







1.分析PointNet结构:

问题一:点云是如何进行MLP的
上次讲过pointnet的基本结构如下图所示,

分析代码,代码中我做了详细注释,可以直接看下面结构图。
def get_model(point_cloud, is_training, bn_decay=None):
""" Classification PointNet, input is BxNx3, output Bx40 """
batch_size = point_cloud.get_shape()[0].value
num_point = point_cloud.get_shape()[1].value # 每个点云的点数
end_points = {}
input_image = tf.expand_dims(point_cloud, -1)# 扩展为4D张量;;-1表示最后一维
# BxNx3x1 [NHWC]
# Point functions(MLP implemented as conv2d)
# 64个1×3的卷积核;每个[1,3]的卷积核依次对点进行卷积生成一个通道;所有的卷积核卷积完
# 后生成64个通道
net = tf_util.conv2d(input_image, 64, [1, 3],
padding='VALID', stride=[1, 1],
bn=True, is_training=is_training,
scope='conv1', bn_decay=bn_decay)
# BxNx1x1
# BxNx1x64
#注意:通过使用这种方法,大大的减少了参数的使用
#例如将[B,1024]的点云升维为[64,1024],
#对全连接网络需要至少3×1024x64×1024个参数,
#而使用这种方法仅用了3×64个参数(64个[1,3]卷积核),这也是MLP共享参数的原因。
#每个[1,1]的卷积核将64个通道的卷积结果求和并通过激活函数后输出,对应的输出为[Batch size,点数,64]
net = tf_util.conv2d(net, 64, [1, 1],
padding='VALID', stride=[1, 1],
bn=True, is_training=is_training,
scope='conv2', bn_decay=bn_decay)
# BxNx1x64
net = tf_util.conv2d(net, 64, [1, 1],
padding='VALID', stride=[1, 1],
bn=True, is_training=is_training,
scope='conv3', bn_decay=bn_decay)
# BxNx1x64
net = tf_util.conv2d(net, 128, [1, 1],
padding='VALID', stride=[1, 1],
bn=True, is_training=is_training,
scope='conv4', bn_decay=bn_decay)
# BxNx1x128
net = tf_util.conv2d(net, 1024, [1, 1],
padding='VALID', stride=[1, 1],
bn=True, is_training=is_training,
scope='conv5', bn_decay=bn_decay)
# BxNx1x1024
# Symmetric function: max pooling
net = tf_util.max_pool2d(net, [num_point, 1],
padding='VALID', scope='maxpool')
# MLP on global point cloud vector
net = tf.reshape(net, [batch_size, -1])
net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training,
scope='fc1', bn_decay=bn_decay)
net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training,
scope='fc2', bn_decay=bn_decay)
net = tf_util.dropout(net, keep_prob=0.7, is_training=is_training,
scope='dp1')
net = tf_util.fully_connected(net, 40, activation_fn=None, scope='fc3')
return net, end_points
根据代码,我画了一下pointnet神经网络图,最后的全连接层没有画。
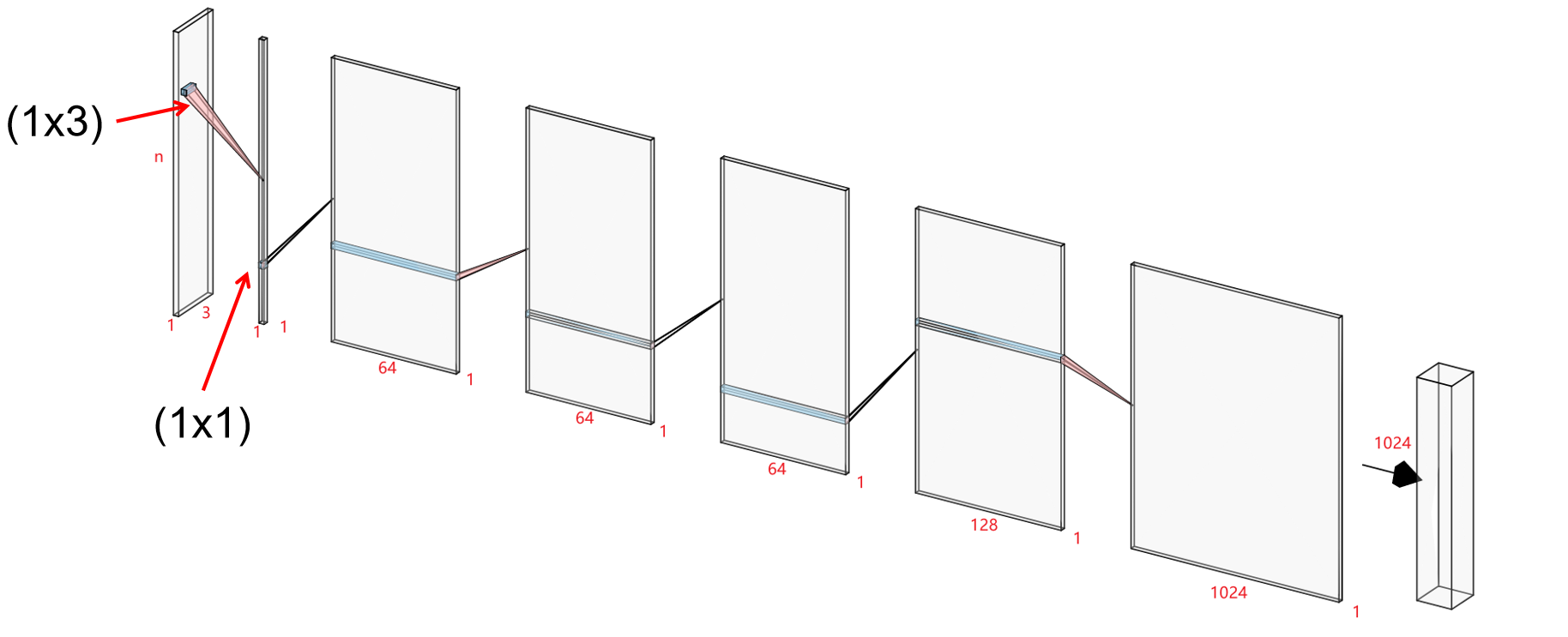
如果用矩阵表示,可以把输入点云看成一个(nx3)二维矩阵:

channels 的理解有两个问题:
1.怎么进行卷积操作?
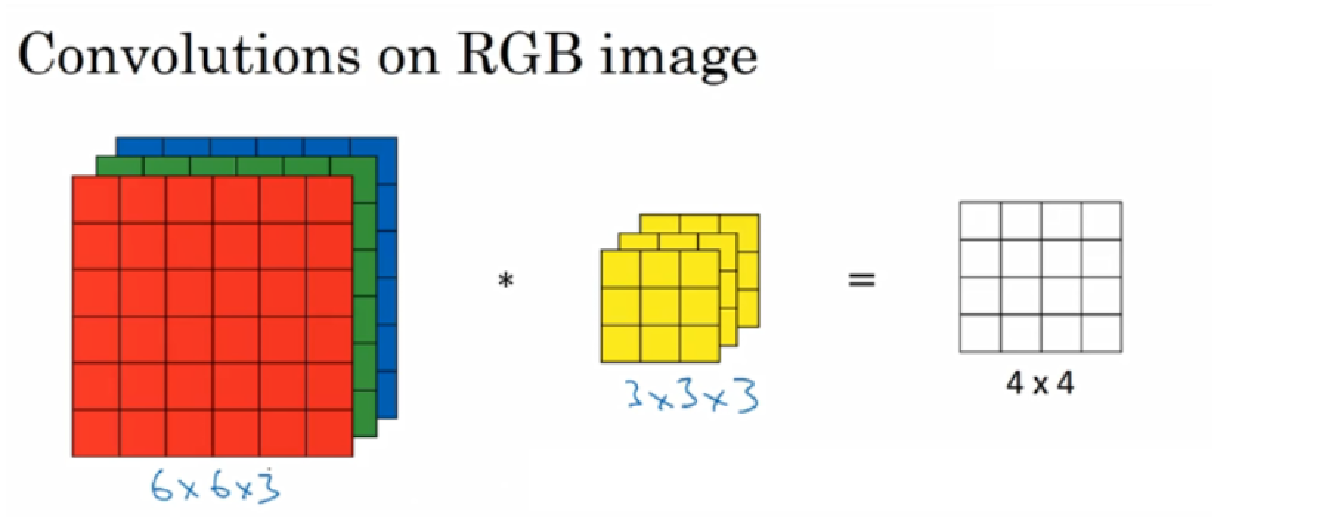
来源:吴恩达DeepLearning-Ai课程
卷积操作其实是用一个卷积核在图片上做运算,对于多通道的卷积,要将卷积核的每个数字和输入矩阵对应相乘,再求和,得到一个结果。如果输入是3通道的,那么卷积核也必须是3通道。

在3通道的RGB图像中,用3通道的3x3卷积核做卷积操作:卷积核中的27个数字与分别与样本对应相乘后,再进行求和,得到第一个结果。
2.怎么改变同道数以及为什么改变通道数?


如果要输出多通道,就是用多个卷积核分别进行计算,获得多个特征图。多个特征图我们就认为是多个通道。
此时输出的通道数也就是下一次的输入通道数。
1x1卷积
给神经网络添加了一个非线性函数。
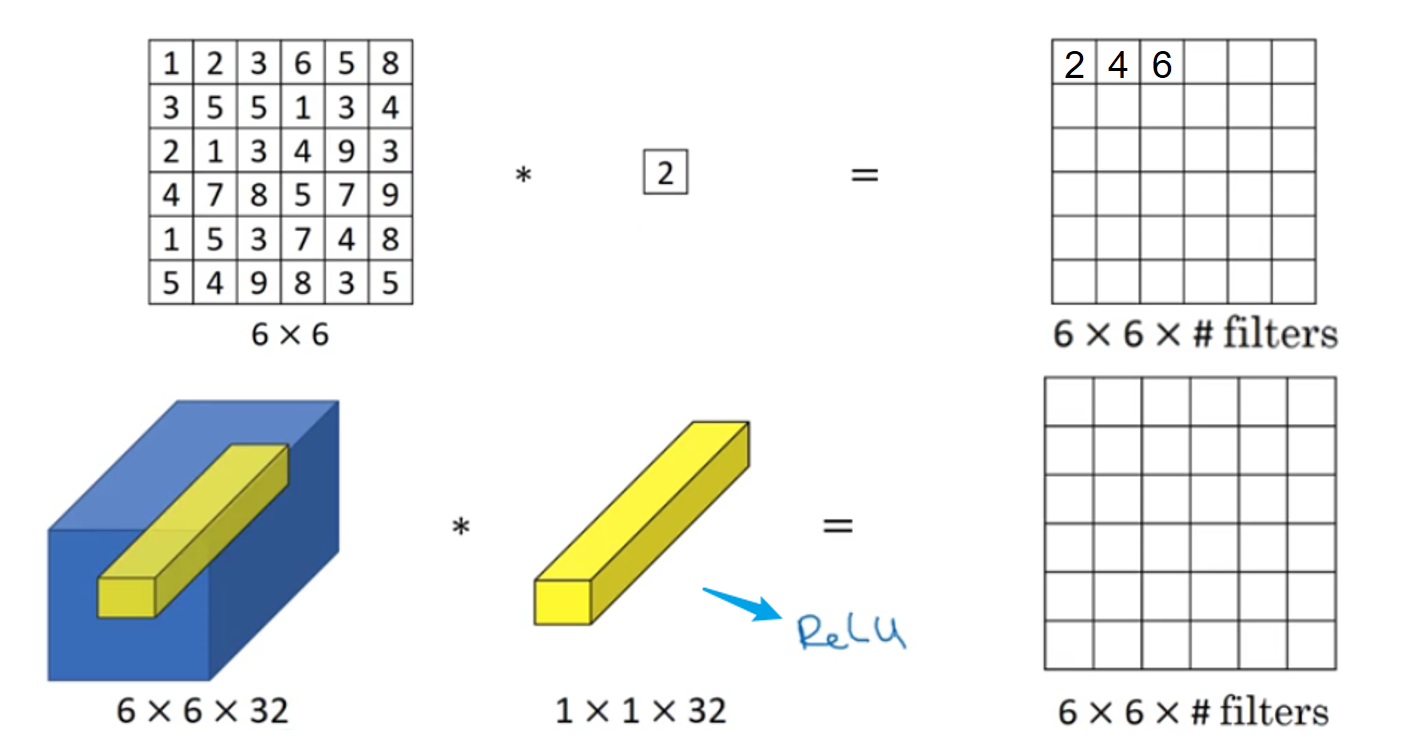
.
1x1卷积本质上可以看成一个前连接层,上图中一个黄色区块进行1x1卷积可以看成下面的图:
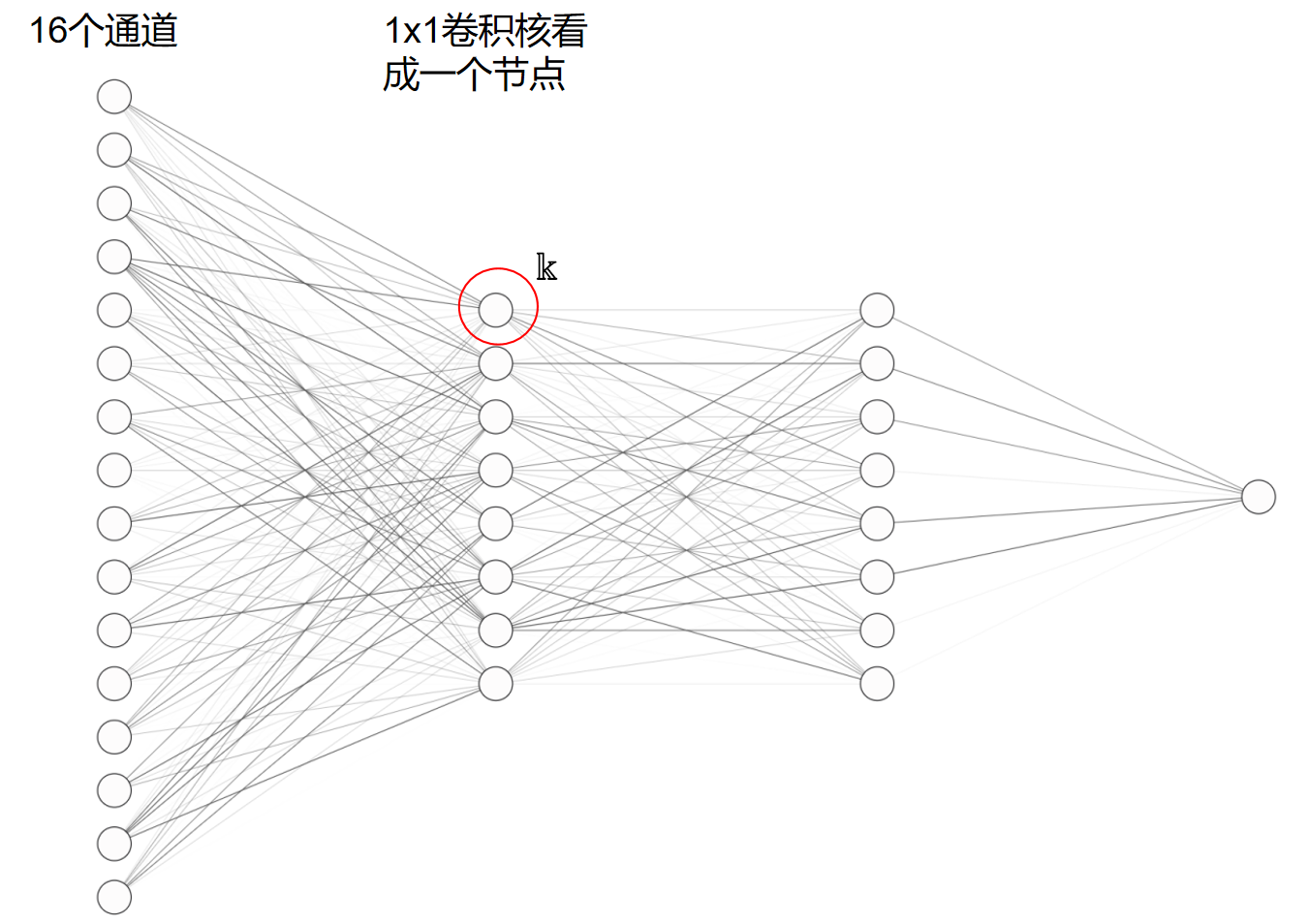
卷积核也是多通道的:
单个节点表示为


1x1卷积的作用:
- 放缩通道数的大小 :通过控制卷积核的数量达到通道数大小的放缩。而池化层只能改变高度和宽度,无法改变通道数。
- 增加非线性:如上所述,1×1卷积核的卷积过程相当于全连接层的计算过程,并且还加入了非线性激活函数,从而可以增加网络的非线性,使得网络可以表达更加复杂的特征。
- 减少参数:在Inception Network中,由于需要进行较多的卷积运算,计算量很大,可以通过引入1×1确保效果的同时减少计算量。
问题二:LSTM问题
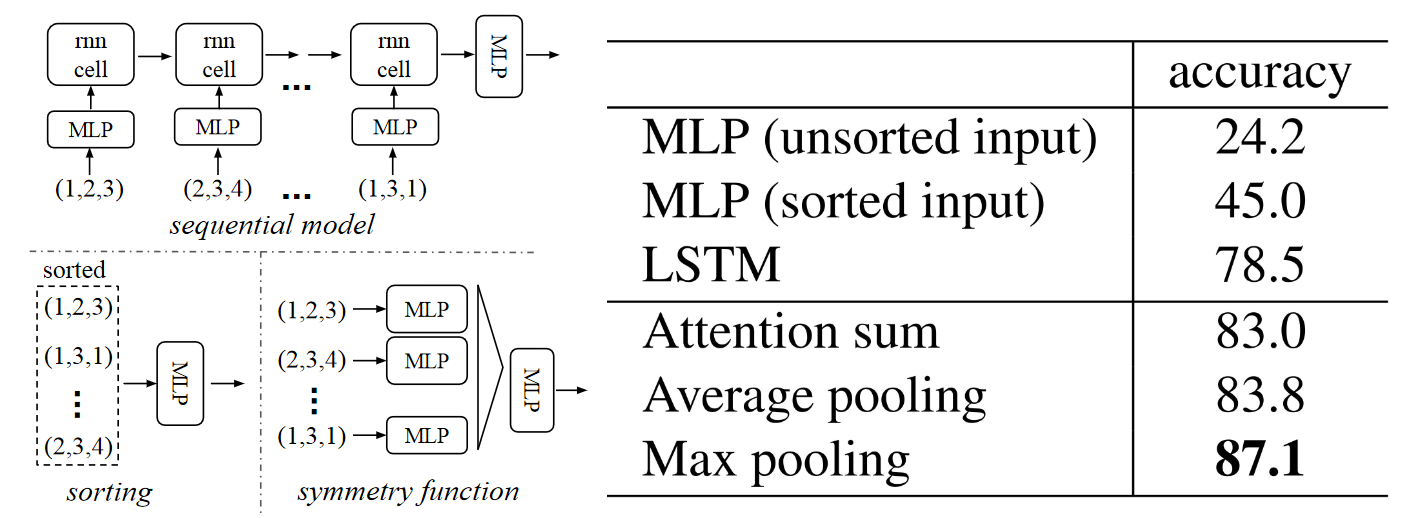
RNN cell介绍
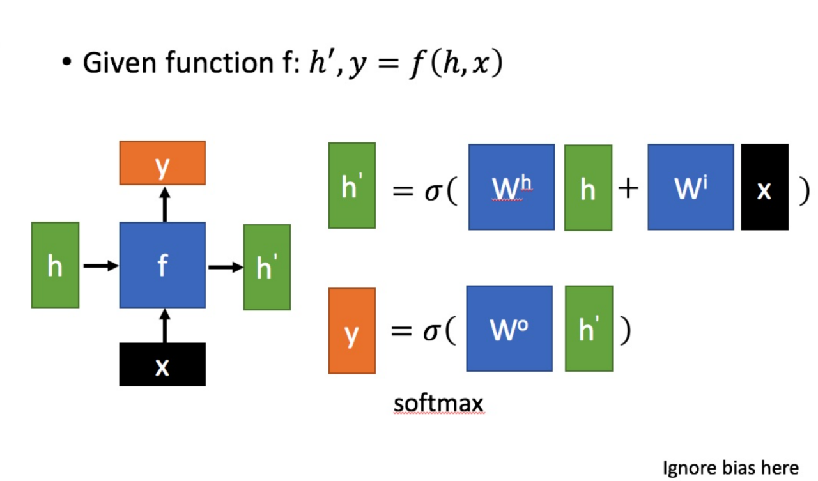
X:为当前状态下数据的输入,
h: 表示接收到的上一个节点的输入。
Y:为当前节点状态下的输出,
h’:为传递到下一个节点的输出。
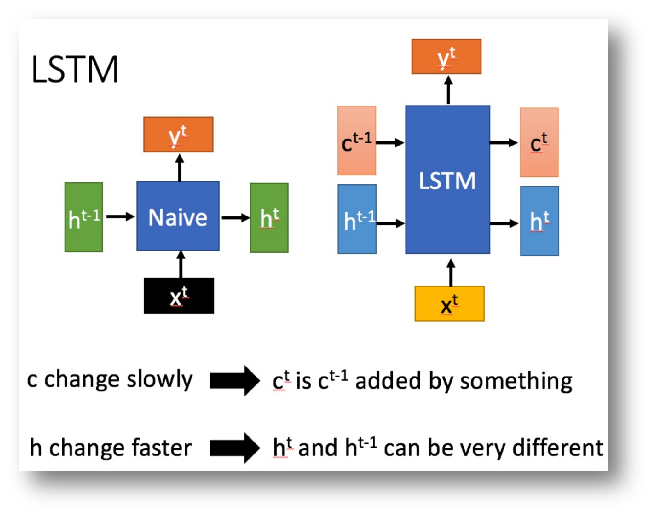
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。















 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









