









文章基本信息
2020Recsys 论文地址:Long-tail Session-based Recommendation
0 ABSTRACT
基于会话的推荐重点在于基于匿名会话的用户行为的预测,并且在缺乏用户历史数据的情况下是一种必要的方法。但是,现有的基于会话的推荐方法都没有明确考虑长尾推荐,这在改善推荐的多样性和产生偶然性方面起着重要作用。由于在基于会话的推荐方案(例如,电子商务,音乐和电视节目推荐)中,带有长尾的项的分布很普遍,因此应更加注意基于长尾的会话的推荐。
在本文中,我们提出了一种新颖的网络架构,即TailNet,以提高长尾推荐性能,同时与其他方法相比保持竞争性的准确性。我们首先根据点击频率将商品分类为短头(流行)和长尾(niche)商品。然后提出了一种新颖的偏好机制,并将其应用于TailNet中,以确定两种类型项目之间的用户偏好,从而对建议进行软调整和个性化。在两个真实世界的数据集上进行的大量实验证明了我们的方法与最新技术相比的优越性。
1 INTRODUCTION
基于会话的推荐系统(Session-based Recommendation System ,SRS)由于在线服务中的众多应用领域(例如,电子商务,音乐和网页导航)而备受关注。这样的建议仅依靠匿名用户按时间顺序排列的大型操作日志来预测用户的下一个操作。
最近的研究主要集中在实现最新的准确性性能上,而没有在SRS中考虑长尾建议。
但是,以前的研究从两个角度对基于长尾的推荐的重要性提供了全面的解释。
对于用户而言,仅推荐流行的物品容易使他们感到无聊。长尾推荐可以增加推荐列表的多样性和偶然性,这使他们感到惊讶和满意,因为长尾项仍然与用户非常相关。
对于商业而言,长尾物品与短头物品相比具有相对较大的边际利润,这意味着长尾推荐可以带来更多的利润。此外,长尾推荐可以为用户提供“一站式购物便利”,可以诱使客户一步一步地消费短头商品和长尾商品,从而创造更多的销售额。诸如数据稀疏性之类的障碍阻碍了长尾推荐的应用,导致包括SRS在内的大多数现有推荐系统都偏向流行项目。
在这些方法中,偏爱推荐最受欢迎的商品是提高准确性的保守但有效的方法。先前针对长尾建议的工作要么牺牲了建议的准确性,要么采用了超出SRS数据限制的辅助信息(例如,用户配置文件,操作类型)来缓解长尾建议项目数据稀疏性。
对于基于会话的数据,长尾推荐的难度更大。
首先,由于会话中缺少辅助信息和用户配置文件,传统的长尾推荐方法很难应用于基于会话的推荐中。
其次,大多数传统的长尾推荐方法都难以考虑到数据的顺序。因此,当涉及到基于会话的推荐时,这些方法的推荐准确性会严重下降。第三,大量的会话数据特别稀疏,因为每个用户可能有多个会话,每个会话应独立处理,这会降低长尾推荐的模型性能。因此,开发一种可以解决上述难题的新方法具有重要意义。
在本文中,为了解决SRS中的长尾现象,我们提出了一种新颖的网络结构– TailNet。与现有的基于神经网络的推荐算法不同,我们的方法可以显着提高长尾推荐性能,同时同时使用最新方法保持竞争结果。特别是,我们首先将每个会话编码为潜在表示。然后,我们在模型中引入了一种新颖的偏好机制,该机制通过从会话表示中学习来确定单击热门项目和长尾项目之间的用户偏好,并生成纠正因子。 TailNet可以利用偏好机制给出的校正因子来软调整模型的推荐模式:推荐更多的短头物品或长尾物品。偏好机制是在端到端的反向传播训练范例中与TailNet共同学习的。
2 MODEL
2.1 Notations
可以将SRS的目标定义为使用用户的当前会话数据来预测用户的下一个点击项。 I = { i 1 , i 2 , . . . , i ∣ I ∣ } I = \{ i_1,i_2,...,i _{|I|} \} I={i1,i2,...,i∣I∣}表示所有会话中唯一项的集合。
在本文中,我们根据帕累托原理将项目分为
I
H
,
I
T
I^H, I^T
IH,IT,这分别代表了短头项目和长尾项目的集合。
s
=
{
i
1
,
i
2
,
.
.
.
,
.
i
t
}
s = \{i_1,i_2,...,. i_t\}
s={i1,i2,...,.it}表示由时间戳排序的项组成的会话。
V
=
{
v
1
,
v
2
,
.
.
.
,
v
t
}
V = \{v_1,v_2,...,v_t\}
V={v1,v2,...,vt}表示由会话编码器层编码的会话的潜在表示,其中
v
t
∈
V
v_t∈V
vt∈V表示在时间戳t处V中的单击项表示。
在TailNet中,我们首先获得
c
^
\hat c
c^,其中每个元素值是softmax之前项目的得分。
然后,我们使用偏好机制来获得标记为
R
h
e
a
d
R_{head}
Rhead 和
R
t
a
i
l
R_{tail}
Rtail 的整流因子(分别对应于短头项目和长尾项目)以进行软调整。
最后,TailNet输出可能项目的概率
y
^
\hat y
y^ ,其中向量
y
^
\hat y
y^ 的每个元素值都是对应项目的推荐分数。
embedding
S
l
m
S^m_l
Slm(最后点击的项目的表示形式),然后将其压缩为表示形式
S
p
S_p
Sp。发送到sigmoid S形函数后,我们可以获取
R
h
e
a
d
R_{head}
Rhead 和
R
t
a
i
l
R_{tail}
Rtail。我们使用 门控循环单元(GRU) 对 会话S进行编码,其中GRU定义为: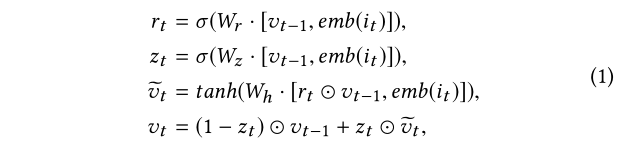
其中
W
r
,
W
z
以
及
W
h
W_r,W_z以及W_h
Wr,Wz以及Wh 表示 相应门的权重;
e
m
b
(
i
t
)
emb(i_t)
emb(it)表示项目
i
t
i_t
it的嵌入;
σ
σ
σ表示S型函数。我们初始化
v
0
=
0
v_0 =0
v0=0。每个会话都被编码为
V
=
{
v
1
,
v
2
,
.
.
.
,
v
t
}
V = \{v_1,v_2,...,v_t\}
V={v1,v2,...,vt}。
2.2 Preference Mechanism
我们引入了一种偏好机制来软调整 T a i l N e t TailNet TailNet 的模式。如图1所示,偏好机制包含一个编码器,一个具有注意力机制的线性变换层 和 一个S型函数。该机制将会话的潜在表示形式 V = { v 1 , v 2 , . . . , v t } V = \{v_1,v_2,...,v_t\} V={v1,v2,...,vt}作为输入。
首先,我们需要将项目类型嵌入到项目表示中。对于长尾项和短头项的输入(由帕累托原理[2]分割),我们分别添加了一个矢量1和一个零矢量 但是,使这些向量可调整应可以区分流行度偏差,从而具有更大的灵活性。为了最直接地说明所提出机制的有效性,我们在此处使用1和0的向量:

注意这里是 长尾项+1,热门项+0
其中
τ
(
v
i
)
τ(v_i)
τ(vi)表示映射函数,
τ
(
v
i
)
τ(v_i)
τ(vi)映射
v
i
v_i
vi 对应项i。一和零向量的大小与输入的大小相同,即
{
1
,
1
,
.
.
,
1
}
,
{
0
,
0
,
.
.
.
,
0
}
∈
R
d
\{1,1,..,1\},\{0,0,...,0\}∈R^d
{1,1,..,1},{0,0,...,0}∈Rd, d是输入的维度。
然后我们采用注意力机制来表示会话偏好
S
p
S_p
Sp:

其中
T
E
(
v
i
)
,
T
E
(
v
t
)
∈
R
d
TE(v_i), TE(v_t)∈R^d
TE(vi),TE(vt)∈Rd分别表示第i项和尾部编码器之后的最后一个项目的表示;
W
0
m
∈
R
1
×
d
W^m_ 0∈R1×d
W0m∈R1×d 和
W
1
m
,
W
2
m
∈
R
d
×
d
W^m_ 1,W^m_ 2∈R^{d×d}
W1m,W2m∈Rd×d是偏好注意机制中的权重机制; 矩阵
W
3
∈
R
2
d
×
1
W_3∈R^{2d×1}
W3∈R2d×1将两个组合的嵌入矢量压缩到潜空间
R
1
R1
R1 中;
b
m
∈
R
d
b^m∈R^d
bm∈Rd是偏置矢量;
α
i
m
α^m_i
αim 代表每个 项目i 的注意力权重系数。
之后,使用S形函数获取整流因子:
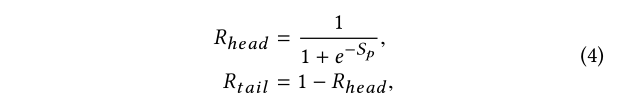
其中
R
h
e
a
d
和
R
t
a
i
l
R_{head}和R_{tail}
Rhead和Rtail分别表示与短头项目和长尾项目相对应的因子。
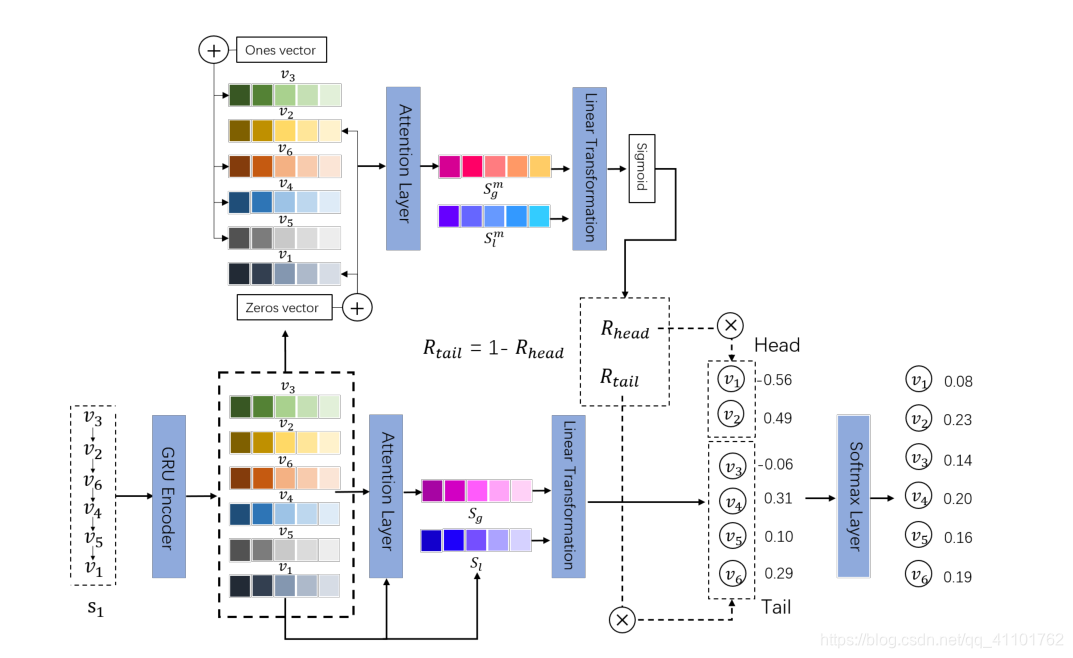
图1:TailNet的框架。我们首先通过GRU层对会话进行编码,然后获取会话的潜在表示V。然后将其发送到偏好机制和关注层。优先机制使用V生成整流因子
R
h
e
a
d
和
R
t
a
i
l
R_{head}和R_{tail}
Rhead和Rtail,从而软调整TailNet的模式。接下来,由关注层生成嵌入
S
g
S_g
Sg的全局会话。之后,将全局嵌入
S
g
S_g
Sg和局部嵌入
S
l
S_l
Sl (最后单击的项的表示)进行级联,然后发送给线性变换。最后,我们通过调整
R
h
e
a
d
和
R
t
a
i
l
R_{head}和R_{tail}
Rhead和Rtaill来预测每个项目的概率。
2.3 Session Pooling and Soft Adjustment
与上面的偏好机制相同,注意层和线性变换用于处理潜在表示V:
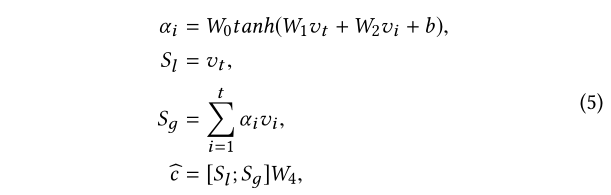
其中
W
0
,
W
1
,
W
2
,
W
4
W_0,W_1,W_2,W_4
W0,W1,W2,W4是权重矩阵,b是偏差矢量。
S
g
S_g
Sg代表全局嵌入,
V
t
V_t
Vt代表本地嵌入。与
S
g
m
S^m_g
Sgm 和
S
l
m
S^m_l
Slm 偏好设置机制不同,
S
g
S_g
Sg 和
S
l
S_l
Sl 代表用户对下次点击项的一般兴趣和当前兴趣。每个元素的值
c
^
=
{
c
^
1
,
c
^
2
,
.
.
.
,
c
^
∣
I
∣
}
\hat c = \{\hat c_1,\hat c_2,...,\hat c_{| I |}\}
c^={c^1,c^2,...,c^∣I∣}是softmax之前相应项目的分数
最后,为了调整推荐模式,我们将每个
c
^
i
\hat c_i
c^i 与对应的整流因子(
R
h
e
a
d
和
R
t
a
i
l
R_{head}和R_{tail}
Rhead和Rtail)相乘,然后对其应用softmax函数以获得推荐的概率:
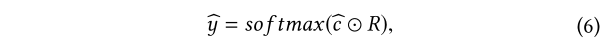
其中
R
∈
R
∣
I
∣
R∈R ^{| I |}
R∈R∣I∣是一个向量,并且它的每个元素的值都是
R
h
e
a
d
或
者
R
t
a
i
l
R_{head}或者R_{tail}
Rhead或者Rtail对应于头或尾中的项,例如
R
=
{
R
h
e
a
d
,
R
t
a
i
l
,
.
.
.
,
R
t
a
i
l
}
R = \{R_{head},R_{tail},...,R_{tail}\}
R={Rhead,Rtail,...,Rtail}。 ⊙表示元素乘积。向量
y
^
∈
R
∣
I
∣
\hat y∈R ^{| I |}
y^∈R∣I∣的每个元素的值是相应项目的推荐分数。建议将向量值中具有前K个值的项目作为最终输出。另外,TailNet是通过时间反向传播(BPTT)与偏好机制共同训练的。我们将每个项目的预测的交叉熵与基本事实的和作为损失:
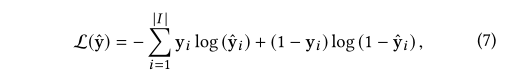
其中 y 表示基本事实的独热编码矢量。
3 EXPERIMENTS
我们在两个真实的数据集上评估了我们提出的方法:YOOCHOOSE 和 30MUSIC 。为了公平地比较,我们使用与以前的研究相同的数据预处理方法。我们使用YOOOCHOOSE数据集的最近分数1/4作为[20]。对于这两个数据集,我们使用最后一天来生成测试数据。由于协作过滤方法无法推荐在[6]之前没有出现过的项目,因此我们在测试数据中过滤掉了此类项目。根据帕累托原理[2],我们将项目集分为短头项目和长尾项目。
Baseline
我们将TailNet与基于频率的方法(POP和S-POP),
两种基于RNN的方法(GRU4REC [6]和NARM [9]),
基于邻域的方法(Item-KNN [18]),
重复探索方法(RepeatNet [15]),
基于注意力的方法(STAMP [10]),
两种传统的矩阵分解或马尔可夫链方法(FPMC [17]和BPR-MF [16])
基于GNN的方法(SR-GNN [23]) 。
Evaluation Metrics评估指标
我们使用
R
e
c
a
l
l
@
K
和
M
R
R
@
K
Recall @ K和MRR @ K
Recall@K和MRR@K 来评估所有算法的准确性。
对于长尾推荐的评估,我们在评估中采用了三个多样性指标。
• Coverage@K and Tail-Coverage@K: Coverage @ K和Tail-Coverage @ K分别衡量在前K个推荐中出现了多少个不同的项目和长尾项目。 Coverage @ K和Tail-Coverage @ K定义为:
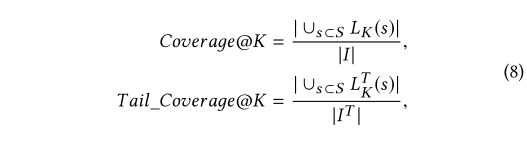
其中
L
K
(
s
)
=
[
i
1
,
i
2
,
.
.
.
,
i
k
]
L_K(s)= [i_1,i_2,...,i_k]
LK(s)=[i1,i2,...,ik]代表会话s的前K个推荐项目列表,而
L
K
T
(
s
)
L^T_K(s)
LKT(s)代表
L
K
(
s
)
L_K(s)
LK(s)的子集,该子集包含属于
∣
I
T
∣
| I^T |
∣IT∣的项目。
•Tail@K:Tail@K测量每个推荐列表的前K个中有多少个长尾项目。通过对所有测试用例求平均值来定义整个Tail @ K
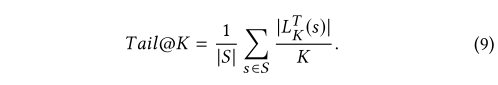
4 RESULTS AND ANALYSIS
4.1 Comparison with Baseline Methods
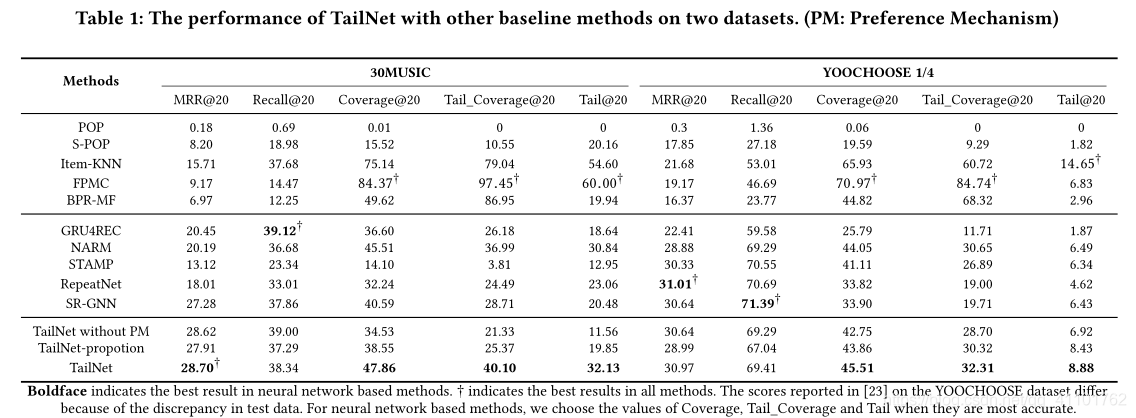
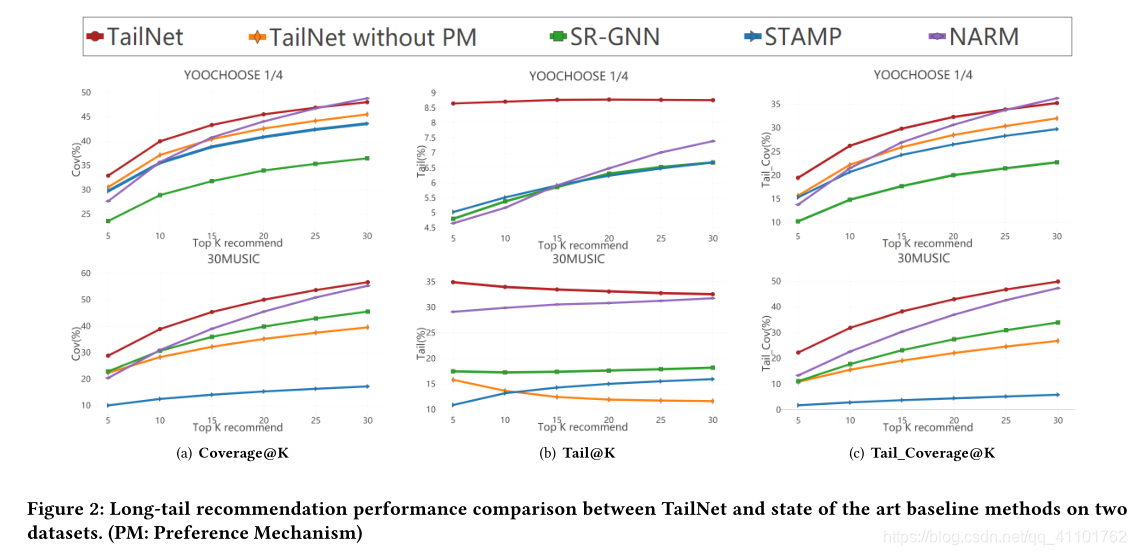
表1显示了TailNet和所有基线方法在两个数据集上的结果,图2显示了TailNet和其他基于top-K推荐的基于神经网络的方法之间的更具体比较。
传统方法的准确性相对低于基于神经网络的方法。但是,大多数传统方法在长尾推荐方面的性能要优于基于神经网络的方法。该结果表明,仅使用准确性来评估推荐算法的质量可能不够。此外,准确性和长尾推荐之间的权衡突出了平衡这两个指标的挑战。在这两个数据集中,TailNet在最先进的深度学习方法中均实现了最佳的长尾推荐性能,在传统方法中均获得了最佳的准确性,这证实了我们提出的方法提出了更全面的建议。显然,没有任何基线方法可以平衡长尾建议和准确建议以及TailNet。
尽管我们的工作主要集中在解决长尾推荐上,但TailNet在MRR@20,Recall@20方面仍然取得可比的结果。该结果表明,偏好机制的应用只会使准确性产生一些波动。偏好机制可以准确地确定长尾项和短头项之间的用户偏好,并适当地调整推荐结果,而不仅仅是不管用户的偏好如何严格推荐更多的利基项。
4.2 The Effect of Soft Adjustment
TailNet可以利用偏好机制生成的校正因子来轻柔地调整推荐分数。但是,由于我们根据帕累托原理对短头物品和长尾物品进行了划分,因此我们不能排除TailNet的竞争绩效很大程度上取决于此先验知识的可能性。因此,我们设计了TailNet的硬调整版本,即TailNet proportion,以研究仅基于帕累托原理的模型的效果。具体来说,对于前k个推荐,TailNet-portion通过组合顶部
[
k
∗
p
]
[k ∗ p]
[k∗p]个短头项和顶部
k
−
[
k
∗
p
]
k-[k ∗ p]
k−[k∗p]个长尾项生成推荐列表,然后根据得分对它们进行排序。
p表示会话中短头项目的比例,[·]表示舍入函数。从表1中可以看出,TailNet在所有指标上都优于TailNet比例,这证明了软调整而非帕累托原理在TailNet中起着重要作用。
4.3 Application of Preference Mechanism in Other Models
我们提出的偏好机制可以轻松地与其他基于神经网络的模型集成,以改善长尾推荐的性能(该机制只需要将模型生成的会话的潜在表示作为输入,然后输出校正因子
R
h
e
a
d
和
R
t
a
i
l
R_{head}和R_{tail}
Rhead和Rtail即可) 。
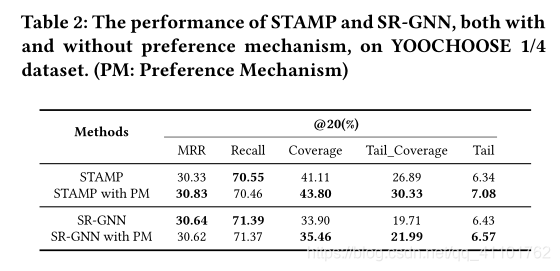
为了验证这一点,我们将偏好机制集成到了两个最先进的基线模型中:STAMP和SR-GNN,并在具有和没有偏好机制的那些模型之间进行了比较。如表2所示,STAMP和SR-GNN在应用了优先机制后获得了显着改进,这验证了优先机制的可移植性。通过采用偏好机制,基于神经网络的方法可以克服长尾推荐中的信息不足障碍。与TailNet的性能类似,偏好机制以较小的精度波动范围改进了STAMP和SR-GNN的长尾推荐,从而进一步验证了根据用户偏好软调整推荐结果的有效性。














 2273
2273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









