






技术:requests、BeautifulSoup、SQLite
解析页面,存数据到SQLite数据库,到时候你用navicat导出成csv什么的就行
1、确定城市
以天津为例,网页是https://tj.lianjia.com/ershoufang/rs/

把上面这些地区名字复制
2、爬取数据内容
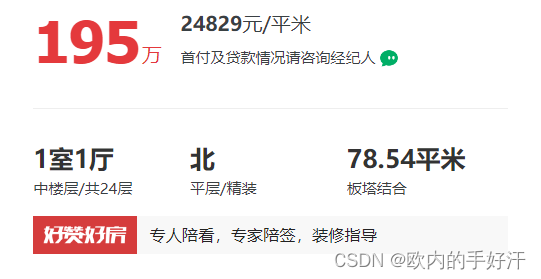

从上面的属性中选择性爬取
3、给爷爬
3.1、创建中文映射
KEYMAP = {
"房屋户型": "room_num",
"所在楼层": "floor_location",
"户型结构": "layout_structure",
"建筑类型": "building_type",
"房屋朝向": "house_orientation",
"建筑结构": "structure_type",
"装修情况": "decoration_condition",
"配备电梯": "equipped_elevator",
"交易权属": "transaction_ownership",
"房屋用途": "house_usage"
}
CITY_MAP = {
"天津": "tj",
"北京": "bj"
}
DISTRICT_MAP = {
"tj": {
"和平": "heping", "南开": "nankai", "河西": "hexi", "河北": "hebei", "河东": "hedong", "红桥": "hongqiao", "西青": "xiqing",
"北辰": "beichen", "东丽": "dongli", "津南": "jinnan", "武清": "wuqing", "滨海新区": "binhaixinqu", "宝坻": "baodi", "蓟州": "jizhou",
"静海": "jinghai", "宁河": "ninghe"
},
"bj": {}
}
3.2、创建数据库
在项目目录下创建House.db文件,建表
import sqlite3
# 根据上面的映射创建表,设置字段名
CREATE_SQL = ('CREATE TABLE House ('
'hid INTEGER PRIMARY KEY, '
'rid INTEGER, '
'title TEXT, '
'area REAL, '
'total_price INT, '
'price INT, '
'room_num INT, '
'resblock_name TEXT, '
'city_name TEXT, '
'longitude REAL, '
'latitude REAL, '
'image TEXT, '
'floor_location TEXT, '
'layout_structure TEXT, '
'building_type TEXT, '
'house_orientation TEXT, '
'structure_type TEXT, '
'decoration_condition TEXT, '
'equipped_elevator TEXT, '
'transaction_ownership TEXT, '
'house_usage TEXT );')
def create_table():
cursor = conn.cursor()
try:
cursor.execute(CREATE_SQL)
print("创建数据表")
except:
print('数据表已存在')
cursor.close()
conn = sqlite3.connect('House.db')
create_table()
3.3、多线程爬
虽然Python用多线程好像实际还是单线程,我也搞不清楚,但感觉至少有点用处。
注意多线程操作SQLite的时候,每个线程都要自己创建connection,不能共用同一个conn
3.4、爬数据
步骤如下:
- 分页爬列表,设置城市、地区、起始页码,如(‘天津’,‘南开’,1),访问网页
https://{city}.lianjia.com/ershoufang/{district}/pg{page}。解析出网页元素中的房屋列表,获取一会爬房屋详细信息需要用的hid(房屋Id)和rid(小区id?不知道) - 遍历列表中每一个房子,访问网页
https://{city}.lianjia.com/ershoufang/{hid}.html,解析网页元素获取对应数据 - 存数据库,由于链家搜索应该加了一些推荐算法,之前爬过的房子你在下一页有可能还会看见他,所以存数据的时候,可以insert_or_update;或者只插入,若数据库中已经存在该房屋就不管他了,跳到下一次循环
其中,第二步爬每个房子的信息的时候可以多线程爬
第一步设置起始页码后,他会从起始页开始,循环爬后面的页,直到没数据了
懒得写了,直接贴全部代码了
import re
import threading
import requests
import time
import json
import sqlite3
import math
from bs4 import BeautifulSoup
import concurrent.futures
import queue
CREATE_SQL = ('CREATE TABLE House ('
'hid INTEGER PRIMARY KEY, '
'rid INTEGER, '
'title TEXT, '
'area REAL, '
'total_price INT, '
'price INT, '
'room_num INT, '
'resblock_name TEXT, '
'city_name TEXT, '
'longitude REAL, '
'latitude REAL, '
'image TEXT, '
'floor_location TEXT, '
'layout_structure TEXT, '
'building_type TEXT, '
'house_orientation TEXT, '
'structure_type TEXT, '
'decoration_condition TEXT, '
'equipped_elevator TEXT, '
'transaction_ownership TEXT, '
'house_usage TEXT );')
KEYMAP = {
"房屋户型": "room_num",
"所在楼层": "floor_location",
"户型结构": "layout_structure",
"建筑类型": "building_type",
"房屋朝向": "house_orientation",
"建筑结构": "structure_type",
"装修情况": "decoration_condition",
"配备电梯": "equipped_elevator",
"交易权属": "transaction_ownership",
"房屋用途": "house_usage"
}
CITY_MAP = {
"天津": "tj",
"北京": "bj"
}
DISTRICT_MAP = {
"tj": {
"和平": "heping", "南开": "nankai", "河西": "hexi", "河北": "hebei", "河东": "hedong", "红桥": "hongqiao", "西青": "xiqing",
"北辰": "beichen", "东丽": "dongli", "津南": "jinnan", "武清": "wuqing", "滨海新区": "binhaixinqu", "宝坻": "baodi", "蓟州": "jizhou",
"静海": "jinghai", "宁河": "ninghe"
},
"bj": {}
}
def create_table():
cursor = conn.cursor()
try:
cursor.execute(CREATE_SQL)
print("创建数据表")
except:
print('数据表已存在')
cursor.close()
def crawl_house_list(city, district, start_page = 1):
with concurrent.futures.ThreadPoolExecutor(max_workers=20) as executor:
city = CITY_MAP[city]
district_name = district
district = DISTRICT_MAP[city][district_name]
total_page = start_page
current_page = start_page
tasks = [] # 线程提交任务
while current_page <= total_page:
list, total_page = get_house_list(city, district, current_page)
print(f"{city}-{district}【{current_page}/{total_page}】 num:{len(list)}")
for item in list:
# 没有记录才插入记录
if not check_exist(conn, 'House', 'hid', item["hid"]):
tasks.append(executor.submit(save_house_data, city, item, district_name))
'''
根据hid更新或插入数据
house_data = get_house_data(city, item["hid"], item["rid"])
if house_data:
house_data["district_name"] = district_name
update_or_insert_data(conn, 'House', 'hid', house_data)
else:
print("查询{}出错".format(item))
'''
# 阻塞执行
for future in concurrent.futures.as_completed(tasks):
future.result()
tasks = [] # 清空多线程任务列表
current_page += 1
# time.sleep(2)
def get_house_list(city, district, page):
url = f"https://{city}.lianjia.com/ershoufang/{district}/pg{page}"
response = requests.get(url)
list = []
total_page = 0
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 获取房子列表
ul = soup.find('ul', class_='sellListContent')
if ul:
li_list = ul.find_all('li')
for li in li_list:
rid = li.get('data-lj_action_resblock_id')
hid = li.get('data-lj_action_housedel_id')
list.append({"rid": rid, "hid": hid})
else:
print("Unable to find ul with class 'sellListContent'")
# 获取总页数
page_box = soup.find('div', class_='page-box house-lst-page-box')
if page_box:
page_data = page_box.get('page-data')
if page_data:
page_data_dict = json.loads(page_data)
total_page = int(page_data_dict.get('totalPage'))
else:
print("No page data attribute found in page-box")
else:
print("Unable to find div with class 'page-box house-lst-page-box'")
else:
print("Failed to fetch the webpage")
return list, total_page
def get_house_data(city, hid, rid):
url = f"https://{city}.lianjia.com/ershoufang/{hid}.html"
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
house = {"hid": hid, "rid": rid}
# 获取房屋信息、小区信息与经纬度
script_tags = soup.find_all('script')
for script in script_tags:
if 'ershoufang/sellDetail/detailV3' in script.text:
# 使用正则表达式匹配初始化数据对象
match = re.search(r'init\(({.*?})\);', script.text, re.DOTALL)
if match:
try:
data_str = match.group(1)
data_str = re.sub(r"\$\.getQuery\(location\.href, '.*?'\)", '1', data_str) # 去掉jquery代码
data_str = re.sub(r"'", '"', data_str) # 替换单引号为双引号
data_str = re.sub(r'(\w+):([^/\\])', r'"\1":\2', data_str) # 将key用双引号包裹
data_str = re.sub(r"(\"isNewHouseReport\": \".*?\"),", r"\1", data_str)
data_dict = json.loads(data_str)
house["title"] = data_dict["title"]
house["area"] = float(data_dict.get("area"))
house["total_price"] = int(data_dict.get("totalPrice"))
house["price"] = int(data_dict.get("price"))
house["resblock_name"] = data_dict.get("resblockName") # 小区名称
house["city_name"] = data_dict.get("cityName")
position = data_dict.get("resblockPosition").split(",")
house["longitude"] = position[0]
house["latitude"] = position[1]
images = data_dict.get("images")
if len(images) != 0:
house["image"] = images[0]["url"]
break
except:
#print("错误:{}".format(data_str))
return None
else:
print("No script containing the desired data found")
# 获取额外信息
intro = soup.find('div', class_="introContent")
if intro:
# 基础信息
base = intro.find('div', class_="base")
lis = base.find_all('li')
for li in lis:
label_tag = li.find('span', class_='label')
value = label_tag.next_sibling.strip()
label_tag = label_tag.text
if label_tag == "房屋户型":
value = int(re.sub("(\d)室.*", r"\1", value))
elif label_tag == "所在楼层":
value = re.sub(r" ?\(.*?\)", "", value)
if KEYMAP.get(label_tag):
house[KEYMAP[label_tag]] = value
# 交易信息
transaction = intro.find('div', class_="transaction")
lis = transaction.find_all('li')
for li in lis:
spans = li.find_all('span')
label_tag = spans[0].text
value = spans[1].text
if KEYMAP.get(label_tag):
house[KEYMAP[label_tag]] = value
else:
print("No intro block found")
else:
print("Failed to fetch the webpage")
return None
return house
def save_house_data(city, item, district_name):
# 多线程每个都要有自己的conn
conn = sqlite3.connect('House.db')
house_data = get_house_data(city, item["hid"], item["rid"])
if house_data:
house_data["district_name"] = district_name
insert_data(conn, 'House', house_data)
else:
print("查询{}出错".format(item))
def generate_update_query(table, data, key_column):
update_query = f"UPDATE {table} SET "
update_query += ", ".join(f"{key} = ?" for key in data.keys() if key != key_column)
update_query += f" WHERE {key_column} = ?"
return update_query
def generate_insert_query(table, data):
insert_query = f"INSERT INTO {table} ({', '.join(data.keys())}) VALUES ({', '.join(['?'] * len(data))})"
return insert_query
def update_or_insert_data(conn, table, key_column, data):
cursor = conn.cursor()
# 检查是否存在特定键值的数据
key_value = data[key_column]
cursor.execute(f"SELECT * FROM {table} WHERE {key_column} = ?", (key_value,))
existing_data = cursor.fetchone()
if existing_data:
# 如果存在数据,则执行更新操作
update_query = generate_update_query(table, data, key_column)
values = []
for key in data.keys():
if key != key_column:
values.append(data[key])
values.append(key_value)
cursor.execute(update_query, values)
conn.commit()
print("Data updated successfully.")
else:
# 如果不存在数据,则执行插入操作
insert_query = generate_insert_query(table, data)
cursor.execute(insert_query, list(data.values()))
conn.commit()
#print("Data inserted successfully.")
cursor.close()
def check_exist(conn, table, key_column, key_value):
cursor = conn.cursor()
# 检查是否存在特定键值的数据
cursor.execute(f"SELECT * FROM {table} WHERE {key_column} = ?", (key_value,))
existing_data = cursor.fetchone()
return existing_data is not None
def insert_data(conn, table, data):
cursor = conn.cursor()
insert_query = generate_insert_query(table, data)
cursor.execute(insert_query, list(data.values()))
conn.commit()
#print("Data inserted successfully.")
cursor.close()
conn = sqlite3.connect('House.db')
if __name__ == '__main__':
# print(CREATE_SQL)
create_table()
districts = ['武清','滨海新区','宝坻','蓟州','静海','宁河'] # 设置你城市中想爬的地区
for district in districts:
print("=== Crawling " + district + " ===")
crawl_house_list('天津', district, 1)















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











