









数据类型
自定义精度整形:
ap_int<4> in1, in2;
ap_int<8> concat;
concat = (in1, in2); // in1和in2拼起来(按照补码拼起来)
/*
例子:
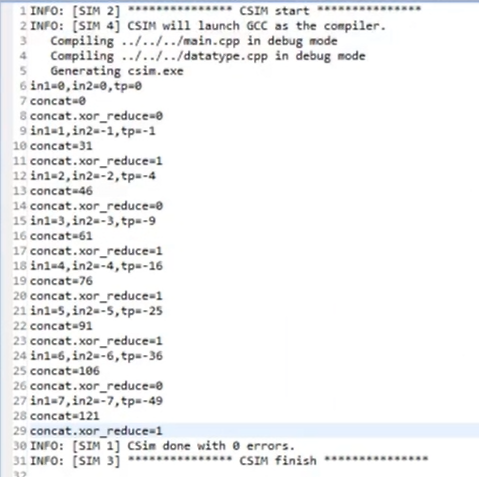
in1 = 1, in2 = -1
补码:
in1 = 0001
in2 = 1001 ==> 1110+1 ==> 1111
concat = 00011111 = 31
*/
concat.xor_reduce(); // 按位异或
自定义定点数
为了替换float,double类型的数,加快运算,节约资源
ap_fixed<11, 6> Var1 = 22.96875; // 一共11个bit,其中6个bit表示整数,5个bit表示小数;剩一个bit表示正负数
ap_ufixed<12, 11> Var2 = 512.5; // 一共12个bit,11位表示整数,最后一位表示小数

卷积的量化或定点化
根据输入的数据,找到卷积层的数据范围
A= aaaaaaaaaaaaaaaa, fix_point=12
B= bbbbbbbbbbbbbbbb, fix_point=13
C= ????????????????, fix_point=13
????????????????*(2^13)=A*B/2^(12+13)
求C的编码:????????????????
= A*B/2^(12+13-13)
= A*B/2^(fix_pointA + fix_pointB – fix_pointC)
例子:
A:0010.1100 = 44/16 = 2+0.5+0.25 = 2.75 fix_point = 4
B:00101.100 = 44/8 = 5+0.5 = 5.5 fix_point = 3
C:????.???? Fix_point = 4
A*B =44*44 = 011110010000 == 右移(3+4) = 01111.0010000 = 15.125
一共有(3+4)位小数,但是C的精度是4,所以需要把多余的小数移出去
移出去的位数就是(3+4-4) = 3
所以C = 1111.0010 fix_point = 4
自定义卷积
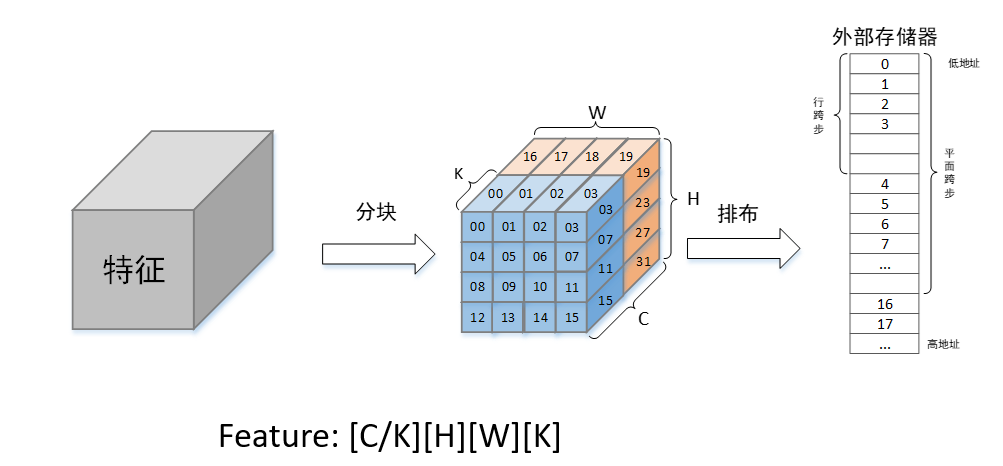
特征的内存排布方式
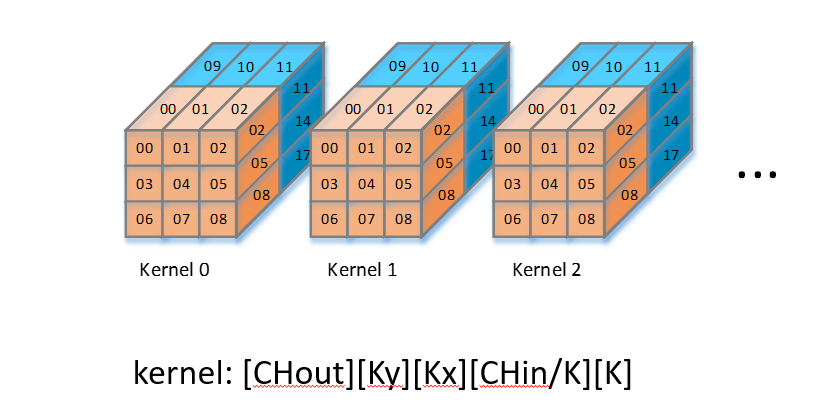
权重的内存排布方式
卷积的大小不固定,需要根据在内存中的排布方式算出地址
新建conv_core项目
conv_core.h
#ifndef __CONV_CORE_H__
#define __CONV_CORE_H__
#include <ap_int.h>
#include <iostream>
using namespace std;
#define K 8
typedef ap_int<16> data_type; // 单个数据的大小
typedef ap_int<16*K> tile_type; // 分块数据的大小
typedef ap_int<32> mul_type; // 两个数据相乘的数据大小:16*16==>32
typedef ap_int<32*K> mul_tile_type; // 分块数据相乘的大小
typedef ap_int<40> acc_type; // 一次卷积内的数据相加后的大小,按照经验推断
// 卷积的定义
void conv_core(
ap_uint<16> in_channel, // 输入特征的通道数
ap_uint<16> in_height, // 输入特征高度
ap_uint<16> in_width, // 输入特征宽度
ap_uint<16> out_channel, // 输出特征通道数
// 卷积核参数
ap_uint<8> kernel_width, // 卷积核宽度
ap_uint<8> kernel_height, // 卷积核高度
ap_uint<8> stride_x, // 宽度方向步长
ap_uint<8> stride_y, // 高度方向步长
ap_uint<1> padding_mode, // 卷积的模式; 0: valid(没有padding填充), 1:same(输入输出的图大小不变)
ap_uint<1> relu_en, // 激活函数
tile_type input_feature[], ap_uint<4> input_feature_precision, // 输入特征图地址和精度(小数点位置)
tile_type weight[], ap_uint<4> weight_precision,// 权重地址和精度(小数点位置)
tile_type output_feature[], ap_uint<4> out_feature_precision// 输出特征图地址和精度(小数点位置)
);
#endif
conv_core.cpp
#include "conv_core.h"
void conv_core(
// 特征图参数
ap_uint<16> in_channel, // 输入特征的通道数
ap_uint<16> in_height, // 输入特征高度
ap_uint<16> in_width, // 输入特征宽度
ap_uint<16> out_channel, // 输出特征通道数
// 卷积核参数
ap_uint<8> kernel_width, // 卷积核宽度
ap_uint<8> kernel_height, // 卷积核高度
ap_uint<8> stride_x, // 宽度方向步长
ap_uint<8> stride_y, // 高度方向步长
ap_uint<1> padding_mode, // 卷积的模式; 0: valid(没有padding填充), 1:same(输入输出的图大小不变)
ap_uint<1> relu_en, // 激活函数
tile_type input_feature[], ap_uint<4> input_feature_precision, // 输入特征图地址和精度(小数点位置)
tile_type weight[], ap_uint<4> weight_precision,// 权重地址和精度(小数点位置)
tile_type output_feature[], ap_uint<4> out_feature_precision// 输出特征图地址和精度(小数点位置)
)
{
// Feature: [CHin/K][H][W][K]
// Weight: [CHout][CHin/K][KH][KW][K]
// 根据卷积模式,计算padding
ap_uint<8> padding_x, padding_y;
if(padding_mode == 0){
padding_x = padding_y = 0;
}else{
padding_x = (kernel_width-1)/2;
padding_y = (kernel_height-1)/2;
}
// 计算分块个数
ap_uint<16> div_tile_num = (in_channel + K-1) / K;
// 计算输出截断精度
ap_uint<5> out_truncate = input_feature_precision + weight_precision - out_feature_precision;
/*
* [x x x] x x x
* x x [x x x] x
*/
// 计算输出宽度和高度
ap_uint<16> out_width = (in_width + padding_x*2) / stride_x + 1;
ap_uint<16> out_height = (in_height + padding_y*2) / stride_y + 1;
// 选择输出特征的第y行,第x列,第c_out个输出通道的数据
// 选择第c_out个权重的第y行,第x列,第tile_index个分块
LOOP_out_channel:
for(int out_index = 0; out_index < out_channel; ++ out_index){
LOOP_out_height:
for(int i = 0; i < out_height; ++ i){
LOOP_out_width:
for(int j = 0; j < out_width; ++ j){
// 相乘结果累加
acc_type sum=0;
// 计算输出特征中一个tile的数据
ap_int<16> out_tile = 0;
LOOP_kernel_height:
for(int kh = 0; kh < kernel_height; ++ kh){
LOOP_kernel_width:
for(int kw = 0; kw < kernel_width; ++ kw){
LOOP_div_tile_num:
for(int tile_index = 0; tile_index < div_tile_num; ++ tile_index){
// 获取计算点
ap_uint<16> in_h = i*stride_y-padding_y + kh;
ap_uint<16> in_w = j*stride_x-padding_x + kw;
// 获取输入特征和权重的一个块数据
tile_type data_tile, weight_tile;
// 有padding会越界
if(in_h >= 0 && in_h < in_height && in_w >= 0 && in_w < in_width){
data_tile = input_feature[in_width*in_height*tile_index + in_width*in_h + in_w];
weight_tile = weight[kernel_width*kernel_height*div_tile_num*out_index
+ kernel_width*kernel_height*tile_index
+ kernel_width*kh+kw];
}else{
data_tile = 0; weight_tile = 0;
}
// 块数据相乘
mul_tile_type mul_tile_data;
for(int k = 0; k < K; ++ k)
mul_tile_data.range(k*32+31, k*32) =
(data_type)data_tile.range(k*16+15, k*16)*
(data_type)weight_tile.range(k*16+15, k*16);
// 相乘结果累加
for(int k = 0; k < K; ++ k)
sum += (mul_tile_type)mul_tile_data.range(k*32+31, k*32);
}
}
}
// 激活函数
if(relu_en & sum < 0) sum = 0;
// 截断多余精度
acc_type res = sum >> out_truncate;
if (res > 32767)
res = 32767;
else if (res < -32768)
res = -32768;
out_tile.range((out_index % K) * 16 + 15, (out_index % K) * 16) = res;
// 存tile里的一个数据
// 一个tile都存完了或者存到最后一个通道凑不够一个tile
if((out_index%K) == K - 1 || out_index == (out_channel - 1))
output_feature[(out_index/K)*out_width*out_height + out_width*i+j] = out_tile;
}
}
}
}
main.cpp
#include "stdio.h"
#include "conv_core.h"
#define IN_WIDTH 10
#define IN_HEIGHT 10
#define IN_CHANNEL 1
#define IN_DIV_TILE_NUM ((IN_CHANNEL+K-1)/K)
#define KERNEL_WIDTH 5
#define KERNEL_HEIGHT 5
#define STRIDE_X 1
#define STRIDE_Y 1
#define RELU_EN 0
#define PADDING_MODE 0 // 0:valid 1:same
#define PADDING_X (PADDING_MODE?(KERNEL_WIDTH-1)/2:0)
#define PADDING_Y (PADDING_MODE?(KERNEL_HEIGHT-1)/2:0)
#define OUT_CHANNEL 1
#define OUT_WIDTH ((IN_WIDTH+PADDING_X*2-KERNEL_WIDTH)/STRIDE_X+1)
#define OUT_HEIGHT ((IN_HEIGHT+PADDING_Y*2-KERNEL_HEIGHT)/STRIDE_Y+1)
#define OUT_DIV_TILE_NUM ((OUT_CHANNEL+K-1)/K)
int main(void)
{
tile_type input_feature[IN_DIV_TILE_NUM][IN_HEIGHT][IN_WIDTH];
tile_type weight[OUT_CHANNEL][IN_DIV_TILE_NUM][KERNEL_HEIGHT][KERNEL_WIDTH];
tile_type output_feature[OUT_DIV_TILE_NUM][OUT_HEIGHT][OUT_WIDTH];
for(int tile_index = 0; tile_index < IN_DIV_TILE_NUM; ++ tile_index){
for(int i = 0; i < IN_HEIGHT; ++ i){
for(int j = 0; j < IN_WIDTH; ++ j){
for(int k = 0; k < K; ++ k){
// 可能除不尽
if(tile_index*K+k < IN_CHANNEL)
input_feature[tile_index][i][j].range(k*16+15, k*16) = (1<<14);
else
input_feature[tile_index][i][j].range(k*16+15, k*16) = 0;
}
}
}
}
for(int out_index = 0; out_index < OUT_CHANNEL; ++ out_index){
for(int tile_index = 0; tile_index < OUT_DIV_TILE_NUM; ++ tile_index){
for(int i = 0; i < OUT_HEIGHT; ++ i){
for(int j = 0; j < OUT_WIDTH; ++j){
for(int k = 0; k < K; ++ k){
// 输入特征赋值为0,特征值就不用考虑除不尽的问题
weight[out_index][tile_index][i][j].range(16*k+15, 16*k) = (1<<14);
}
}
}
}
}
for(int tile_index = 0; tile_index < OUT_DIV_TILE_NUM; ++ tile_index){
for(int i = 0; i < OUT_HEIGHT; ++ i){
for(int j = 0; j < OUT_WIDTH; ++ j){
output_feature[tile_index][i][j] = 0;
}
}
}
printf("initial down\n");
conv_core(IN_CHANNEL, IN_HEIGHT, IN_WIDTH, OUT_CHANNEL,
KERNEL_WIDTH, KERNEL_HEIGHT,
STRIDE_X, STRIDE_Y,
PADDING_MODE, RELU_EN,
&input_feature[0][0][0], 14,
&weight[0][0][0][0], 14,
&output_feature[0][0][0], 10
);
for(int tile_index = 0; tile_index < OUT_DIV_TILE_NUM; ++ tile_index){
for(int i = 0; i < OUT_HEIGHT; ++ i){
for(int j = 0; j < OUT_WIDTH; ++ j){
cout << "out[" << tile_index <<"]["<<i<<"]["<<j<<"]="<<
(data_type)output_feature[tile_index][i][j].range(15, 0) << "\t";
}
cout << endl;
}
}
return 0;
}
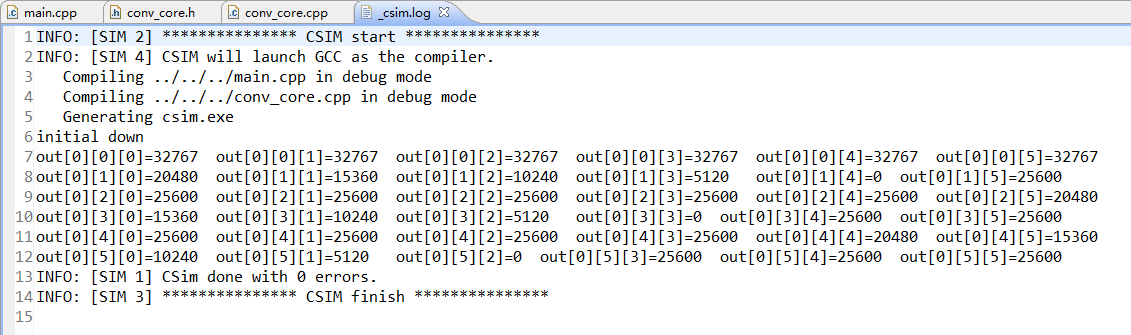
运行
C仿真结果:
C综合:
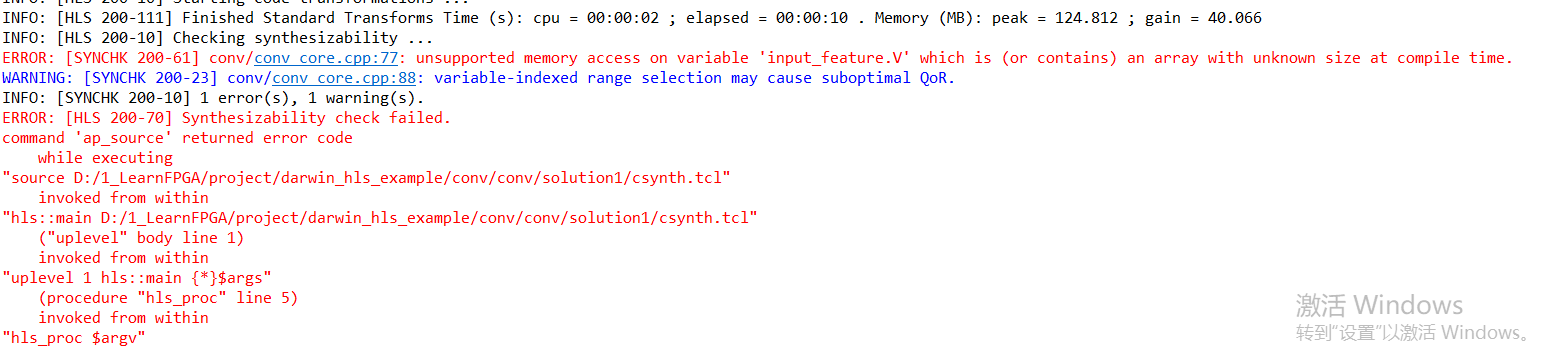
出错了,需要加约束。报错信息:输入特征feature_in是没有固定长度的
但是我们只是把input_feature当作基地址,而不是数组,所以需要告诉工具,数据来自外部存储器
数据接口约束
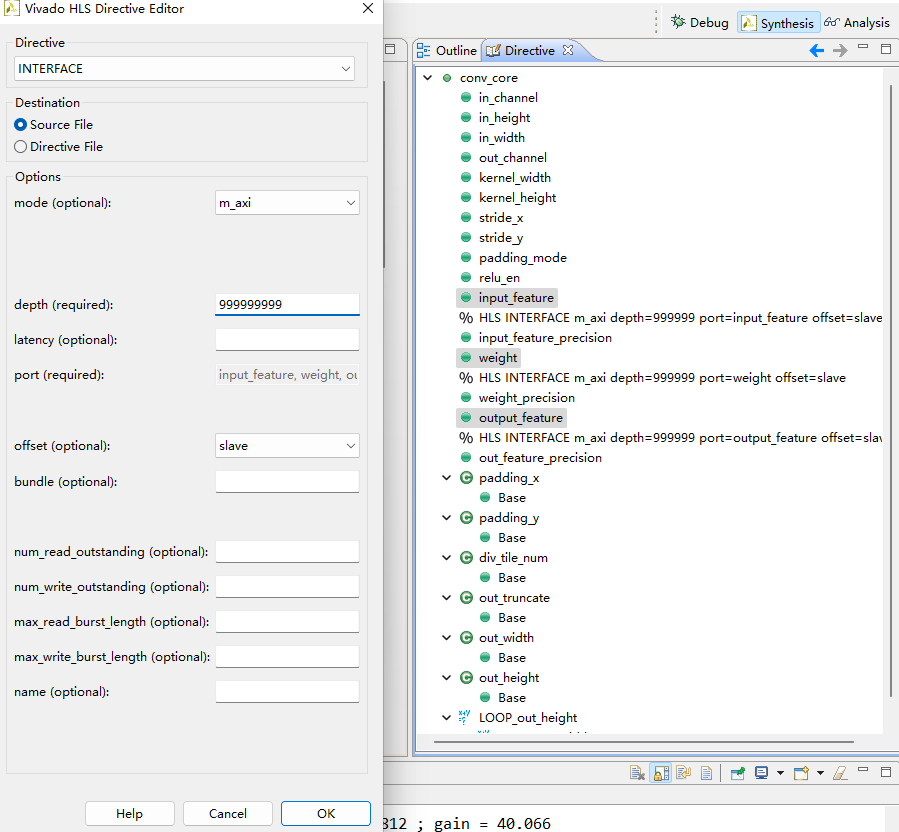
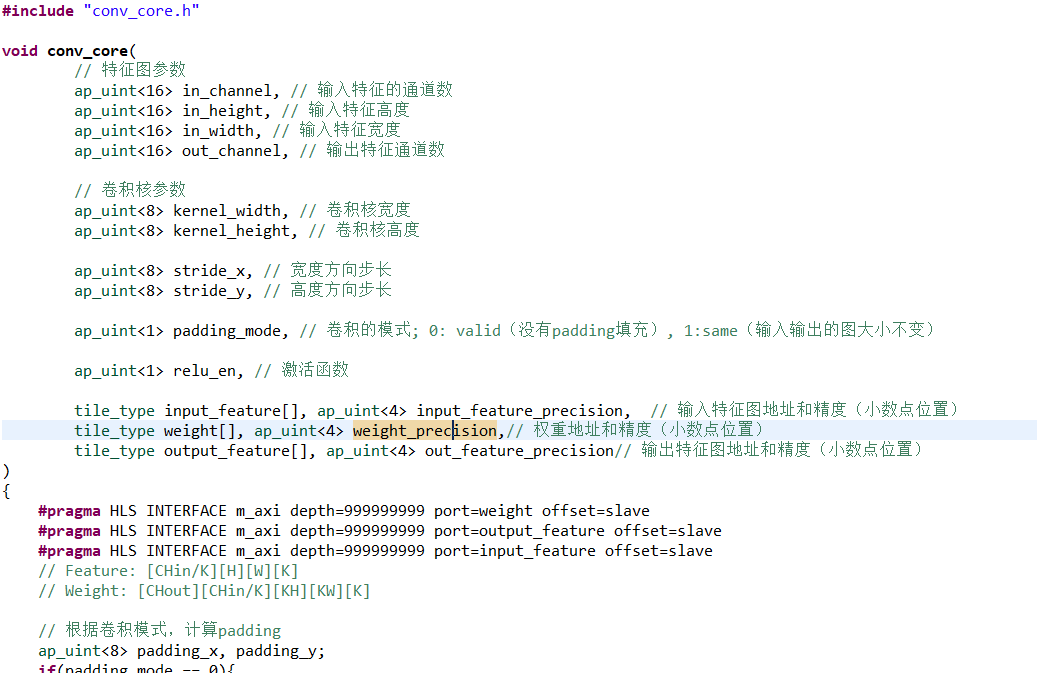
#pragma HLS INTERFACE m_axi depth=999999999 port=weight offset=slave
#pragma HLS INTERFACE m_axi depth=999999999 port=output_feature offset=slave
#pragma HLS INTERFACE m_axi depth=999999999 port=input_feature offset=slave
再次C综合:
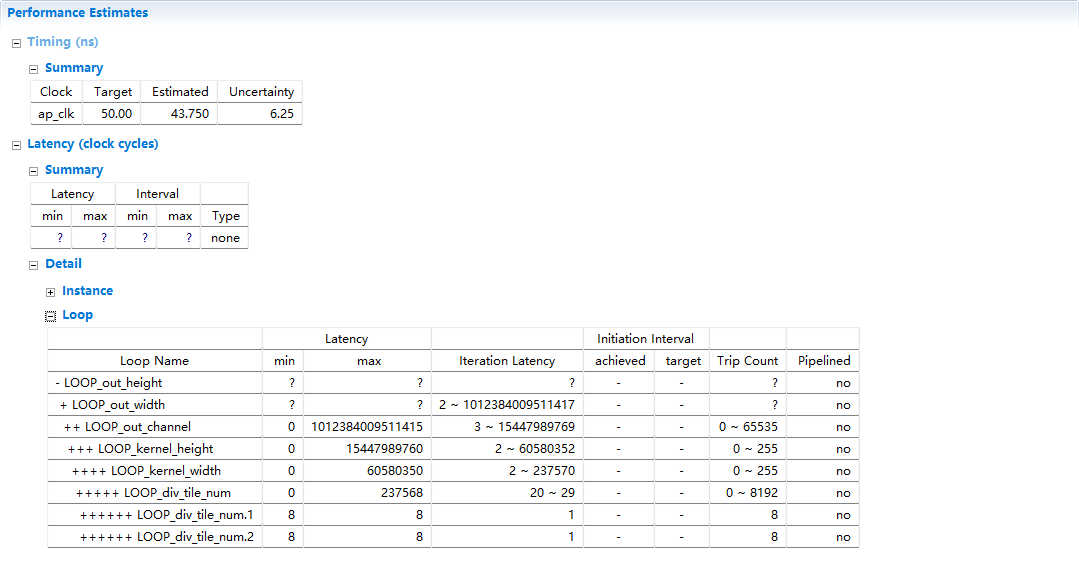
???是因为,循环次数是一个变量,工具无法估计性能
循环次数约束
那就根据test bench里的例子进行测试约束
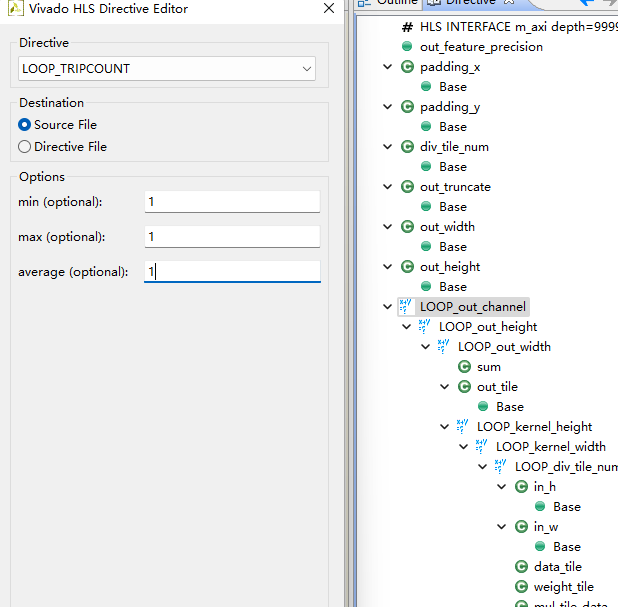
#include "conv_core.h"
void conv_core(
// 特征图参数
ap_uint<16> in_channel, // 输入特征的通道数
ap_uint<16> in_height, // 输入特征高度
ap_uint<16> in_width, // 输入特征宽度
ap_uint<16> out_channel, // 输出特征通道数
// 卷积核参数
ap_uint<8> kernel_width, // 卷积核宽度
ap_uint<8> kernel_height, // 卷积核高度
ap_uint<8> stride_x, // 宽度方向步长
ap_uint<8> stride_y, // 高度方向步长
ap_uint<1> padding_mode, // 卷积的模式; 0: valid(没有padding填充), 1:same(输入输出的图大小不变)
ap_uint<1> relu_en, // 激活函数
tile_type input_feature[], ap_uint<4> input_feature_precision, // 输入特征图地址和精度(小数点位置)
tile_type weight[], ap_uint<4> weight_precision,// 权重地址和精度(小数点位置)
tile_type output_feature[], ap_uint<4> out_feature_precision// 输出特征图地址和精度(小数点位置)
)
{
#pragma HLS INTERFACE m_axi depth=999999999 port=weight offset=slave
#pragma HLS INTERFACE m_axi depth=999999999 port=output_feature offset=slave
#pragma HLS INTERFACE m_axi depth=999999999 port=input_feature offset=slave
// Feature: [CHin/K][H][W][K]
// Weight: [CHout][CHin/K][KH][KW][K]
// 根据卷积模式,计算padding
ap_uint<8> padding_x, padding_y;
if(padding_mode == 0){
padding_x = padding_y = 0;
}else{
padding_x = (kernel_width-1)/2;
padding_y = (kernel_height-1)/2;
}
// 计算分块个数
ap_uint<16> div_tile_num = (in_channel + K-1) / K;
// 计算输出截断精度
ap_uint<5> out_truncate = input_feature_precision + weight_precision - out_feature_precision;
/*
* [x x x] x x x
* x x [x x x] x
*/
// 计算输出宽度和高度
ap_uint<16> out_width = (in_width + padding_x*2) / stride_x + 1;
ap_uint<16> out_height = (in_height + padding_y*2) / stride_y + 1;
// 选择输出特征的第y行,第x列,第c_out个输出通道的数据
// 选择第c_out个权重的第y行,第x列,第tile_index个分块
LOOP_out_channel:
for(int out_index = 0; out_index < out_channel; ++ out_index){
#pragma HLS LOOP_TRIPCOUNT min=1 max=1 avg=1
LOOP_out_height:
for(int i = 0; i < out_height; ++ i){
#pragma HLS LOOP_TRIPCOUNT min=10 max=10 avg=10
LOOP_out_width:
for(int j = 0; j < out_width; ++ j){
#pragma HLS LOOP_TRIPCOUNT min=10 max=10 avg=10
// 相乘结果累加
acc_type sum=0;
// 计算输出特征中一个tile的数据
ap_int<16> out_tile = 0;
LOOP_kernel_height:
for(int kh = 0; kh < kernel_height; ++ kh){
#pragma HLS LOOP_TRIPCOUNT min=5 max=5 avg=5
LOOP_kernel_width:
for(int kw = 0; kw < kernel_width; ++ kw){
#pragma HLS LOOP_TRIPCOUNT min=5 max=5 avg=5
LOOP_div_tile_num:
for(int tile_index = 0; tile_index < div_tile_num; ++ tile_index){
#pragma HLS LOOP_TRIPCOUNT min=1 max=1 avg=1
// 获取计算点
ap_uint<16> in_h = i*stride_y-padding_y + kh;
ap_uint<16> in_w = j*stride_x-padding_x + kw;
// 获取输入特征和权重的一个块数据
tile_type data_tile, weight_tile;
// 有padding会越界
if(in_h >= 0 && in_h < in_height && in_w >= 0 && in_w < in_width){
data_tile = input_feature[in_width*in_height*tile_index + in_width*in_h + in_w];
weight_tile = weight[kernel_width*kernel_height*div_tile_num*out_index
+ kernel_width*kernel_height*tile_index
+ kernel_width*kh+kw];
}else{
data_tile = 0; weight_tile = 0;
}
// 块数据相乘
mul_tile_type mul_tile_data;
for(int k = 0; k < K; ++ k)
mul_tile_data.range(k*32+31, k*32) =
(data_type)data_tile.range(k*16+15, k*16)*
(data_type)weight_tile.range(k*16+15, k*16);
// 相乘结果累加
for(int k = 0; k < K; ++ k)
sum += (mul_tile_type)mul_tile_data.range(k*32+31, k*32);
}
}
}
// 激活函数
if(relu_en & sum < 0) sum = 0;
// 截断多余精度
acc_type res = sum >> out_truncate;
if (res > 32767)
res = 32767;
else if (res < -32768)
res = -32768;
out_tile.range((out_index % K) * 16 + 15, (out_index % K) * 16) = res;
// 存tile里的一个数据
// 一个tile都存完了或者存到最后一个通道凑不够一个tile
if((out_index%K) == K - 1 || out_index == (out_channel - 1))
output_feature[(out_index/K)*out_width*out_height + out_width*i+j] = out_tile;
}
}
}
}
综合结果:

优化
最内层的块相乘只用两个周期完成
一个周期用来去input_tile,另一个取weight_tile,输出计算结果的同时,也在取数据
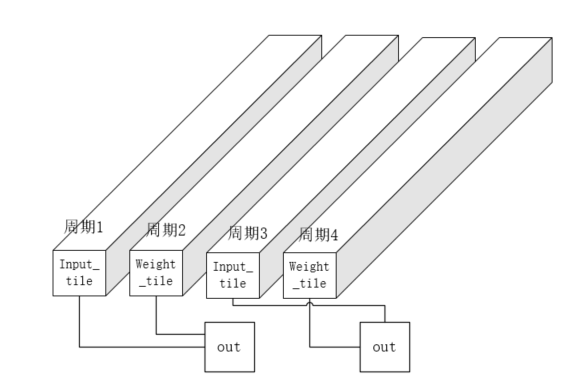
添加 pipeline 优化
迭代间隔 II = 2
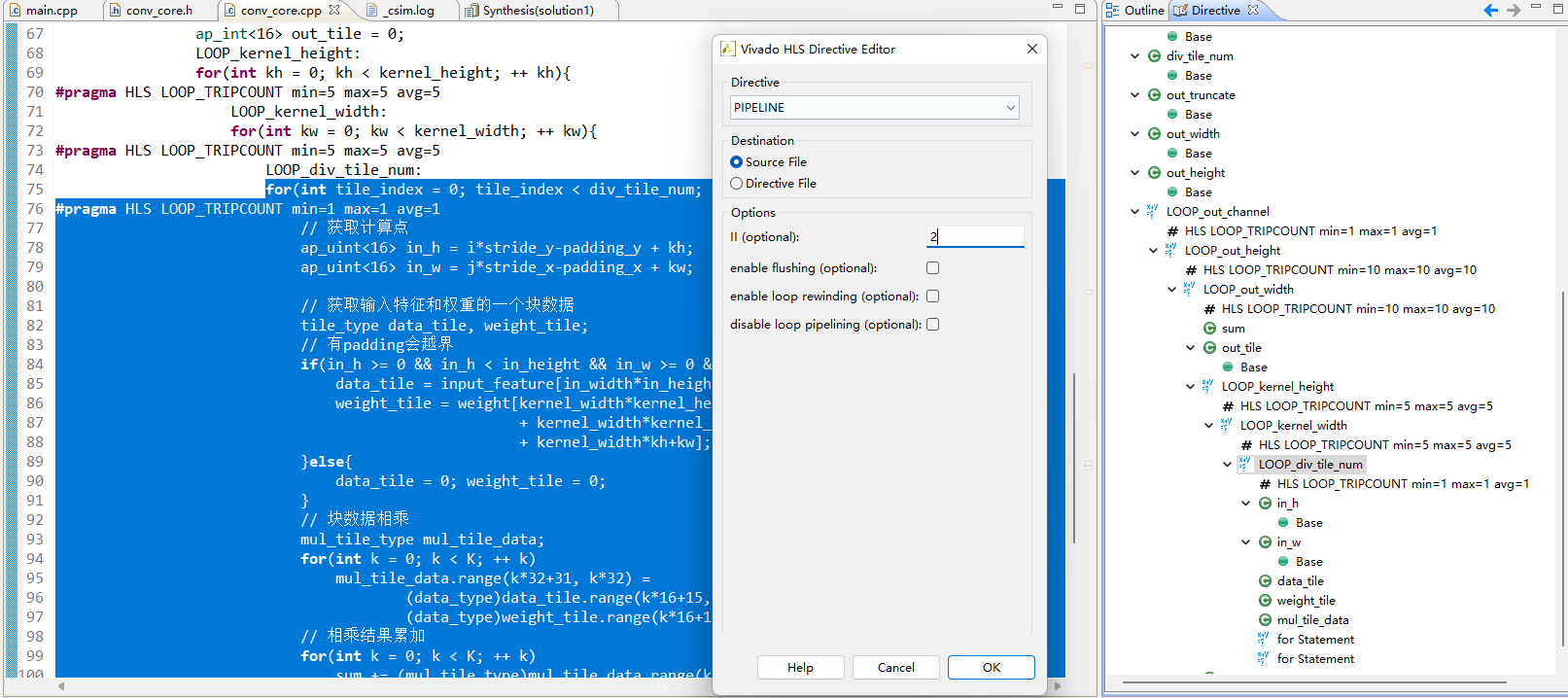
如果效果理想的话应该是 1*10*10*5*5*2=5000
但是综合结果并不是:

卷积一次:2*25 = 50
这里循环的latency是59,多了9个周期是迭代latency
但是顶层的迭代latency达到了70,其中多的11周期的计算在这里:
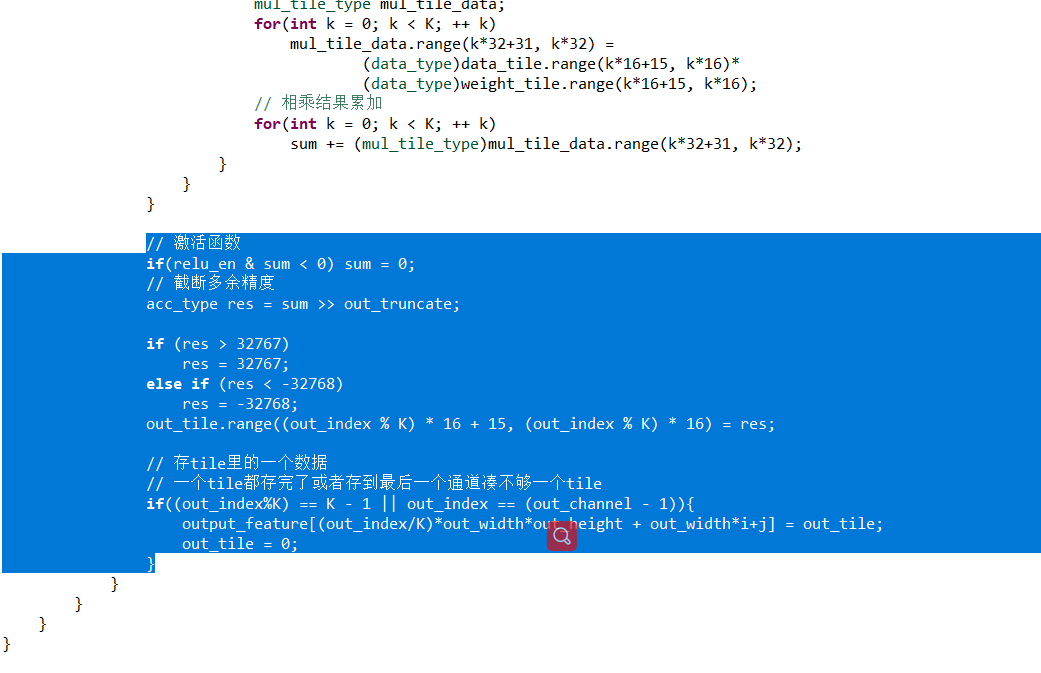
完美循环优化与计算顺序的调换
- 完美循环
使用if语句使循环之间没有代码,使得循环可以合并
从存储器取块数据相乘累加的运算,其实可以和计算结果的存储并行
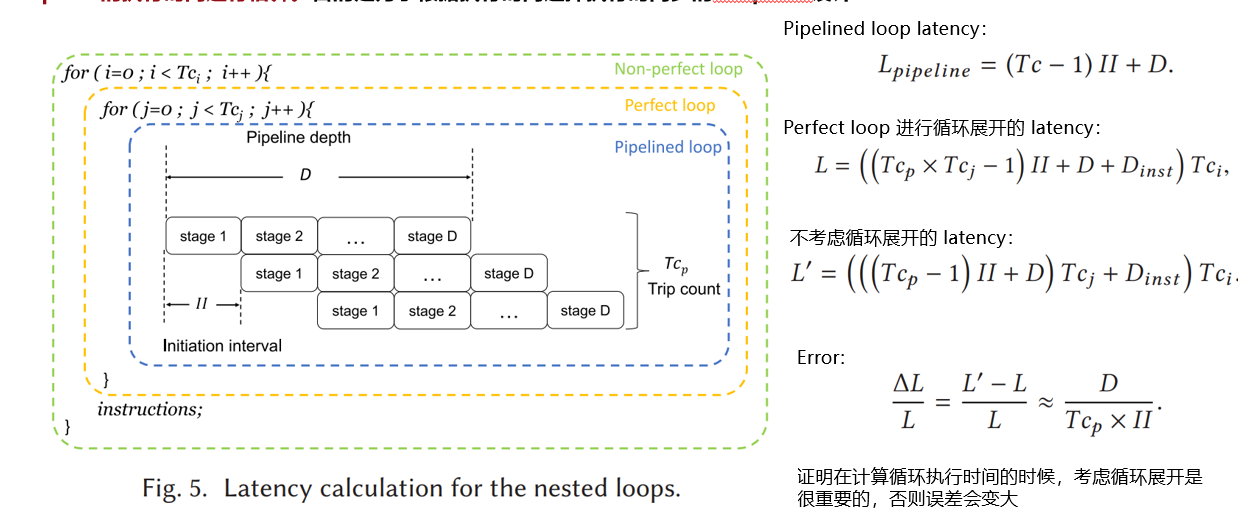
- 计算顺序调换
将out_channel挪到kernel_width上面,这样每计算完一次卷积tile,就判断一次对输出特征写计算结果
#include "conv_core.h"
void conv_core(
// 特征图参数
ap_uint<16> in_channel, // 输入特征的通道数
ap_uint<16> in_height, // 输入特征高度
ap_uint<16> in_width, // 输入特征宽度
ap_uint<16> out_channel, // 输出特征通道数
// 卷积核参数
ap_uint<8> kernel_width, // 卷积核宽度
ap_uint<8> kernel_height, // 卷积核高度
ap_uint<8> stride_x, // 宽度方向步长
ap_uint<8> stride_y, // 高度方向步长
ap_uint<1> padding_mode, // 卷积的模式; 0: valid(没有padding填充), 1:same(输入输出的图大小不变)
ap_uint<1> relu_en, // 激活函数
tile_type input_feature[], ap_uint<4> input_feature_precision, // 输入特征图地址和精度(小数点位置)
tile_type weight[], ap_uint<4> weight_precision,// 权重地址和精度(小数点位置)
tile_type output_feature[], ap_uint<4> out_feature_precision// 输出特征图地址和精度(小数点位置)
)
{
#pragma HLS INTERFACE m_axi depth=999999999 port=weight offset=slave
#pragma HLS INTERFACE m_axi depth=999999999 port=output_feature offset=slave
#pragma HLS INTERFACE m_axi depth=999999999 port=input_feature offset=slave
// Feature: [CHin/K][H][W][K]
// Weight: [CHout][CHin/K][KH][KW][K]
// 根据卷积模式,计算padding
ap_uint<8> padding_x, padding_y;
if(padding_mode == 0){
padding_x = padding_y = 0;
}else{
padding_x = (kernel_width-1)/2;
padding_y = (kernel_height-1)/2;
}
// 计算分块个数
ap_uint<16> div_tile_num = (in_channel + K-1) / K;
// 计算输出截断精度
ap_uint<5> out_truncate = input_feature_precision + weight_precision - out_feature_precision;
/*
* [x x x] x x x
* x x [x x x] x
*/
// 计算输出宽度和高度
ap_uint<16> out_width = (in_width + padding_x*2) / stride_x + 1;
ap_uint<16> out_height = (in_height + padding_y*2) / stride_y + 1;
// 计算输出特征中一个tile的数据
ap_int<16> out_tile = 0;
// 相乘结果累加
acc_type sum=0;
// 选择输出特征的第y行,第x列,第c_out个输出通道的数据
// 选择第c_out个权重的第y行,第x列,第tile_index个分块
LOOP_out_height:
for(int i = 0; i < out_height; ++ i){
#pragma HLS LOOP_TRIPCOUNT min=1 max=1 avg=1
LOOP_out_width:
for(int j = 0; j < out_width; ++ j){
#pragma HLS LOOP_TRIPCOUNT min=10 max=10 avg=10
LOOP_out_channel:
for(int out_index = 0; out_index < out_channel; ++ out_index){
#pragma HLS LOOP_TRIPCOUNT min=10 max=10 avg=10
LOOP_kernel_height:
for(int kh = 0; kh < kernel_height; ++ kh){
#pragma HLS LOOP_TRIPCOUNT min=5 max=5 avg=5
LOOP_kernel_width:
for(int kw = 0; kw < kernel_width; ++ kw){
#pragma HLS LOOP_TRIPCOUNT min=5 max=5 avg=5
LOOP_div_tile_num:
for(int tile_index = 0; tile_index < div_tile_num; ++ tile_index){
#pragma HLS PIPELINE II=2
#pragma HLS LOOP_TRIPCOUNT min=1 max=1 avg=1
// 获取计算点
ap_uint<16> in_h = i*stride_y-padding_y + kh;
ap_uint<16> in_w = j*stride_x-padding_x + kw;
// 获取输入特征和权重的一个块数据
tile_type data_tile, weight_tile;
// 有padding会越界
if(in_h >= 0 && in_h < in_height && in_w >= 0 && in_w < in_width){
data_tile = input_feature[in_width*in_height*tile_index + in_width*in_h + in_w];
weight_tile = weight[kernel_width*kernel_height*div_tile_num*out_index
+ kernel_width*kernel_height*tile_index
+ kernel_width*kh+kw];
}else{
data_tile = 0; weight_tile = 0;
}
// 块数据相乘
mul_tile_type mul_tile_data;
for(int k = 0; k < K; ++ k)
mul_tile_data.range(k*32+31, k*32) =
(data_type)data_tile.range(k*16+15, k*16)*
(data_type)weight_tile.range(k*16+15, k*16);
// 相乘结果累加
for(int k = 0; k < K; ++ k)
sum += (mul_tile_type)mul_tile_data.range(k*32+31, k*32);
if(tile_index == div_tile_num-1 && kh == kernel_height-1 && kw == kernel_width-1){
// 激活函数
if(relu_en & sum < 0) sum = 0;
// 截断多余精度
acc_type res = sum >> out_truncate;
if (res > 32767)
res = 32767;
else if (res < -32768)
res = -32768;
// 先缓存下来,下面一次写入
out_tile.range((out_index % K) * 16 + 15, (out_index % K) * 16) = res;
sum = 0;
// 存tile里的一个数据
// 一个tile都存完了或者存到最后一个通道凑不够一个tile
if((out_index%K) == K - 1 || out_index == (out_channel - 1)){
output_feature[(out_index/K)*out_width*out_height + out_width*i+j] = out_tile;
out_tile = 0;
}
}
}
}
}
}
}
}
}
C综合已经达到我们的预期了
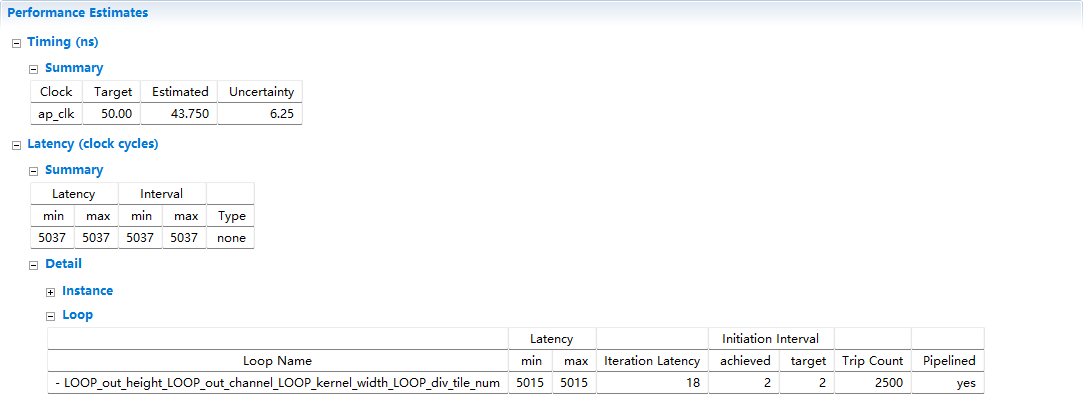
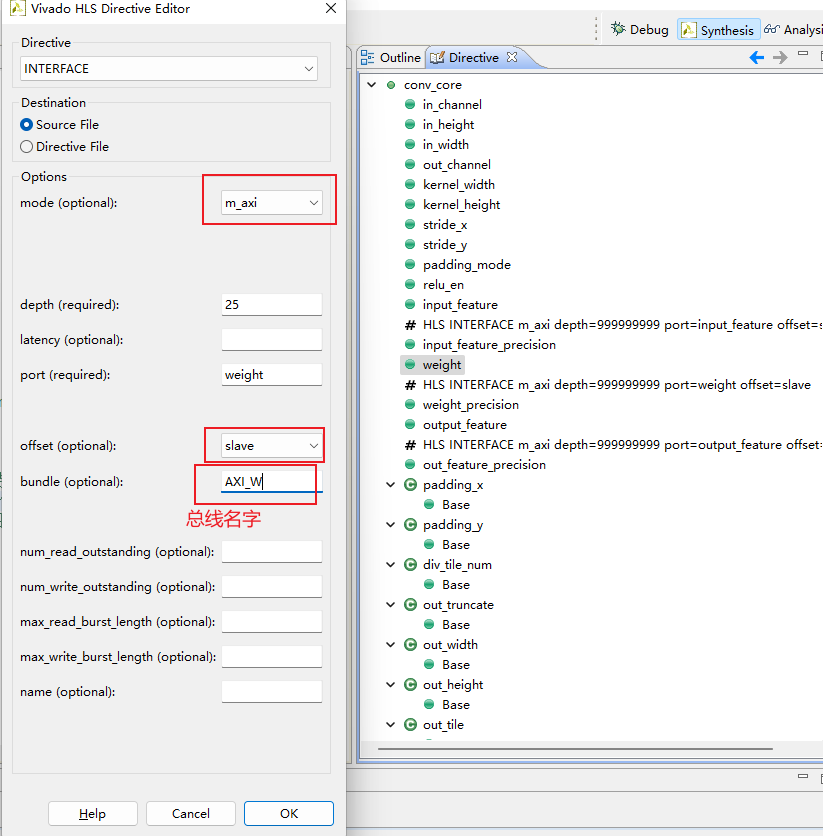
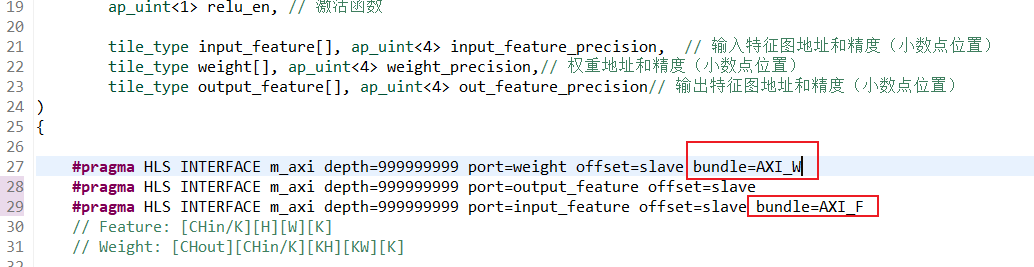
访问方式的优化-通道方向的并行
给特征图和权重分别分配一条总线,那么就可以同时取出两个数据,只需要一个周期就可以完成一次tile的计算
bundle:一捆,不选的话默认是同一个总线
所以这里我们给input_feature和weight取两个不同的名字,就给它们分配了不同的总线:
AXI是全双工的,可以同时写和读,但是同时读两个就不太行,读一个的同时写一个可以。所以不需要给output_feature分配一个总线
然后我们就可以在一个周期内运行一次tile计算,设置pipeline的II = 1:

也就是K个数据的乘法和累加,需要K个乘法器同时进行
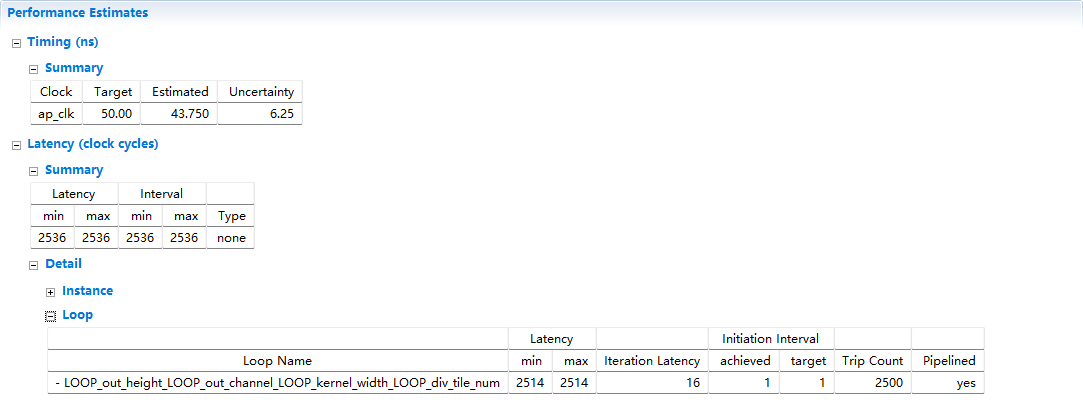
可以看出来是2500个周期:1*10*10*5*5*(1 clock)=2500














 984
984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









