








原文地址:https://arxiv.org/pdf/1506.02640.pdf

图片resize到统一尺寸后送入黑盒模型变成了一个7×7×30的张量。(尺寸可调,但这里不讨论这些细节!)
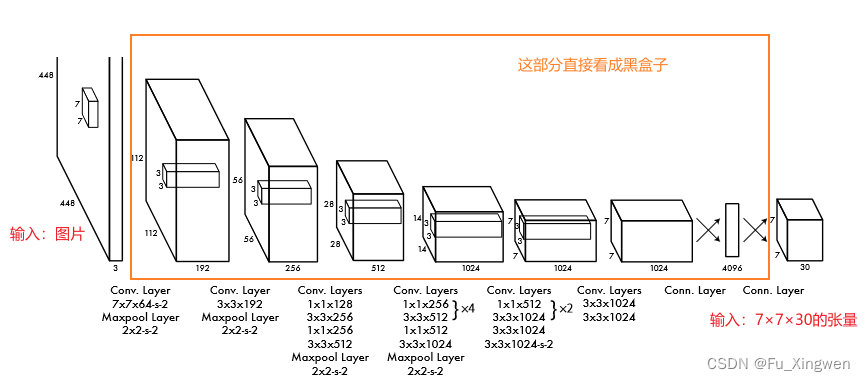
预测出来就是这样一堆数(尺寸为7×7×30)

(如果网络没有经过训练,输出的就是一堆随机数,经过训练后网络才知道在正确的地方输出正确的数,才能得到上图,那怎么训练网络呢?或者用什么来训练网络呢?我们就需要制作标签)
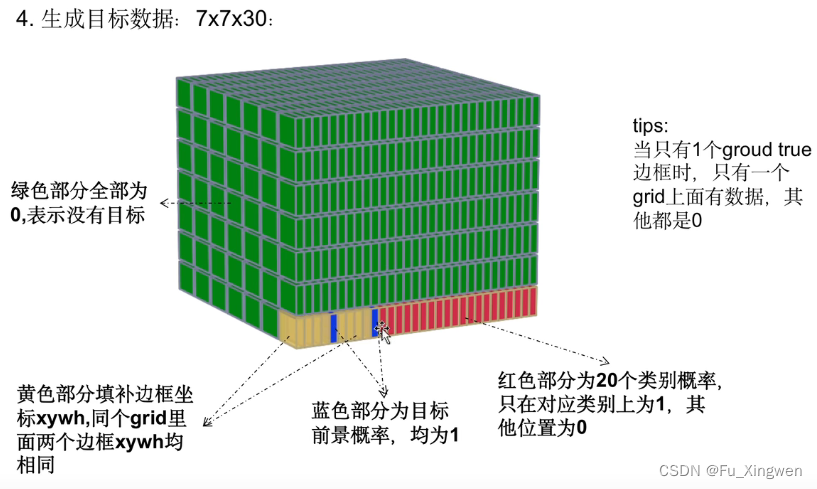
这就是标签:
(如果一张图片只有一个目标而且目标中心在左下角的话,那标签就是下面这样的)
(只有一个grid cell上有值,黄色部分是两个框的位置和宽高,蓝色部分是两个框有无目标的置信度,红色部分是20个类别,其余部分全部为0)
怎么样制作这样的标签呢?
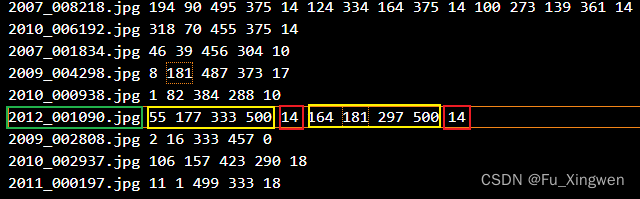
很简单,下图是一般的目标检测数据集的标签文件,会提供给你图片的文件名(绿色框),图片上目标的bbox的左上角点和右下角点的位置(黄色框),所属的类别代号(红色框),像下面这张图上就有两个类别代号为14的目标。然后呢,我们可以很轻松的计算bbox的中心位置,归一化后在乘以7再向下取整,我们就知道在哪个grid cell上标出bbox,置信度,以及类别了,把这些都放在相应的位置上呢,这张图片的标签就制作好了。对所有的图片执行同样的流程即可。
(可以发现这样的设置使得一个标签最多容纳 7×7=49个目标,还得是这些目标的中心点不在同一个grid cell上,若在同一个grid cell上也只能标记上其中一个目标)
标签制作好了,接下来就是训练网络了
训练的目的就是让网络在看到那张图片的时候输出的东西和标签差不多。
所以我们就需要设置一定的损失函数(或者说目标函数)
设置什么样的损失函数,才能达到我们的目标呢?
我们首先分析一下:
是不是要先区分一下,有没有目标?
如果没有目标
那么这个grid cell上的置信度是不是要为0
这就得到了第一个损失函数
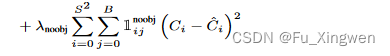
这里Ci是置信度标签,没有目标的话数值就是0。
这个损失函数就是让网络知道,没有目标的grid cell就只需要把它的置信度调成0就好了。这样我们在网络预测的时候就可以根据置信度来筛选bbox了,就是说把置信度低的bbox直接删掉。
然后其他的比如这个grid cell上输出的bbox位置宽高类别啥的就不用管了,反正这些bbox都会被删掉。
没目标的处理好了
就开始处理有目标的了
那如果这个grid cell上有目标,置信度是不是要为1
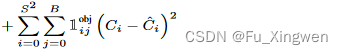
这里Ci是置信度标签,有目标的话数值就是1。
还有这个grid cell上的bbox的位置宽高,以及类别是不是都要调整到和标签一样?
ok
那么就有以下这些损失函数
bbox的位置的损失函数

bbox的宽高的损失函数(这里开根号是为了将大框和小框的偏移尺度拉到差不多的样子)
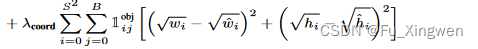
类别的损失函数
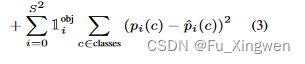
然后把它们加起来就是所有的损失函数了,然后再利用误差反向传播算法就可以让这个损失函数的值随着迭代次数的增加逐渐变小。这不就实现了我们那个训练的目标了:让输出的那堆数和我们制作的标签差不多!
这样网络在看到一张类似的图片时就能够预测出我们想要的结果了。
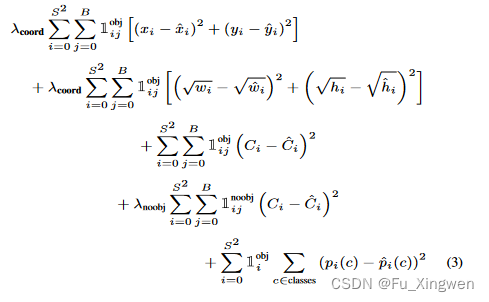
细心的同学会发现,这些损失函数在加起来的时候,乘上了系数,这是由于一张图片上一般只有一两个目标,这也就意味着标签上绝大多数的grid cell上都是0,这会导致没有目标的的损失在整个损失函数中占的比重会很大,进而让网络主要去拟合没有目标的grid cell网络,难以正常的训练。所以使用系数来调节loss占比,让每个没有目标grid cell产生的loss小一点(×0.5),让有目标的grid cell产生的loss大一点(×5)。
yolov1优点,流程简单,就一个黑盒网络可以直接通过回归得到目标的位置和类别,nice
快,比Faster R-CNN快10倍,能够实时检测,工业界的福音!
缺点:相对于两阶段的Faster R-CNN精度稍低(低一点,也还好)
若多个目标的中心点都落在一个grid cell里面,那yolov1也只能预测到一个目标(因为它标签设计的就是这样的)
直接回归出框的方法难度比较大(后面会改进为预测先验框的偏移量和缩放量的方式)
大小物体的损失权重一样,虽然用开根号的方式拉到差不多的样子,但这只能是缓解了这个问题,并没有完全解决这个问题。
这都为之后的改进提供了方向!
yolov2的一些改进
1.加入batchnorm
2.提高输入数据的分辨率
3.预测边框引入anchor机制
4.采用darnet-19新的卷积网络
5.采用kmeans聚类得到先验框
6.预测坐标改为偏移缩放
7.高低维特征融合
8.多尺度输入训练策略
1.加入batchnorm
去掉全连接层和drop_out层,直接用bn+relu
为什么要这样做?
当时的一个思想是说全连接层的参数量大,然后容易过拟合,一般也会加入drop_out抑制过拟合
所以去掉全连接层是减小网络参数量,提高推理速度的一个方法。
然后为什么也要去掉drop_out呢?
这是因为有研究人员发现如果drop_out放置在bn之前会出现方差偏移的问题。导致训练和测试的bn参数不一样。
替代的解决方案是
1.不用drop_out
2.drop_out放置在bn之后
3.采用新的高斯Dropout,又称Uout
作者是直接不用drop_out。
2.提高输入数据的分辨率
原来预训练是是在imagenet上做的,然后再在voc数据集上做目标检测的训练,但是imagenet的图像尺寸是224×224的,而voc的图像在yolov1上是被调整到448×448的大小,这样就产生了一个问题,就是预训练的骨干网络与之后目标检测训练的图像分辨率差别很大,会对精度有影响。
因此yolov2就在预训练阶段就将输入图片的尺寸调整到448×448,然后再目标检测阶段又调整到416×416。(这里416×416是为了网络在32倍下采样后得到13×13的奇数张量,从而保证一张图片只有一个大目标在中心时<这种情况比较多>,不用用中心四周的grid cell来代替)
3.预测边框引入anchor机制
将yolov1的S×S×(5*B+20)
其中S = 7,B = 2,也就是7×7×30
调整为
S×S×num_anchors×(5+num_classes)
其中,S = 13,num_anchors = 5,
num_classes根据数据集的不同略有不同;
这样的一步调整非常关键
首先,这里标签上一个grid cell不止可以定义一个类别了,而是可以定义num_anchors(这弥补了yolov1的一个硬伤——如果多个目标的中心点位于一个grid cell上也只能检测到其中一个目标)
然后,num_anchors的数量是预先根据数据的分布得到的kmeans聚类的中心点的个数,这里作者设定的个数是5;
这里为什么是5?
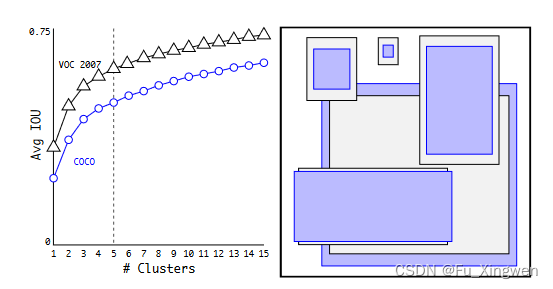
是因为作者做了这样一个实验,显然如果kmeans的中心点个数越多,平均的iou精度就会越高,但是带来的计算量也会越多,而中心点过5个增加中心点的个数带来的iou精度上升的效果逐渐减缓了,因此作者最终选择kmeans的中心点个数为5,也就是说每个grid cell的有5个bbox,这5个bbox可以分别为不同的类别,每个bbox都有一个固定的初始宽高(这是根据数据分布进行kmeans聚类得到的),然后网络预测的是bbox初始宽高的缩放值,这个在后面的loss介绍中会更加清楚。
这一改进将提高了7%的召回率
4.采用darnet-19新的卷积网络
这个其实没啥说的,现在好的特征提取骨干网络挺多的,可能在当时这样的一个网络结构取得了不错的成绩。
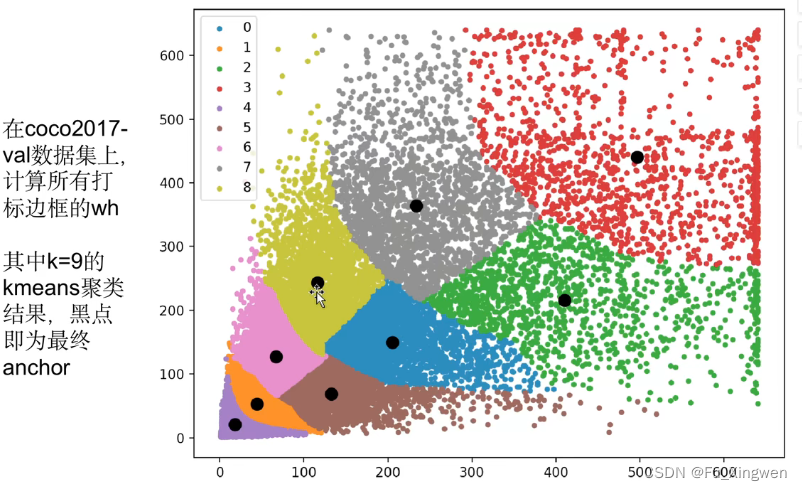
5.采用kmeans聚类得到先验框
这个之前说了,使用kmeans聚类先获得数据集的一个大致分布,得到5个bbox的宽高初值,然后网络只需微调bbox宽高的缩放值即可。
6.预测坐标改为偏移缩放
这个上面也提到了
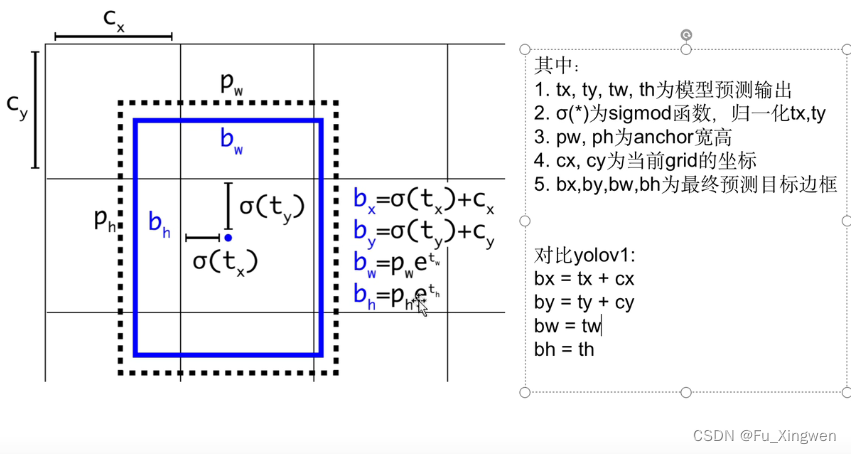
以e为底是为了放大loss,因为宽高的一点点缩放在整体的loss中占比小
7.高低维特征融合
这个就是把网络中间的特征图与深层的特征图拼接到一起,目的是提高小目标的检测精度
8.多尺度输入训练策略
这个就是在训练的时候每个几个迭代周期就改变输入图片的尺寸,从而让网络适应不同尺寸的图片输入
最后来看看yoloV2的loss吧

可以看到,yolov2少了一项这是因为采用先验框+偏移缩放的方式,使得yolov2没有v1大小框偏移尺度的问题。
yolov3
1.新的骨干网络,加了采用残差结构
2.加强特征提取
3.多尺度特征
4.对象分类softmax改成logistic,支持多标签对象(比如一个人有women和person两个标签)
未完待续~
















 1746
1746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









