







【论文阅读】运动去模糊之数据增强ID-Blau模型
ID-Blau: Image Deblurring by Implicit Diffusion-based reBLurring AUgmentation(2024)
摘要
图像去模糊的目的是从动态场景中捕捉的图像中去除不希望出现的模糊。许多研究都致力于通过模型架构设计来提高去模糊性能。然而,针对图像去模糊的数据增强研究却很少。 由于连续运动会在图像曝光过程中产生模糊伪像,我们希望开发一种突破性的模糊增强方法,通过模拟连续空间中的运动轨迹来生成多样化的模糊图像。 本文提出了基于隐式扩散的模糊再判断(ID-Blau),利用锐利图像与可控模糊条件图配对,生成相应的模糊图像。我们将模糊图像的模糊参数与其方向和幅度参数化为像素模糊条件图,以模拟模糊轨迹,并将其隐式地表示在连续空间中。通过对各种模糊条件进行采样,ID Blau 可以生成训练集中未见的各种模糊图像。实验结果表明,ID Blau 可以生成真实的模糊图像用于训练,从而显著提高最先进的去模糊模型的性能。
模型结构
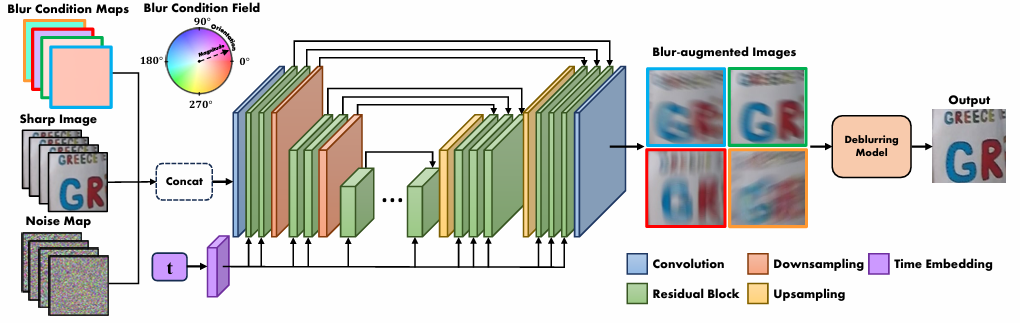
用连续空间中的方向和大小来表征模糊,在其中采样模糊条件以重新模糊清晰的图像。通过建模模拟曝光期间连续运动产生的模糊轨迹(光流),隐含地操纵模糊条件,以生成在数据增强训练期间看不见的各种模糊图像。
参考GOPRO数据集的制作,将240fps的连续帧每11帧叠加为模糊帧来模拟运动模糊,取中间帧为清晰帧构建成GOPRO运动模糊数据集。
模糊条件图通过计算双向光流的平均得到:
F = ∑ n = 1 N − 1 f θ ( V [ n ] , V [ n + 1 ] ) − F θ ( V [ n + 1 ] , V [ n ] ) 2 F=\sum_{n=1}^{N-1}\frac{f_\theta (V[n],V[n+1])-F_\theta (V[n+1],V[n])}{2} F=∑n=1N−12fθ(V[n],V[n+1])−Fθ(V[n+1],V[n])
其中, f θ f_\theta fθ是光流估计网络(光流是矢量),源码中使用的是RAFT: Recurrent All Pairs Field Transforms for Optical Flow; F = ( u ; v ) ϵ R H × W × 2 F=(u;v)\epsilon R^{H\times W\times 2} F=(u;v)ϵRH×W×2;
模糊条件建模:
对F归一化并扩展一维达到 F = ( x , y , z ) ϵ R H × W × 3 F=(x,y,z)\epsilon R^{H\times W\times 3} F=(x,y,z)ϵRH×W×3:
x i , j = u i , j u i , j 2 + v i , j 2 ; y i , j = v i , j u i , j 2 + v i , j 2 ; z i , j = u i , j 2 + v i , j 2 M ; x_{i,j}=\frac{u_{i,j}}{\sqrt{u_{i,j}^2+v_{i,j}^2}}; y_{i,j}=\frac{v_{i,j}}{\sqrt{u_{i,j}^2+v_{i,j}^2}}; z_{i,j}=\frac{\sqrt{u_{i,j}^2+v_{i,j}^2}}{M}; xi,j=ui,j2+vi,j2ui,j;yi,j=ui,j2+vi,j2vi,j;zi,j=Mui,j2+vi,j2;表示像素 ( i , j ) (i,j) (i,j)的水平和垂直方向的模糊程度, z ϵ [ 0 , 1 ] z\epsilon [0,1] zϵ[0,1]表示模糊幅度,M为该组模糊光流中最大的模糊幅度。
通过模糊条件可以构建新的去模糊训练图像对 { B n , S n , C n } n = 1 K \{B_n,S_n,C_n\}_{n=1}^K {Bn,Sn,Cn}n=1K,使用清晰图像 Sn 和模糊条件图 Cn 来生成相应的模糊图像 Bn,Cn在归一化运动光流中进行采样获得。
基于DDPM: Denoising Diffusion Probabilistic Models建立条件扩散模型进行训练:
前向扩散过程:
q ( B t ∣ B t − 1 ) = N ( B t ; α t B t − 1 , ( 1 − α t ) I ) q(B_t|B_{t-1})=N(B_t;\sqrt{\alpha_t}B_{t-1},(1-\alpha_t)I) q(Bt∣Bt−1)=N(Bt;αtBt−1,(1−αt)I) : α t \alpha_t αt 每一步的噪声方差,越来越大,在0~1之间。
α t \alpha_t αt每一步的噪声方差,越来越大,在0~1之间。
q ( B 1 : T ∣ B 0 ) = ∏ t = 1 T q ( B t ∣ B t − 1 ) q(B_{1:T}|B_0)=\prod_{t=1}^T q(B_{t}|B_{t-1}) q(B1:T∣B0)=∏t=1Tq(Bt∣Bt−1):马尔可夫过程;
B T = α ‾ t B 0 + ( 1 − α ‾ t ) ϵ B_T=\sqrt{\overline\alpha_t}B_0 +\sqrt{(1-\overline\alpha_t)}\epsilon BT=αtB0+(1−αt)ϵ,其中, α ‾ t = ∏ i = 1 t α i ; ϵ ∽ N ( 0 , 1 ) \overline\alpha_t=\prod_{i=1}^t \alpha_i \ ; \ \epsilon\backsim N(0,1) αt=∏i=1tαi ; ϵ∽N(0,1),随机噪声。
后向去噪过程:
反向条件概率:$p_\theta (B_{t-1}|B_t,S,C)=N(B_{t-1};\mu_\theta(B_t,S,C,t),\sigma_t^2I);$ $\mu_\theta(B_t,S,C,t)=\frac{1}{\sqrt{\alpha_t}}(B_t-\frac{1-\alpha_t}{1-\overline\alpha_t}\epsilon_\theta(B_t,S,C,t))$; $\epsilon_\theta$:去噪模型。
损失函数
L = ∥ ϵ − ϵ θ ( B t , S , C , t ) ∥ 1 L=\|\epsilon-\epsilon_\theta(B_t,S,C,t)\|_1 L=∥ϵ−ϵθ(Bt,S,C,t)∥1,随机噪声与条件去噪模型的差。
论文结果

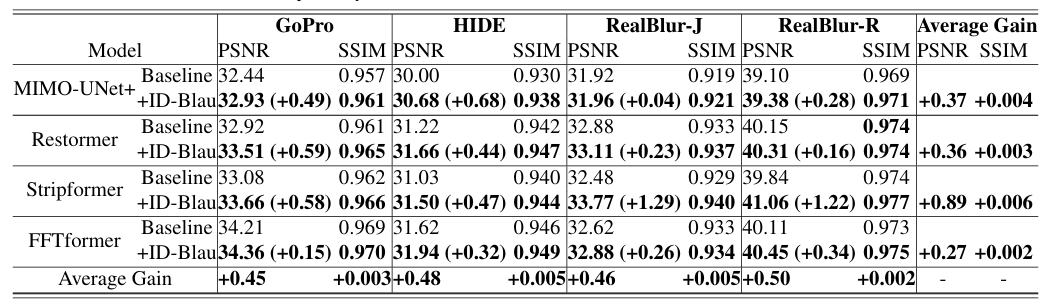
对去模糊模型的影响:

论文:https://arxiv.org/pdf/2312.10998
Github:https://github.com/plusgood-steven/ID-Blau?tab=readme-ov-file
复现:流程比较复杂,数据集要严格符合GOPRO的文件目录,其他模态图像也有一定效果。对于低帧率图像序列,可以通过该方法采样增强。

















 7031
7031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









