







利用python爬取链家网上北京各地区的租房信息,其他地区的租房信息方法同样,只需更改一下地址即可,其余不需修改!!
网址:https://bj.lianjia.com/zufang/
工具:python3.6,pycharm,谷歌浏览器
模块:requests,re,BeautifulSoup,Pool
我们可以看到红色方框内共有17个地区,首先先获取到这17个地区的地址。
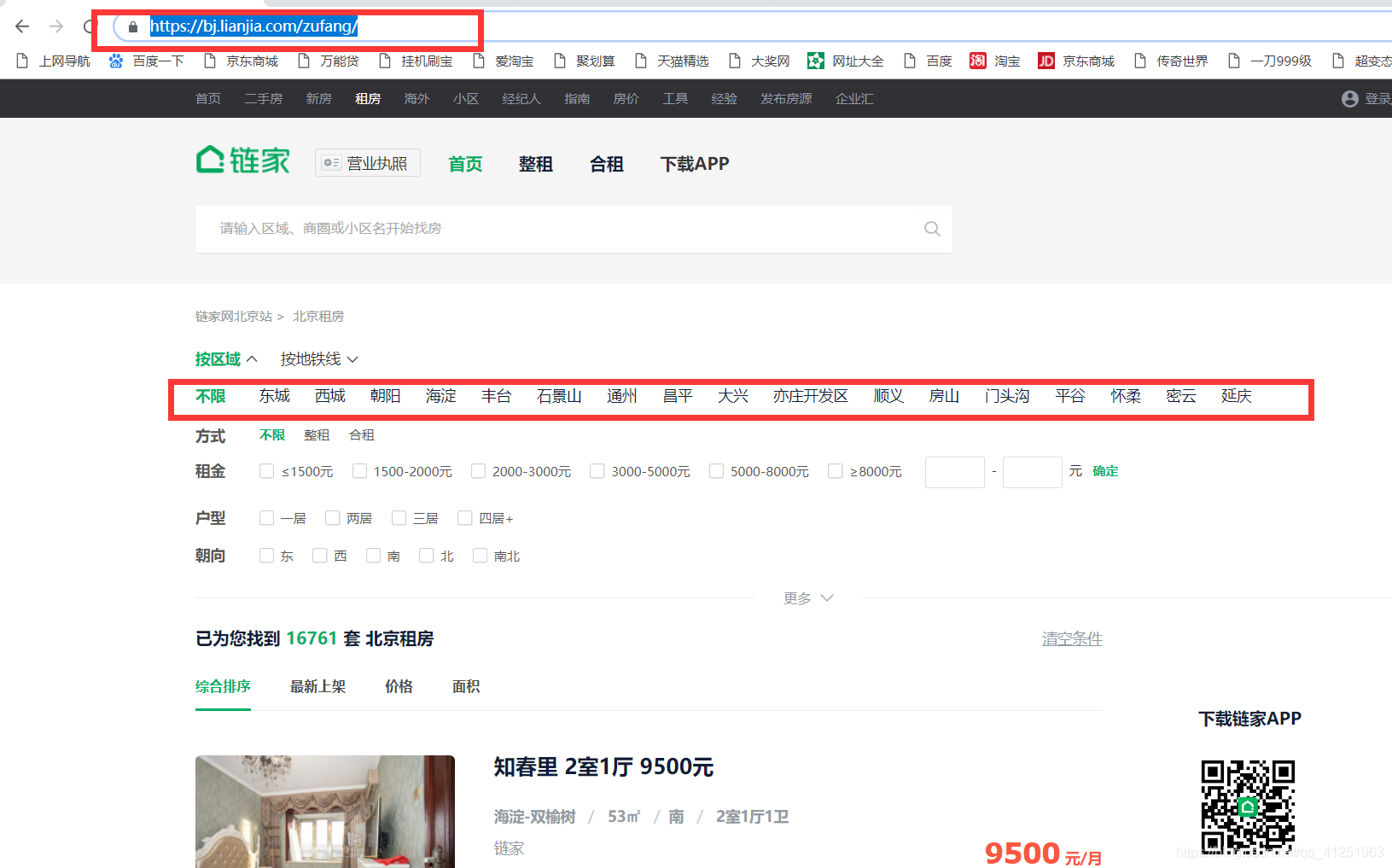
打开开发者工具:

这就是地区的所有地址,我们需要获取这些地址。

发现所有的地址都在daty-type="district"的li标签里。这里使用BeautifulSoup获取。利用soup.find_all()方法获取。遍历获取到的li标签,提取a标签下的href及文字信息。将获取的所有地址存到urls列表中。
urls=[]
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0'}
#获取17个地区的连接地址存入到urls中
def getAreaUrls():
url="https://bj.lianjia.com/zufang"
html=requests.get(url,headers=header)
soup=BeautifulSoup(html.text,'lxml')
areas=soup.find_all(attrs={'data-type':'district'})
#print(areas)
for area in areas[1:]:
url_area=(area.a)['href']
area_name=(area.a).text
urls.append(url_area)
#print(url_area,area_name)
接下来就是利用urls列表中的地址获取每个地区的租房信息,我们首先获取一个地区的租房 信息。以东城为例:

同样打开开发者工具:查看租房信息,发现所有的租房信息都在这里。

我们想要爬取的每条信息都能找到;

还是使用soup.find_all()方法
soup=BeautifulSoup(content.text,'lxml')
# 获取标题
titles = soup.find_all(class_='content__list--item--title twoline')
# 获取地点
addrs = soup.find_all(class_='content__list--item--des')
# 获取价格
prices = soup.find_all(class_='content__list--item-price')
这是 一页的信息,获取所有页的信息,查看第二页,第三页的网址:


 发现每页网址的规律,
发现每页网址的规律,
https://bj.lianjia.com/zufang/dongcheng/pg%s/#contentList%i将i改为1,恰好是第一页。

接下来需要做的就是获取这个地区有多少页租房信息;
在网页源代码里可以找到页数信息,

使用正则表达式提取页数:
page=re.findall('data-totalPage=(.*?) data-curPage=1>',html.text)
print(int(page[0]))
pages=int(page[0])#总的页数这就是大体的思路。
接下来看代码:
#获取链家网数据
import requests
import re
from bs4 import BeautifulSoup
from multiprocessing import Pool
urls=[]
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0'}
#获取17个地区的连接地址存入到urls中
def getAreaUrls():
url="https://bj.lianjia.com/zufang"
html=requests.get(url,headers=header)
soup=BeautifulSoup(html.text,'lxml')
areas=soup.find_all(attrs={'data-type':'district'})
#print(areas)
for area in areas[1:]:
url_area=(area.a)['href']
area_name=(area.a).text
urls.append(url_area)
#print(url_area,area_name)
# getAreaUrls()
# print(urls)
#获取每个地区的租房信息
def oneArea(url):
# https: // bj.lianjia.com / zufang / dongcheng / pg1 / # contentList
title_list = []
address_list = []
prices_list = []
i=1
url0="https://bj.lianjia.com"+url+'pg%s/#contentList'%i
print(url0)
html=requests.get(url0,headers=header)
#获取每个地区租房信息的页数page
page=re.findall('data-totalPage=(.*?) data-curPage=1>',html.text)
print(int(page[0]))
pages=int(page[0])#总的页数
for i in range(1,pages+1):
url1 = "https://bj.lianjia.com" + url + 'pg%s/#contentList' % i
print(url1)
content=requests.get(url1,headers=header)
soup=BeautifulSoup(content.text,'lxml')
# 获取标题
titles = soup.find_all(class_='content__list--item--title twoline')
# 获取地点
addrs = soup.find_all(class_='content__list--item--des')
# 获取价格
prices = soup.find_all(class_='content__list--item-price')
for title in titles:
title_list.append(title.a.text.strip())
for addr in addrs:
address_list.append(addr.text.replace('\n', '').replace(' ', ''))
for p in prices:
prices_list.append(p.text)
allInfo = zip(title_list, address_list, prices_list)
#将获取到的信息存入到text文件中。
for info in allInfo:
with open(url[8:-1]+'.txt','a',encoding='utf-8') as f:
f.write(str(info))
print(info)
if __name__ == '__main__':
pool = Pool()
getAreaUrls()#获取所有的地区
pool.map(oneArea,[i for i in urls])
这样就能够轻松获取各个地区的租房信息了!每个地区的信息都存到txt文档中,文档以地区名字命名!!
















 4676
4676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











