







实现流程:

Front Processing:
语音输入被转换为64维fbank,并且含有零均值与单位方差。
DNN:有两种DNN:
* ResCNN
* GRU
ResCNN:

GRU:

Average Sentence:

将帧级输入聚合为整段语音的输入
Affine:将其转换成512维的embedding。
计算相似度:
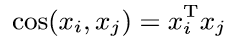
最后用triplet loss为目标进行训练
实验
使用softmax和交叉熵损失来预训练整个模型,即用一个classification layer来代替length normalization和triplet loss层。

可见与训练提高了模型准确率

可见实验结果很好,且ResCNN效果好于GRU。

将两种网络的score相加,可以看到表现得到了提升,其中score fusion表示把两个模型输出的cos score相加。

在文本无关的说话人验证任务上,训练数据集越大,模型的训练越充分,效果越好

deep speaker具有比较好的跨语言能力















 2478
2478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









