







Retentive Network: A Successor to Transformer for Large Language Models
论文:Retentive Network: A Successor to Transformer for Large Language Models (arxiv.org)
作者:Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, Furu Wei
时间:2023
地址:https://aka.ms/retnet
这是由微软和清华一起发布的论文,在这篇文章中,作者提出了一个代替transformer的基础架构:retentive network,该架构可以同时达到 training parallelism, low-cost inference, good performance. 并从理论上推导出了recurrence与attention之间的联系,这种retentive机制在序列模型中有三种计算范式:parallel, recurrent, and chunkwise recurrent. 其中并行表示允许训练并行性。循环表示可以实现低成本的O (1)推理,从而在不牺牲性能的情况下提高了解码需要的吞吐量、并降低了延迟和GPU内存。块级递归表示促进了具有线性复杂度的高效长序列建模,其中每个块都被并行编码,同时递归地总结块。
一、完整代码
https://github.com/microsoft/unilm/tree/master/retnet
二、论文解读
2.1 介绍
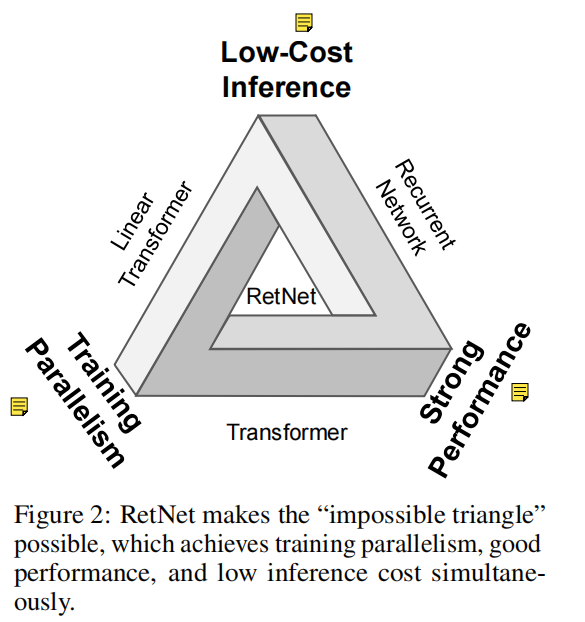
论文开头提出了一个不可能三角,分别是training parallelism, low-cost inference, good performance;以往的架构只能获得三种优势中的两种,而RetNet可以全部获得;
首先是Linear Transformer :其主要处理的方式是对k和v进行处理,例如[Linformer]论文实现:Linformer: Self-Attention with Linear Complexity_linformer网络结构-CSDN博客是通过证明self-attention是一个低秩矩阵来减少k和v的维度进而得到线性复杂度的效果,即low-cost inference,但是其降低了Transformer的效果;
第二个是Recurrent Network,随着不断的优化,其最大的缺点就是不能并行训练;
最后一个是Transformer,其最大的不足便是复杂度是 O ( n 2 ) O(n^2) O(n2),这导致序列长度的增加增加了GPU内存消耗和延迟,并降低了推理速度。
这里论文提出的RetNet,可以同时获得training parallelism, low-cost inference, good performance三种优秀的性质,其通过采用一种multi-scale retention 机制去替换multi-head attention
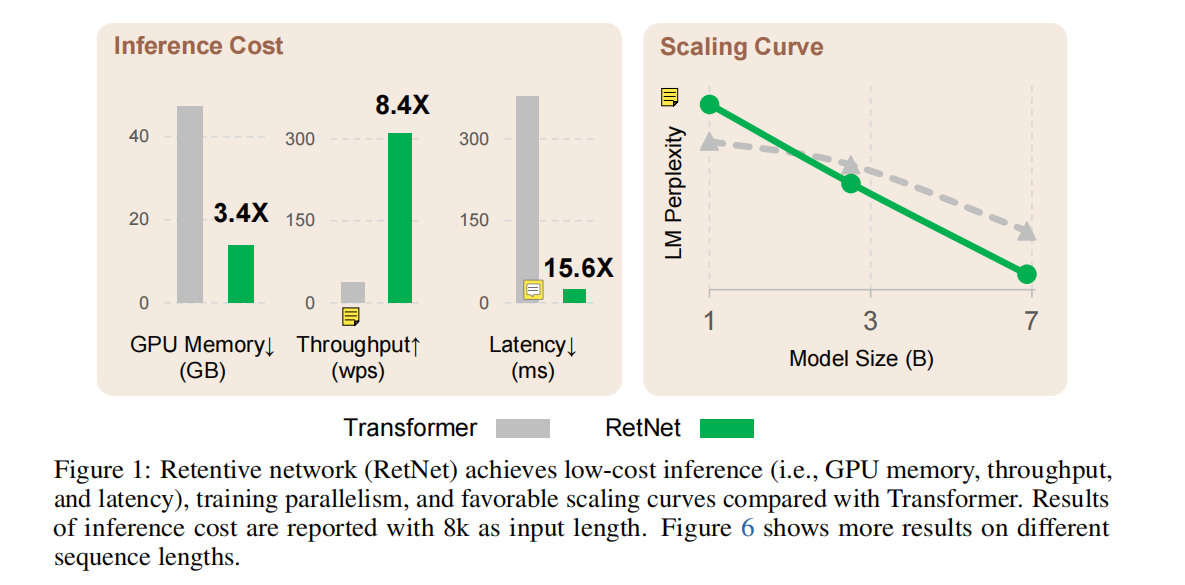
作者通过实验表明,RetNet在scaling curves序列长度和in-context learning上下文学习方面相较于Transformer是持续超过的状态,同时,RetNet的inference cost 是 O ( 1 ) O(1) O(1) ;对于7B参数量和8k序列长度的语言模型,RetNet的解码速度比具有键值缓存的Transformer快8.4×,节省了70%的内存。在训练过程中,RetNet还比Transformer节省了25-50%的内存和7×的加速,并且在highly-optimized FlashAttention方面具有优势。此外,RetNet的推理延迟对批处理大小不敏感,允许巨大的吞吐量,认为是遥遥领先的;
2.2 Retentive Networks
在介绍框架之前,应该对Transformer和RoPE旋转位置编码有一定的了解,可以看下面两篇博客:
[transformer]论文实现:Attention Is All You Need_transformer vaswani论文-CSDN博客
[RoFormer]论文实现:ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING_roformer: enhanced transformer with rotaryposition-CSDN博客
Retentive Network 的大致结构和 Transformer 是一致的,其不同点主要在于利用了 multi-scale retention MSR 替换掉了 multi-heads attention MHA;Retentive Network 中的Retention有三种计算方法:The Parallel Representation of Retention, The Recurrent Representation of Retention, The Chunkwise Recurrent Representation of Retention;论文中主要介绍了前面两种,并行计算的结果和循环计算的结果是一致的;
在这里我们先给出计算过程,再去证明为什么并行计算的结果和循环计算的结果一致;

Retention
The Parallel Representation of Retention
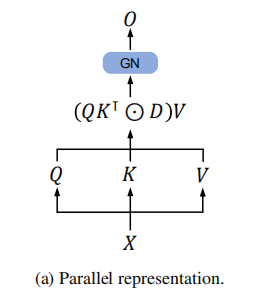
论文中相关内容如下:

可以看到在计算 Q Q Q和 K K K的时候,多出现了一个 Θ \Theta Θ,这里的 Θ = ( Θ 1 , Θ 2 , … , Θ n ) \Theta=(\Theta_1,\Theta_2,\dots,\Theta_n) Θ=(Θ1,Θ2,…,Θn), Θ n = e i n θ \Theta_n=e^{in\theta} Θn=einθ 通过这篇博客[RoFormer]论文实现:ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING_roformer: enhanced transformer with rotaryposition-CSDN博客,可以发现其其本质就是RoPE中的一个旋转矩阵;
这里插入介绍一下旋转矩阵的快速计算技巧:

结合下面代码:
def rotate_every_two(x):
x1 = x[:, :, :, ::2]
x2 = x[:, :, :, 1::2]
x = torch.stack((-x2, x1), dim=-1)
return x.flatten(-2)
def theta_shift(x, sin, cos):
return (x * cos) + (rotate_every_two(x) * sin)
theta_shift函数的返回值就是旋转矩阵,得到的旋转矩阵如图:
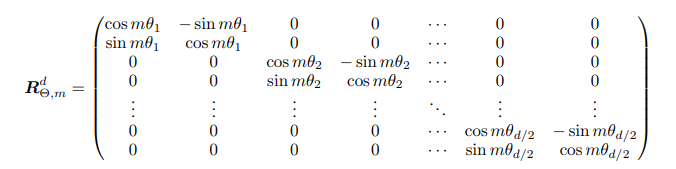
而 Θ ‾ \overline{\Theta} Θ 表示 Θ \Theta Θ共轭,其旋转矩阵相对于 Θ \Theta Θ,cos的结果不变,sin的结果变为相反数,从上图中可以明显的发现两个旋转矩阵是相互转置的;

从原文中看,上面的红框是很自然的推导出下面的红框的,其中十字架是共轭转置的意思,从这篇博客中得到的解释有出入关于RoPE旋转位置编码的理解-CSDN博客:
RoPE论文中原文可以用下面等式化等号:
q m = f q ( x m , m ) = ( W q x m ) e i m θ = R m W q x m q_m=f_q(x_m, m)=(W_qx_m)e^{im\theta}=R_mW_qx_m qm=fq(xm,m)=(Wqxm)eimθ=RmWqxm k n = f k ( x n , n ) = ( W k x n ) e i n θ = R n W k x n k_n=f_k(x_n, n)=(W_kx_n)e^{in\theta}=R_nW_kx_n kn=fk(xn,n)=(Wkxn)einθ=RnWkxn
可以看到 e i m θ e^{im\theta} eimθ用矩阵进行了替换,所以说如果按照这样解释的话 e i θ e^{i\theta} eiθ在并入转置矩阵中的时候,其应该是自动发生了共轭关系,应该是<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1339
1339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









