







什么是RDD?
在Apache Spark的数据处理架构中,RDD(Resilient Distributed Datasets,弹性分布式数据集)扮演着核心角色。RDD是Spark计算的基本单元,它使得开发者能够以一种高效且容错的方式来处理大规模数据集。
Spark的计算任务始于一个Spark上下文对象,通常通过SparkContext创建。SparkContext是与Spark集群交互的入口,它负责资源的申请、任务的调度以及RDD的创建和管理。
通过Spark上下文,开发者可以创建RDD实例,这些RDD可以是从HDFS、本地文件系统或其他数据源加载的数据集。加载数据后,Spark会自动将数据集切分成多个分区(partition),以支持后续的并行计算。
RDD的分布式特性
RDD的分布式特性体现在其数据切分和存储上。当数据加载到RDD时,Spark会根据数据源的特性(如HDFS的block)或自定义的切分规则,将数据集切分成多个分区。每个分区可以独立地在集群的不同节点上进行处理,从而实现并行计算。
RDD的弹性特性
RDD的弹性特性主要体现在其容错机制上。RDD是不可变的,即一旦创建,其内容就不能被修改。这种设计使得RDD在计算过程中形成了一个有向无环图(DAG),每个节点代表一个RDD分区的转换操作。
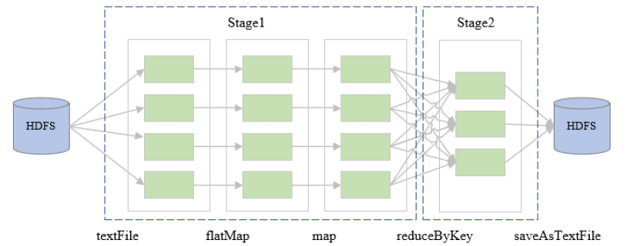
当计算过程中某个分区失败时,由于RDD的不可变性,Spark可以简单地回溯到前一个RDD分区,并重新计算丢失的分区数据,而无需重新计算整个数据集或回退到数据加载阶段。这种设计极大地简化了容错处理,提高了计算的稳定性。
RDD的操作方法(算子)
RDD对象提供了丰富的操作方法,即算子,用于对数据集进行各种处理。这些算子分为两类:
-
转换算子(Transformations):如
map、filter、flatMap等,它们创建一个新的RDD而不立即执行计算,而是在触发一个动作算子时才执行。
-
动作算子(Actions):如
count、collect、saveAsTextFile等,它们触发实际的计算并返回结果或将结果保存到外部存储系统。
结果输出与保存
通过RDD的转换和动作算子,开发者可以构建复杂的数据处理流程,并最终将处理结果输出保存。这可以是简单的计数、数据聚合,也可以是复杂的机器学习模型训练或图计算结果。
RDD作为Spark的核心,其弹性分布式的特性使得Spark能够有效地处理大规模数据集,同时提供高容错性和易于使用的编程模型。通过Spark上下文构建的RDD,开发者可以利用其提供的算子来满足各种数据处理需求,最终实现高效、可靠的大数据处理任务。
















 2881
2881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









