







Paper:Practical Deep Raw Image Denoising on Mobile Devices
噪声模型:带噪图 x x x 与无噪图 x ∗ x^* x∗ 的关系, k k k 跟 σ \sigma σ 与曝光水平ISO相关
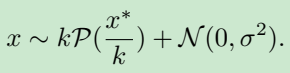
因此直接学 x x x 到 x ∗ x^* x∗ 的映射会加大网络的负担,因为ISO不同噪声水平就不同,结果就是学习一个对各个水平都好的网络,导致效果中庸。
本文灵感源于方差稳定变换(variance stabilizing transformations),对 x x x 作变换
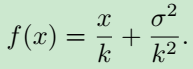
并且将 P ( λ ) P(\lambda) P(λ) 近似为 N ( λ , λ ) N(\lambda, \lambda) N(λ,λ),可得新的 x x x 与 x ∗ x^* x∗ 的对应关系
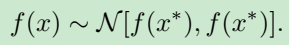
这样 f ( x ) f(x) f(x) 与 f ( x ∗ ) f(x^*) f(x∗) 的关系就与ISO无关了,网络只需要拟合正态分布
因此去噪问题可以利用网络在变换域( k − σ k-\sigma k−σ域)解决,
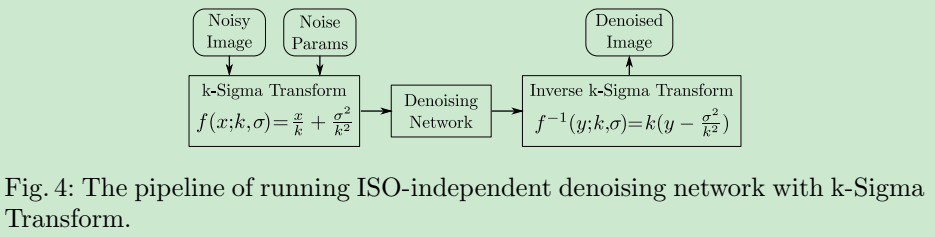
现在的问题是如何得到 f ( ⋅ ) f(·) f(⋅) 和 f − 1 ( ⋅ ) f^{-1}(·) f−1(⋅)。变换中有两个参数 k k k 跟 σ \sigma σ ,根据之前的噪声模型
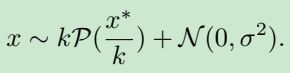
对某类传感器,曝光水平ISO固定时,可以用线性回归估计当前 ISO的 k k k 跟 σ \sigma σ 。因此可以提前估计好该传感器在不同 ISO 下的 k k k 跟 σ \sigma σ ,并记录下来。
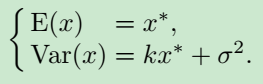

因此,根据实际拍摄时设定的 ISO,查表得当前 ISO 对应的 k k k 跟 σ \sigma σ ,做正变换,传给网络去噪,做逆变换,就可以完成去噪任务。
有一个问题,既然 E ( x ) = x ∗ E(x)=x^* E(x)=x∗,那为何不直接多拍几张算平均,还弄得这么麻烦?文中给出的答案是,这里不直接求平均得去噪图像的原因是,1)实际拍摄中也许手会抖,对多张图像需要快速且准确的校准模块;2)目标移动时方法失效;3)噪声水平很高时,效果不理想(弱结论)。
个人认为网络不是本文重点,一个U-Net风格的网络, L 1 L_1 L1 loss。 为了减轻计算,用了很多 depth-wise 和 point-wise conv,且在encoder中用5x5卷积来让网络不那么深又能有一定的感受野。
实验部分,参数估计时,可以从原始噪声模型看出 k k k 跟 g g g(与 ISO 相关)是线性的, σ \sigma σ 跟 g g g 是二次的,因此用对应的曲线拟合测到的 ISO散点图。这样就可以用合成数据(ISO是连续的)训练了。
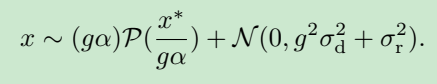















 1679
1679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









