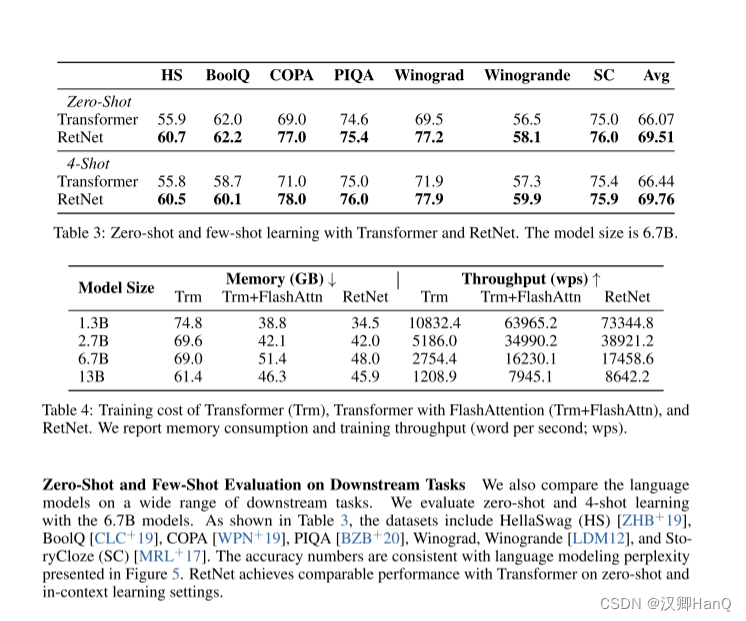
各种下游任务的语言模型:我们还在广泛的下游任务上比较了语言模型。我们使用6.7B模型进行零射和4射学习的评估。如表3所示,数据集包括HellaSwag(HS)[ZHB+19]、BoolQ [CLC+19]、COPA [WPN+19]、PIQA [BZB+20]、Winograd、Winogrande [LDM12]和StoryCloze(SC)[MRL+17]。准确度数字与图5中的语言建模困惑度保持一致。在零射和上下文学习设置中,RetNet在性能上与Transformer达到了可比的水平。
- 精读
3.3Training Cost

- 翻译
如表4所示,我们比较了Transformer和RetNet的训练速度和内存消耗,其中训练序列长度为8192。我们还与FlashAttention [DFE+22]进行了比较,后者通过重新计算和内核融合来提高速度并减少GPU内存IO。相比之下,我们使用原始的PyTorch代码来实现RetNet,并将内核融合或类似FlashAttention的加速留给未来的工作。我们使用公式(7)中的分块递归保留表示。分块大小设置为512。我们使用八个Nvidia A100-80GB GPU进行评估,因为FlashAttention在A100上进行了高度优化。6.7B和13B模型启用了张量并行。
实验结果显示,与Transformer相比,RetNet在训练过程中具有更高的内存效率和吞吐量。即使与FlashAttention相比,RetNet在速度和内存成本方面仍然具有竞争力。此外,由于不依赖特定的内核,可以在其他平台上高效地训练RetNet。例如,我们在一个AMD MI200集群上训练了RetNet模型,具有不错的吞吐量。值得注意的是,RetNet有潜力通过先进的实现,比如内核融合,进一步降低成本。
- 精读
3.4Inference Cost

- 翻译
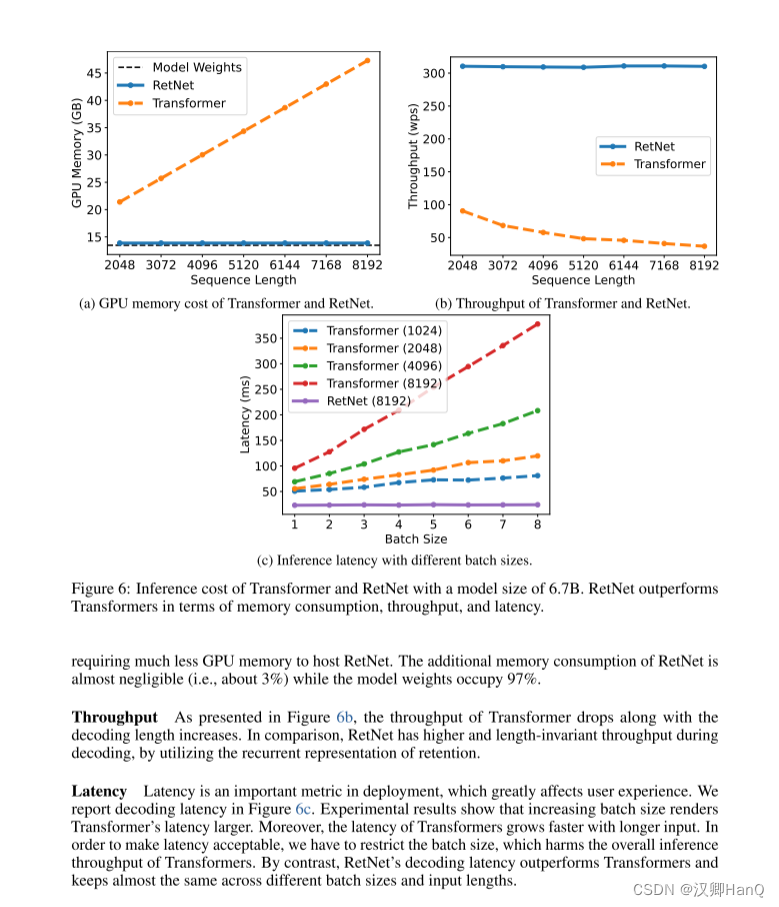
如图6所示,我们在推理过程中比较Transformer 和RetNet 的内存成本、吞吐量和延迟。变压器重用以前解码令牌的KV缓存。RetNet 使用如式(6)所示的循环表示。我们在实验中对 A100-80GB GPU 上的 6.7B 模型进行了评估。图 6 显示RetNet 在推理成本方面优于Transformer。
显存:如图6a所示,由于KV缓存,Transformer的内存成本呈线性增加。相比之下,RetNet的内存消耗即使在长序列情况下也保持一致,因此,托管RetNet所需的GPU内存要少得多。RetNet的额外内存消耗几乎可以忽略不计(即约为3%),而模型权重占据了97%。
吞吐量:如图6b所示,随着解码长度的增加,Transformer的吞吐量下降。相比之下,通过利用保留的递归表示,RetNet在解码过程中具有更高且长度不变的吞吐量。
延迟部署:延迟是部署中的一个重要指标,它极大地影响用户体验。我们在图6c中报告了解码延迟。实验结果显示,增加批次大小会使Transformer的延迟变大。此外,Transformer的延迟在输入更长的情况下增长得更快。为了使延迟可接受,我们不得不限制批次大小这会损害Transformer的整体推理吞吐量。相比之下,RetNet的解码延迟优于Transformer,并且在不同的批次大小和输入长度之间基本保持一致。
- 精读
3.5Comparison with Transformer Variants


- 翻译
除了Transformer,我们还将RetNet与各种高效的Transformer变体进行了比较,包括Linear Transformer [KVPF20]、RWKV [PAA+23]、H3 [DFS+22]和Hyena [PMN+23]。所有模型都有200M个参数,具有16层和1024的隐藏维度。对于H3,我们将头维度设置为8。对于RWKV,我们使用TimeMix模块来替代自注意力层,同时保持FFN层与其他模型保持一致,以进行公平比较。我们以0.5M个标记的批次大小进行了10k步的训练。大多数超参数和训练语料库与第3.1节保持一致。
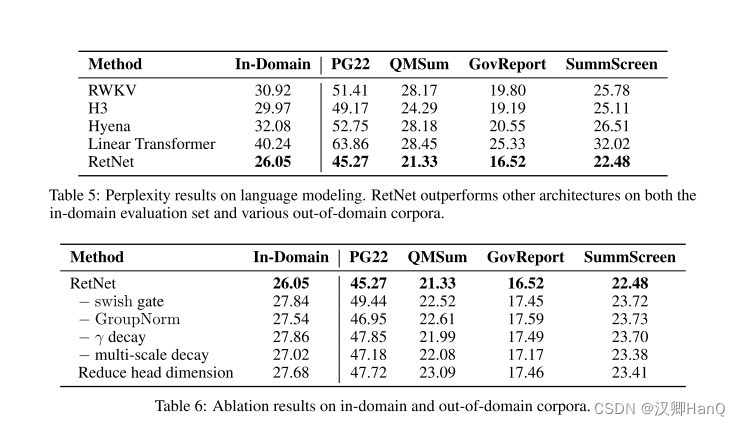
表5报告了在领域内验证集和其他领域外语料库(例如,Project Gutenberg 2019-2022(PG22)[SDP+22]、QMSum [ZYY+21]、GovReport [HCP+21]、SummScreen [CCWG21,SSI+22])上的困惑度数字。总体而言,RetNet在不同的数据集上表现优于先前的方法。RetNet不仅在领域内语料库上获得更好的评估结果,还在一些领域外的数据集上获得更低的困惑度。这种有利的表现使得RetNet成为Transformer的强有力继任者,除了显著降低成本的好处(第3.3和3.4节)。
此外,我们还讨论了所比较方法的训练和推理效率。令d表示隐藏维度,n表示序列长度。对于训练,RWKV的令牌混合复杂度为O(dn),而Hyena的复杂度为O(dn log n),并通过快速傅里叶变换进行加速。上述两种方法通过使用逐元素运算符来降低建模容量以换取训练FLOPS。与此相比,基于块的递归表示为O(dn(b + h)),其中b是块大小,h是头维度,通常设置b = 512,h = 256。对于大模型大小(即更大的d)或序列长度,额外的b + h对性能影响微乎其微。因此,RetNet的训练非常高效,而不会牺牲建模性能。对于推理,在比较的高效架构中,Hyena的复杂度(即每步O(n))与Transformer相同,而其他架构可以实现O(1)解码。
- 精读
3.6Ablation Studies


- 翻译
我们去掉了RetNet 的各种设计选择,并在表6中报告了语言建模结果。评估设置和指标与章节3.5相同。
Architecture:我们分析了方程(8)中的Swish门和GroupNorm。表6显示,上述两个组件可以提高最终的性能。首先,门控模块对于增强非线性和提高模型能力至关重要。需要注意的是,我们在去除门控后使用与Transformer相同的参数分配。其次,保留在保留层中的分组归一化可以平衡多头输出的方差,从而提高训练稳定性和语言建模结果。
Multi-Scale Decay:方程(8)显示,我们使用不同的γ作为保留头部的衰减率。在消融研究中,我们研究了去除γ衰减(即“-γ衰减”)和在所有头部应用相同的衰减率(即“-多尺度衰减”)。具体来说,去除γ衰减等同于γ = 1。在第二种情况下,我们将所有头部的γ设置为127/128。表6表明,无论是衰减机制还是使用多个衰减率,都可以提高语言建模性能。
Head Dimension:从方程(1)的递归角度来看,头部维度暗示了隐藏状态的内存容量。在消融研究中,我们将默认的头部维度从256降低到64,即查询和键使用64,值使用128。我们保持隐藏维度dmodel不变,因此头部数目增加。表6中的实验结果显示,较大的头部维度可以获得更好的性能。
- 精读
四.Conclusion

在本研究中,我们提出了用于序列建模的保留网络(RetNet),它能够实现各种表示,即并行、递归和分块递归。相比于Transformer,RetNet在推理效率(内存、速度和延迟方面)、有利的训练并行化以及竞争性能方面表现出色。上述优势使得RetNet成为大型语言模型的理想继任者,特别是考虑到O(1)推理复杂度带来的部署优势。在未来,我们计划在模型大小[CDH+22]和训练步骤方面扩展RetNet。此外,保留可以通过压缩长期记忆有效地与结构化提示[HSD+22b]配合使用。我们还将使用RetNet作为骨干架构来训练多模态大型语言模型[HSD+22a,HDW+23,PWD+23]。此外,我们有兴趣在各种边缘设备上部署RetNet模型,如手机等。















 1056
1056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









