







 本文介绍了词性标注(POS tagging)在自然语言处理(NLP)中的重要性,包括词性的概念、开放与封闭词性类别的区别,以及词性标注如何帮助消除语义歧义。文章还详细讲解了常见的英语词性标签集如Penn Treebank,并展示了词性标注的自动化方法,如基于规则、统计模型(如Unigram Tagger)和隐马尔可夫模型(HMM)。自动词性标注对于信息提取、信息检索和情感分析等任务至关重要。
本文介绍了词性标注(POS tagging)在自然语言处理(NLP)中的重要性,包括词性的概念、开放与封闭词性类别的区别,以及词性标注如何帮助消除语义歧义。文章还详细讲解了常见的英语词性标签集如Penn Treebank,并展示了词性标注的自动化方法,如基于规则、统计模型(如Unigram Tagger)和隐马尔可夫模型(HMM)。自动词性标注对于信息提取、信息检索和情感分析等任务至关重要。
注:
Unimelb Comp90042 NLP笔记
相关tutorial代码链接
Part of Speech(POS) Tagging(词性标注)
1 POS
1.1 什么是词性
词性就是词的属性,可以把词按照功能进行划分
- 词性也可以称为词类、形态类、句法类(word classes, morphological classes, syntactic categories)。
- 词类:名词、动词、形容词等等;形态类:过去时、现在时等等
- 词性可以告诉我们不少词本身和词前后邻居的信息
- 名词前面经常会是定语(determiners),比如 a, the
- 动词前面经常会是名词
- 读音的不同也会造成词性的不同,比如 CONtent,重音放在前面,就是名词内容;conTENT 重音放在后面就是形容词满意的
信息提取(Information Extraction)
一句话:“Brasilia, the Brazilian capital, was founded in 1960.”(巴西利亚,巴西的首都,在1960年建立。)
我们通过 关系(对象1,对象2) 来表示句子中词语的一些关系(这种形式表现关系的一般会在PDDL里面使用):
- capital(Brazilian, Brasilia),首都(巴西,巴西利亚)
- founded(Brasilia, 1960 ),建立(巴西利亚,1960)
这是信息提取的步骤之一,但是最重要的还是第一步,我们需要每个词的词性,比如noun(Brasilia, capital),adjectives(Brazilian),verbs(founded),numbers(1960)
1.2 POS Open Classes(开放词性)
词性分Open和Closed两类。
Open指允许扩展的词。典型的开放词性有名词和动词,这些词性经常会通过合成词、派生、创造新词、借用等方式引入新单词。
名词(Nouns):
- 专有名词(Proper):Australia V.S 普通名词(Common): wombat
- 不可数(Mass):rice V.S 可数(Count):bowls
动词(Verbs):
- 丰富的变形(inflection):go / goes / going / gone / went
- 辅助动词(Auxiliary verbs):be(am, is, are) / have(has) / do
- 具有传递性的(Transitivity):wait / hit / give (我等他,我打他)
形容词(Adjective):
- 比较级(Gradable):happy / happier V.S 不可比较(Non-Gradable):more computational
副词(Adverbs):
- 方式(Manner):Slowly
- 地点性(Locative):here
- 程度(Degree):really
- 时间性(Temporal):today
总之,开放词性,大白话就是说这类词会变形,会变单复数会变时态等等。
1.3 POS Closed Classes(封闭词性)
Closed指通常情况下无法加入新条目进入其中的词性,并且这类词性通常含有较少数量的条目。在大多数语言中,典型的封闭词性有介词(前置介词和后置介词)、限定词、连词和代词等。
Prepositions(介词):
in,on,with,for等,主要作为词和词的连接,比如 on the table(在桌上)
Particles(虚词)
pass out(晕倒)/ pass away(去世),单词基本和介词一样,但是功能完全不一样,它们一般会和前面的单词搭配,并且组成不同意思。
定语/限定词(Determiners):
- 冠词(Articles):a,an,the
- 指示词(Demonstratives):this,that,these,those
- 数量词(Quantifiers):each,every,some,two…
代词(Pronouns):
- 人称代词(Personal):I,me,she,…
- 所有格(Possessive):my,our,…
- 疑问词(Interrogative)/ Wh:who,what,…
连接词(Conjunctions):
- 并列词(Coordinating):and,or,but
- 从属(Subordinating):if,although,that…连接主句和从句
情态动词(Modal Verbs):
- 表能力(Ability):can,could
- 表允许(Permission):can,may
- 表可能(Possibility):may,might,could,will
- 表必须(Necessity):must
还有很多其他的:比如负面词(not),礼貌标记(politeness markers)
总之,封闭词性指那些不会再变化,已经固定的词语。
词性是通用(universal)的吗?
有部分是通用的,想开放词性中的动词和名词,就会出现在所有的语言中。
1.4 模棱两可(Ambiguity)
- 由于很多词会属于不同类型,会使得语义模棱两可。
- 词性是根据上下文决定的。
- 例子:
- Time flies like an arrow (光阴似箭)
- Fruit flies like a banana(果蝇喜欢香蕉)
| Time | flies | like | an | arrow |
|---|---|---|---|---|
| 名词 noun | 动词 verb | 介词 preposition | 限定词 determiner | 名词 noun |
| Fruit | flies | like | a | banana |
|---|---|---|---|---|
| 名词 noun | 名词 noun | 动词 verb | 限定词 determiner | 名词 noun |
一些新闻标题的理解歧义:
- Britsh Left Waffles on Falkland Island
- 正确:英国左派在福克兰岛问题上摇摆不定
- 错误:英国人留了华夫饼在福克兰岛
- Juvenile Court to Try Shooting Defendant
- 正确:少年法庭判决了枪击案的被告人
- 错误:少年法庭尝试射杀被告人
中文举例:
喜欢上一个人 (狗头)
2 标签集(Tagset)
标签集是一种词性信息的紧凑(compact)表达,也就是表示词性的集合体。
- 通常用 ≤ 4 \leq4 ≤4 的大写字母来表示(比如 NN = noun)
- 对于形态上的变形通常也会归成单独的一类(比如有些词性标签集合中会把名词的单复数也作区分,单数名词为NN,复数名词为NNS)
主要的英语标签集:
- Brown(87个tags)
- Penn Treebank(45)
- CLAWS/BNC(61)
- “Universal”(12)
目前至少有一个标签集是可以适用于所有主要语言的。
2.1 Penn Treebank标签例子
PT中主要的标签有:
| 缩写 | 意义 | 缩写 | 意义 |
|---|---|---|---|
| NN | noun | VB | verb |
| JJ | adjective | RB | adverb |
| DT | determiner | CD | cardinal number(基数) |
| IN | preposition | PRP | personal pronoun |
| MD | modal | CC | coordinating conjunction |
| PR | particle | WH | wh-pronoun |
| To | to |
这里把 to 单独拿出来了。
2.1.1 衍生标签(开放词性)
NN (noun singular, wombat)
- NNS (复数 plural, wombats)
- NNP (专有名词 proper, Australia)
- NNPS (专有名词复数形式 proper plural, Australians)
VB (动词不定式 verb infinitive, eat)
- VBP (第一/二人称现在时 1st /2nd person present, eat)
- VBZ (第三人称单数 3rd person singular, eats)
- VBD (过去式 past tense, ate)
- VBG (正在进行时 gerund, eating)
- VBN (过去分词 past participle, eaten)
JJ (形容词 adjective, nice)
- JJR (比较级 comparative, nicer)
- JJS (最高级 superlative, nicest)
RB (副词 adverb, fast)
- RBR (比较级 comparative, faster)
- RBS (最高级 superlative, fastest
PRP (人称代词 pronoun personal, I)
- PRP$ (所有格 possessive, my)
WP (Wh-pronoun, what):
- WP$ (所有格 possessive, whose)
- WDT(限定词 wh-determiner, which)
- WRB (副词 wh-adverb, where)
2.2 标注文本样例
最开始的词性标注就是体力活…
以 Penn Treebank 为例,对一下文本进行标注,红色为标签。
The/DT limits/NNS to/TO legal/JJ absurdity/NN stretched/VBD another/DT notch/NN this/DT week/NN when/WRB the/DT Supreme/NNP Court/NNP refused/VBD to/TO hear/VB an/DT appeal/VB from/IN a/DT case/NN that/WDT says/VBZ corporate/JJ defendants/NNS must/MD pay/VB damages/NNS even/RB after/IN proving/VBG that/IN they/PRP could/MD not/RB possibly/RB have/VB caused/VBN the/DT harm/NN ./.
3 自动标注(Automatic Tagging)
3.1 为什么要自动进行词性标注
- 对此形态学分析很重要,比如词法分析(lemmatization),即进行词性还原等。
- 对某些应用,我们想要重点关注一些词性。比如对于信息检索(information retrieval)名词就很重要,对于情感分析(sentiment analysis)形容词就很重要
- 对一些分类任务有非常有用的功能。比如流派特性(genre),是不是虚构的。
- 词性标签可以避免词义歧义(sense disambiguation)。比如,cross可以标注成 /NN /VB /JJ
- 可以用他们生成更大的结构(比如解析,后期会介绍)
3.2 自动标注器(Automatic Taggers)
标注器有两大类:
- 基于规则的标注器(Rule-based taggers)
- 基于统计的标注器(Statistical taggers)
- Unigram tagger
- Classifier-based tagger(以分类器为基础的标注器)
- Hidden Markov Model(HMM)标注器(05篇讲)
3.2.1 Rule-based Tagging
- 通常从每个单词的可能标签列表(a list of possible tags)开始
- 来自一个词汇资源或者语料库
- 通常包含一些其他的词汇信息
- 例如:动词的次类(subcategorisation),即参数(arguments)
- 通过应用规则来减少其他tag的可能性并选中最后一个tag作为标注
- 比如,当DT在word前面出现了,那word就不会是VB
- 需要依赖在一些不模棱两可的上下文
- 超大的文本会有上千种约束,所以会很难维护。
3.2.2 Unigram Tagger
- 一元标注器主要就是打上一个词最常见的词性(common tag)
- 需要一个打好标签的语料库
- 这个“模型”其实就是一个查询表
- 但实际上表现良好,可以有大约90%的准确率,能解决75%模棱两可的情况。
- 一般当做复杂方法的baseline
总而言之,基本思路:给一个打好标签的语料库,然后统计每个单词最常见的词性,制作成一个“查询表”(即unigram tagger)。当要打标签的数据进来后,直接去查找这个词即可。
注意: 与几乎所有基于统计的标注器一样,UnigramTagger的性能高度依赖于其训练集的质量。尤其是,如果训练集太小,它将无法可靠地估计每个单词最可能的标签。如果训练集与我们希望标记的文本显着不同,性能也会受到影响。
3.2.3 Classifier-Based Tagging
- 使用一个标准的判别性分类器(比如逻辑回归、神经网络),这个分类器有以下特征:
- 目标单词(target word)
- 围绕该词的词汇背景 (Lexical context),即上下文
- 句中已分类的标签
- 但会受到传播(propagation)的影响:如果前一步的预测就错了,那后面就会受到影响,因为后面的预测会基于前面的预测结果给出。
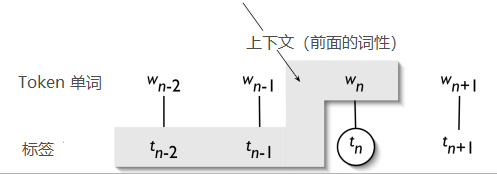
3.2.4 Hidden Markov Models(隐马尔可夫模型)
具体内容将在NLP05篇讲述。
- 一个基本的顺序(或结构化)模型
- 像顺序分类器一样,同时使用以前的标签和词法证据(lexical evidence)
- 与分类器不同的是,HMM考虑先前标签的所有可能性。这样会避免当前一个词性标错之后,对当前标签产生影响。
- 与分类器不同的是,将先前的标签证据(tag evidence)和词法证据(lexical evidence)视为相互独立的。也就是不将单词和词性混在一起来判断。
- 稀疏度较低 (TODO:稀疏性是指一个数字矩阵,其中包含许多不会显着影响计算的零或值。)
- 顺序预测的快速算法,即找到整个单词序列的最佳标签。因为可以利用维特比译码(Viterbi decoding)来找到整个单词序列的最佳序列标注,而这在前面的分类器方法中很难实现。(TODO)
3.3 未知单词(Unknown Words)
- 在形态丰富的语言中存在巨大的问题 (例如:土耳其)
- 可以用我们只见过一次的东西(hapax legomena,罕用语)来最好地猜测我们以前从未见过的东西
- 动词前面往往是名词,而不太可能是定语
- 可使用子词(sub-word)表示法来捕捉词语形态(寻找常见词缀 common affixes)。

















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









