







MobileNet+SSD使用HLS的卷积优化记录
深度卷积单独的优化:
下面是量化之后的使用16bit的定点数进行深度卷积计算的HLS源码:
//
#include "dep_conv.h"
void dep_conv(short bottom[], int Cw, int Hin, int Win,
short weight[], int K, int pad, int S,
short top[], short bias[])
{
Channel_out_num: for(cnum = 0; cnum < Cw; cnum+=32)
{
#pragma HLS LOOP_TRIPCOUNT min=1 max=32
//weight的赋值
Load_W_c:for(cc = 0; cc < 32; cc++)
Load_W_kx:for(kkx = 0; kkx < 3; kkx++)
Load_W_ky:for(kky = 0; kky < 3; kky++)
wb[cc][kkx][kky] = weight[(cnum+cc) * K * K + kkx * K + kky];
Row_out: for(h = 0; h < Hout; h++)
{
#pragma HLS LOOP_TRIPCOUNT min=10 max=150
Column_out: for(w = 0; w < Wout; w++)
{
#pragma HLS LOOP_TRIPCOUNT min=10 max=150
//bottom的赋值
Load_B_c:for(cc = 0; cc < 32; cc++)
{
Load_B_h:for(hh = 0; hh < 3; hh++)
{
Load_B_w:for(ww = 0; ww < 3; ww++)
{
hi = h * S - pad + hh;
wi = w * S - pad + ww;
if(hi >= 0 && wi >= 0 && hi < Hin && wi < Win)
bb1[cc][hh][ww] = bottom[(cnum+cc) * Hin * Win + hi * Win + wi];
}
}
}
Channel_out: for(cw = 0; cw < 32; cw++)
{
Kernel_row: for(kx = 0; kx < 3; kx++)
{
Kernel_col: for(ky = 0; ky < 3; ky++)
{
if(bb1[cw][kx][ky] * wb[cw][kx][ky] < 0)
tb[cw] += (bb1[cw][kx][ky] * wb[cw][kx][ky] + 1023) >> 10;
else
tb[cw] += (bb1[cw][kx][ky] * wb[cw][kx][ky]) >> 10;
}
}
tb[cw] += biab[cw];
//深度卷积都要做relu操作
tb[cw] = (tb[cw] < 0) ? 0 : tb[cw];
}
Load_T_c:for(cw = 0; cw < 32; cw++)
top[(cnum+cw) * Hout * Wout + h * Wout + w] = tb[cw];
}
}
}
}
将深度卷积的输入和权重都划分成32x3x3的小块进行卷积计算得到32个数的输出,因为在MobileNet的13层深度卷积中,最小层卷积核就是32x3x3,其他层卷积核都是这个小卷积核的倍数且都是3x3的。
对卷积进行循环分块,但没有任何优化:

发现Channel_out_num的循环tripcount应该是1-32,而不是32-1024,下面是修改之后的综合报告:
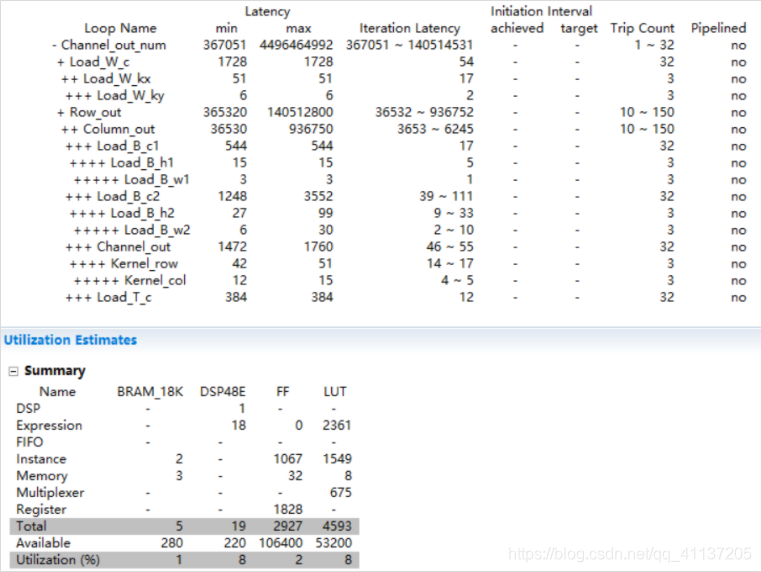
Load_T_c: 12x32=384
Kernel_col: 4x3=12 Kernel_row: 12x3+2x3=42 Channel_out: 42x32+4x32=1472
Load_B_w2: 2x3=6 Load_B_h2: 6x3+3x3=27 Load_B_c2: 27x32+12x32=1248
Load_B_w1: 1x3=3 Load_B_h1: 3x3+2x3=15 Load_B_c1: 15x32+2x32=544
Column_out: (1248+544+1472+384)x10+5x10 = 36530
Row_out: 36530x10+2x10=365320
Load_W_ky: 2x3=6 Load_W_kx: 6x3+11x3=51 Load_W_c: 51x32+3x32=1728
Channel_out_num: (365320+1728)x1+3x1=367051
对bb、wb、tb、biab进行完全循环分块,对计算的三层循环32x3x3都进行unroll后:

DSP48E和LUT使用率过高了,怎么没有使用BRAM?
Load_T_c: 12x32=384
//Kernel_col: 4x3=12 Kernel_row: 12x3+2x3=42 Channel_out: 42x32+4x32=1472
Load_B_w2: 2x3=6 Load_B_h2: 6x3+3x3=27 Load_B_c2: 27x32+13x32=1280
Load_B_w1: 2x3=6 Load_B_h1: 6x3+2x3=24 Load_B_c1: 24x32+2x32=832
Column_out: (1280+832+384)x10+14x10 = 25100
Row_out: 25100x10+2x10=251020
Load_W_ky: 2x3=6 Load_W_kx: 6x3+11x3=51 Load_W_c: 51x32+3x32=1728
Channel_out_num: (251020+1728)x1+3x1=252751
对三层循环的外一层循环进行pipeline:
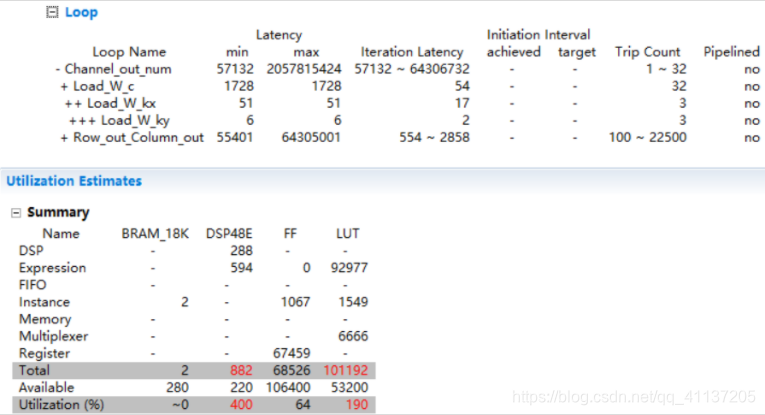
延迟减少了,但DSP48E和LUT使用率继续增高
原因:并行度为32x3x3=288所用乘法器太多了,总共只有220个乘法器,且三种卷积若设计成三个ip,使用的资源不能共用。也就是说,在第一层conv0进行计算时,标准卷积ip被使用,但点卷积和深度卷积ip就会空置,占着资源但没有用上,这样会非常的浪费资源,但又由于三者的并行优化非常的不同,故将占用计算量和内存最多的点卷积单独写成ip,而普通卷积和深度卷积写成同一个ip,进行计算资源的复用。

















 2897
2897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









