







人流量预测
作者: 崔雨田、张江元
学校:洛阳师范学院
成绩
- 计算机设计大赛河南省省赛二等奖
- 计算机设计大赛国赛三等奖

介绍
作品将人工智能与实际生活联系到一起,利用人工智能方案面向门店、通道 等出入口场景,以头肩为识别目标,进行人体检测和追踪,根据目标轨迹判断进 出区域方向,实现动态人数统计,返回区域进出人数。并对人数进行持久化存储, 使用神经网络对历史的数据进行多元回归预测,最终得到未来的客流量,以便店 铺所有者实现对店铺管理的科学化智能化,实现对劳动力的解放,改善人们的工作方式。
主要工作如下
- 利用现代人工智能方案来统计出每天店铺的出入人数
- 使用神经网络对历史的数据进行多元回归预测未来客流量
- 对数据进行可视化的展示,以便辅助店家做出决策
软件功能如下
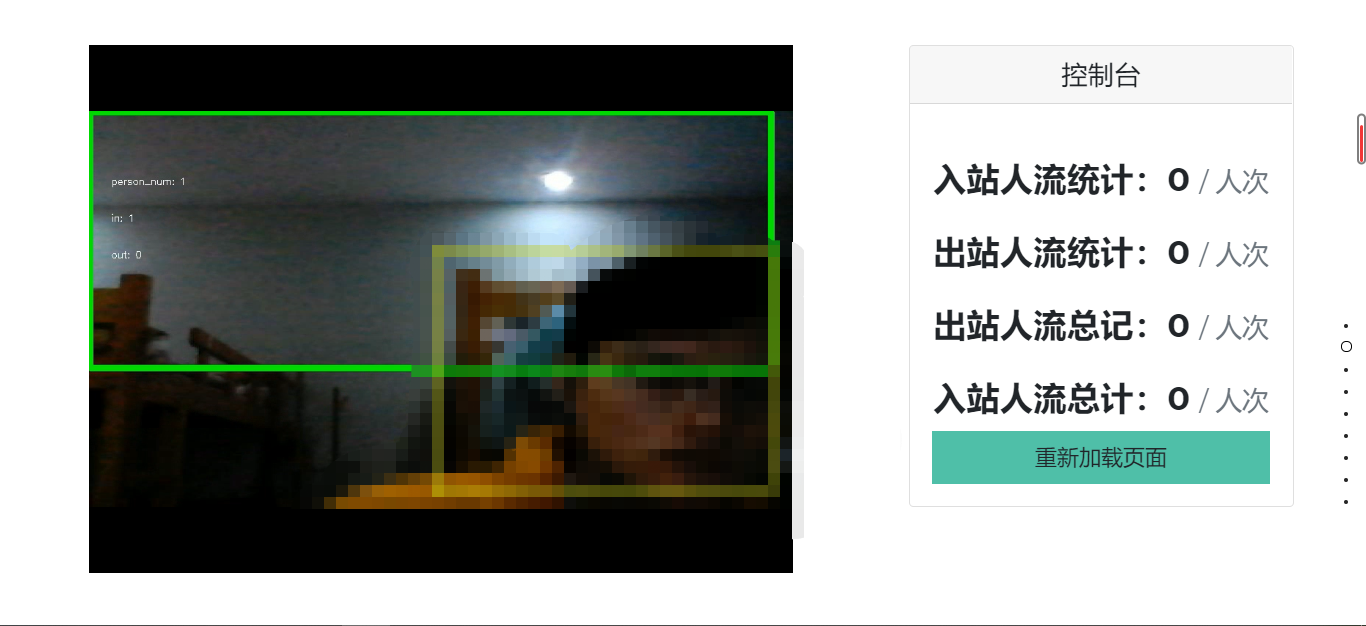
- 实时检测区域内进入站人数,并且显示检测结果
- 对每日历史数据以及神经网络预测数据进行可视化展示
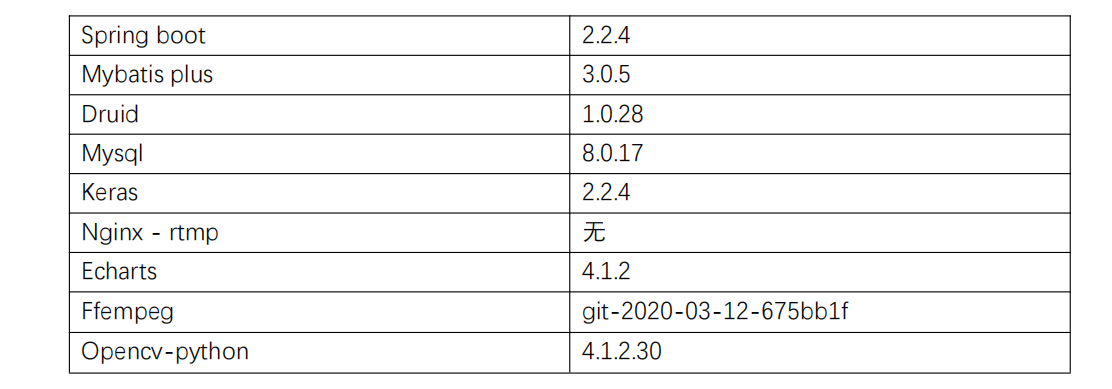
技术栈
技术栈
设计思路
根据最初对作品功能的设想,把作品拆分为多个模块,各模块之间功能分 工明确但又相互依赖。我们主要功能是能够实现:检到监控中的人流数、实时显示检测 效果、结合实际因素和历史数据对未来人数做出预测、对数据可视化展示。
针对以上功能分别进行了技术实现,实现方案如下。
检到监控中的人流数
该模块实现方案为采用百度 AI 动态人流量计数技术,技术介绍如下:面向门 店、通道等出入口场景,以头肩为识别目标,进行人体检测和追踪,根据目标轨迹 判断进出区域方向,实现动态人数统计,返回区域进出人数。
实时显示检测效果
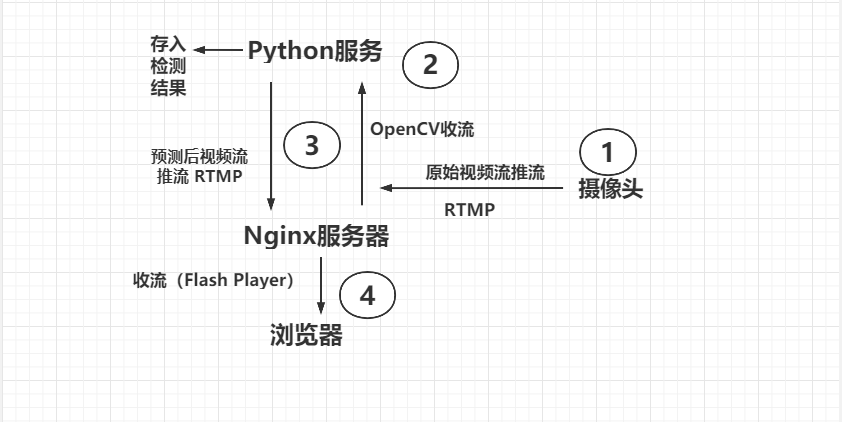
该模块实现方案为搭建 Nginx-Rtmp 流媒体服务器,完成视频流的推拉转发 操作,并且采用多线程来保障画面的实时显示。
结合实际因素和历史数据对未来人数做出预测
该模块实现方案为搭建神经网络对历史数据进行学习,最终完成根据影响因素 预测数据功能。对于预测方案的选取,我们查阅文献后对不同预测方案的对比结果如下:
BP 神经网络预测模型则不需人为选择函数形式,它是通过网络的自学习能力, 只要建模样本有足够的代表性,利用网络自身的学习功能可以得到一个预测效果比较好的预测模型,而回归预测模型,除了建模型数据要有代表性外,还需在众多的函 数形式中选择一个合适的函数形式,这是一项非常困难的工作,特别是预测变量是多 个的时候,更难于确定被预测变量与预测变量间的函数形式,针对以上的对比结果 我们选择的是神经网络做为我们的技术方案。
对数据可视化展示
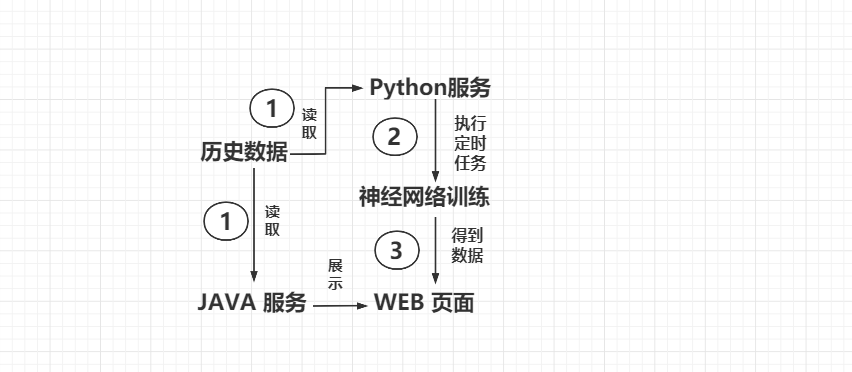
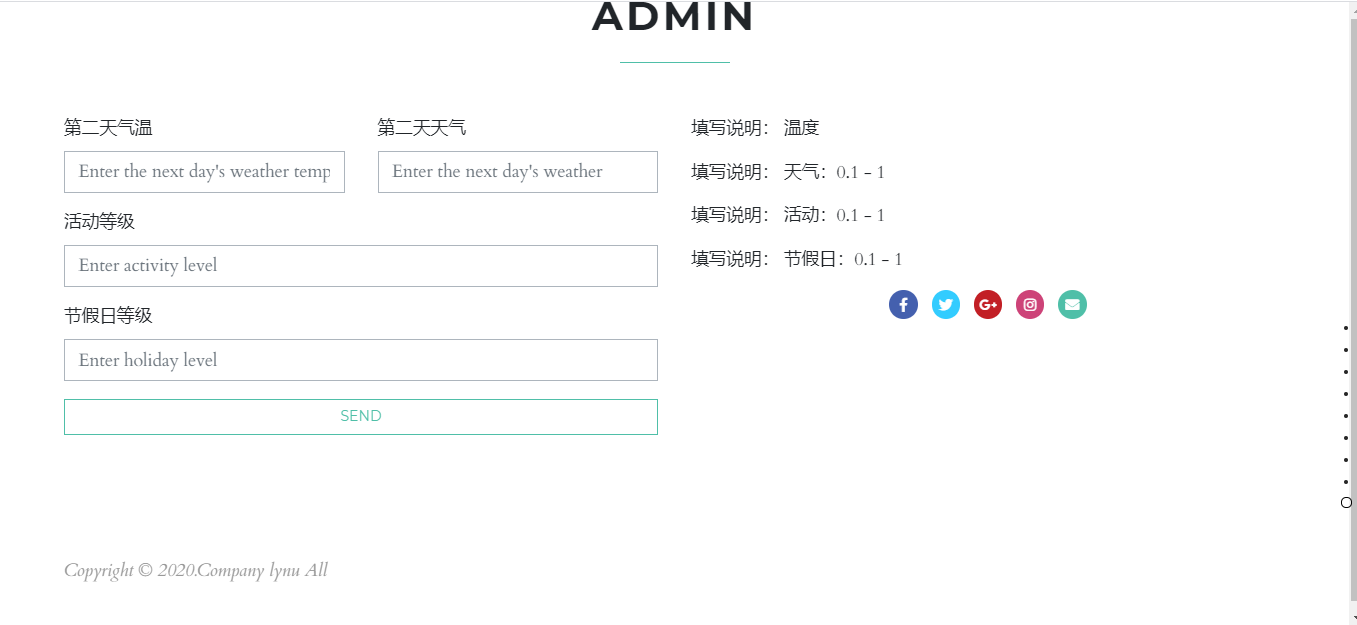
该模块实现方案为采用 spring boot 搭建 web 界面,使用 Echarts 完成对数 据的可视化展示,并在 web 界面采集用户输入的影响因素。
软件架构
实时显示区域内检测后的画面
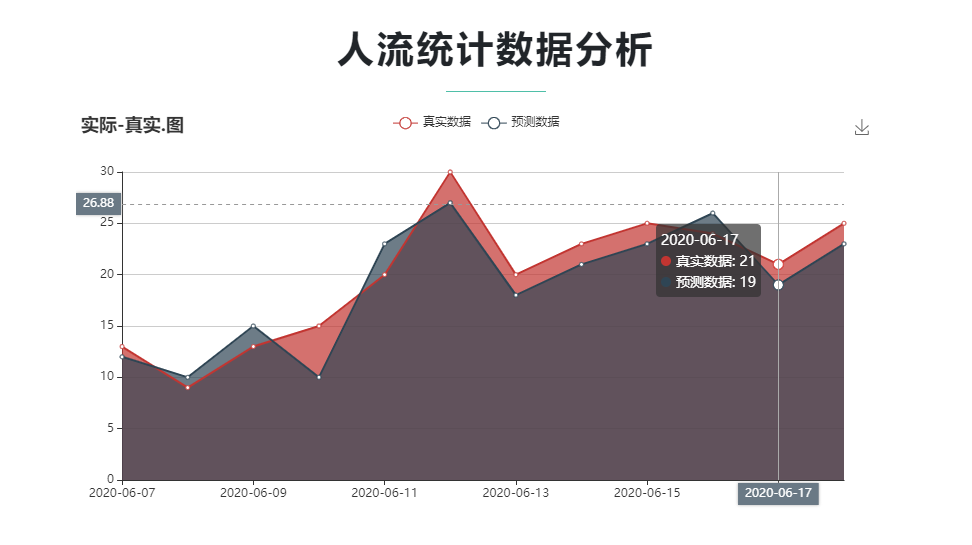
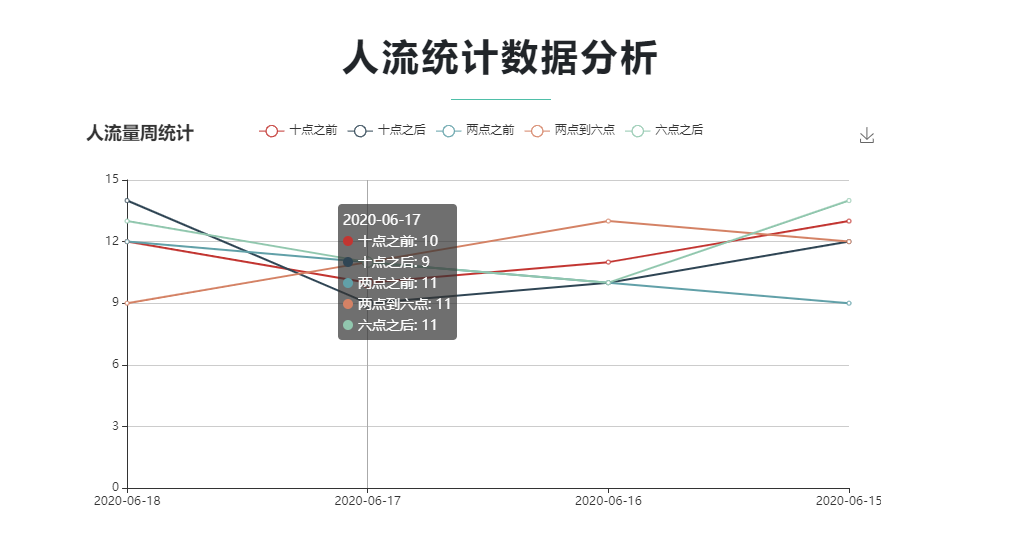
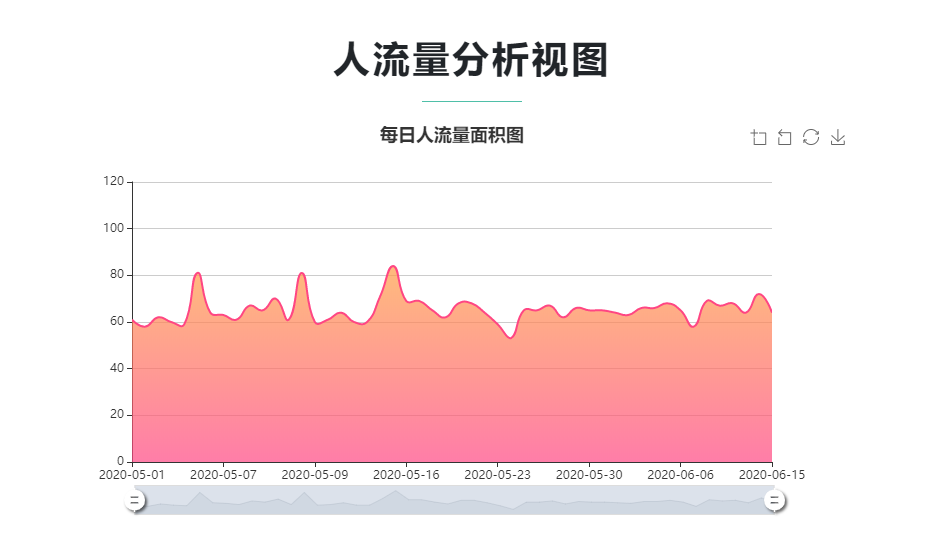
历史数据、预测数据可视化展示
环境配置
搭建RTMP流媒体服务器
配置yum源
下载 163 镜像
# 可本地下载后上传到 服务器中
http://mirrors.163.com/.help/CentOS7-Base-163.repo
# 直接在服务器下载
wget http://mirrors.163.com/.help/CentOS7-Base-163.repo
备份并替换系统的repo文件
cp CentOS7-Base-163.repo /etc/yum.repos.d/
cd /etc/yum.repos.d/
mv CentOS-Base.repo CentOS-Base.repo.bak
mv CentOS7-Base-163.repo CentOS-Base.repo
执行yum源更新命令
yum clean all
yum makecache
yum update
安装Docker
安装
# 安装docker
yum install docker
开启
# 开启 docker
systemctl start docker
配置镜像
vi /etc/docker/daemon.json
{"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"]}
重启
# 守护进程重启
sudo systemctl daemon-reload
# 重启docker服务
sudo systemctl restart docker
# 关闭docker
# sudo systemctl stop docker
下载镜像、创建容器
docker pull tiangolo/nginx-rtmp
docker run -d -p 1935:1935 --name nginx-rtmp tiangolo/nginx-rtmp
配置ffmpeg
下载安装ffmpeg
http://ffmpeg.zeranoe.com/builds/
配置环境变量

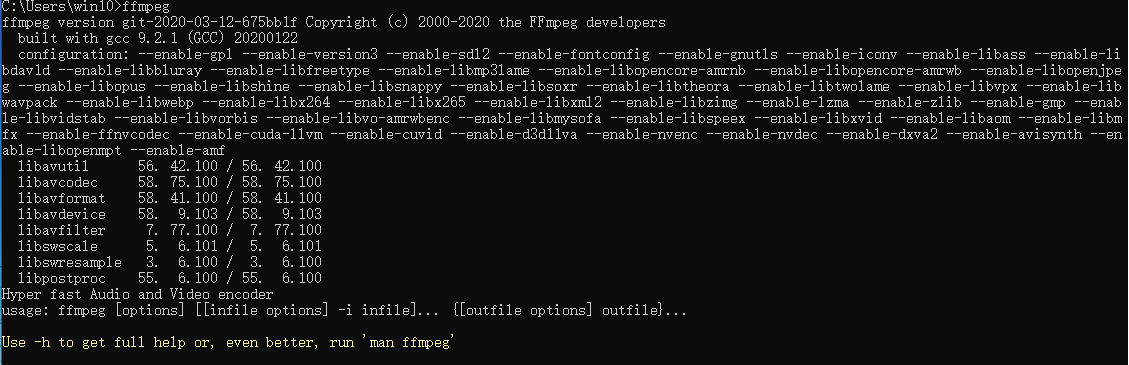
测试
cmd - > ffmpeg
使用OBS推流、Python拉流
下载OBS
https://cdn-fastly.obsproject.com/downloads/OBS-Studio-26.1.1-Full-Installer-x64.exe
配置推流地址
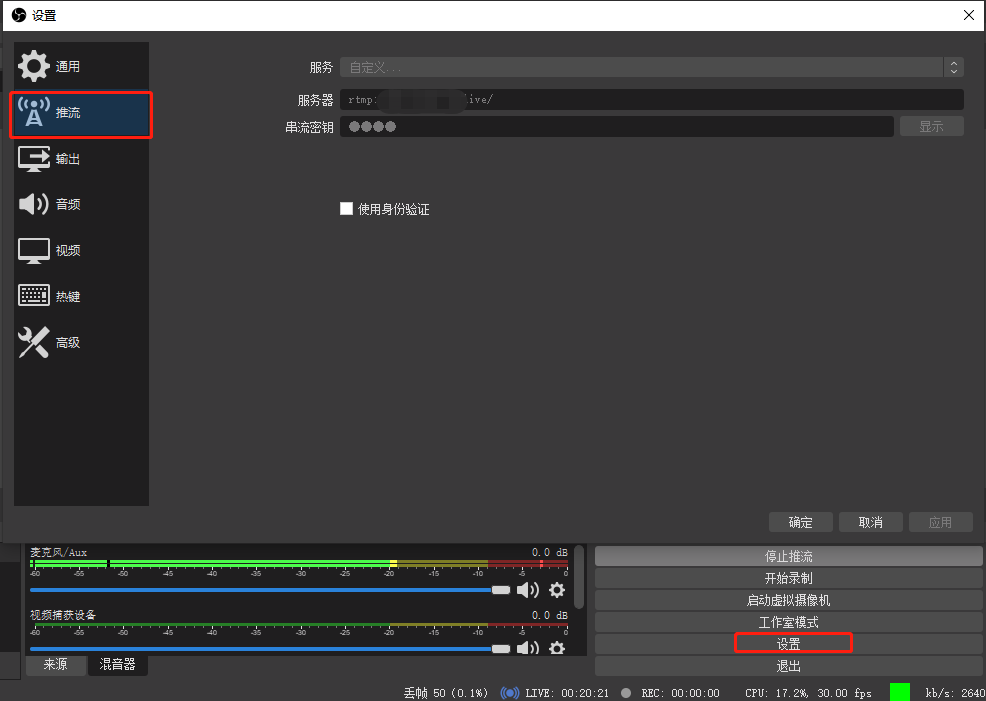
使用Python拉流
import cv2
import threading
import time
import win32gui,win32con
class Producer(threading.Thread):
"""docstring for Producer"""
def __init__(self, rtmp_str):
super(Producer, self).__init__()
self.rtmp_str = rtmp_str
# 通过cv2中的类获取视频流操作对象cap
self.cap = cv2.VideoCapture(self.rtmp_str)
# 调用cv2方法获取cap的视频帧(帧:每秒多少张图片)
# fps = self.cap.get(cv2.CAP_PROP_FPS)
self.fps = self.cap.get(cv2.CAP_PROP_FPS)
print(self.fps)
# 获取cap视频流的每帧大小
self.width = int(self.cap.get(cv2.CAP_PROP_FRAME_WIDTH))
self.height = int(self.cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
self.size = (self.width, self.height)
print(self.size)
# 定义编码格式mpge-4
self.fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', '2')
# 定义视频文件输入对象
self.outVideo = cv2.VideoWriter('saveDir1.avi', self.fourcc, self.fps, self.size)
def run(self):
print('in producer')
ret, image = self.cap.read()
while ret:
# if ret == True:
self.outVideo.write(image)
cv2.imshow('video', image)
cv2.waitKey(int(1000 / int(self.fps))) # 延迟
if cv2.waitKey(1) & 0xFF == ord('q'):
self.outVideo.release()
self.cap.release()
cv2.destroyAllWindows()
break
ret, image = self.cap.read()
if __name__ == '__main__':
print('run program')
# rtmp_str = 'rtmp://live.hkstv.hk.lxdns.com/live/hks' # 经测试,已不能用。可以尝试下面两个。
# rtmp_str = 'rtmp://media3.scctv.net/live/scctv_800' # CCTV
# rtmp_str = 'rtmp://58.200.131.2:1935/livetv/hunantv' # 湖南卫视
rtmp_str = 'rtmp://ip:1935/live/test'
producer = Producer(rtmp_str) # 开个线程
producer.start()
注册百度AL
获得请求的TOKEN
关于百度AL部分的操作可以查看官方文档, 主要注意如下几点
- 获得自己的请求TOKEN
- 找到官方的测试地址
- 并且使用本地图片,在官方控制台进行测试。
- 观察返回的JSON, 从中获得自己有用的信息。
https://cloud.baidu.com/doc/BODY/s/zk4qlfchx
首先注册一个自己的百度AL账号,然后选择 人脸与人体识别中的人流量统计。
http://ai.baidu.com/
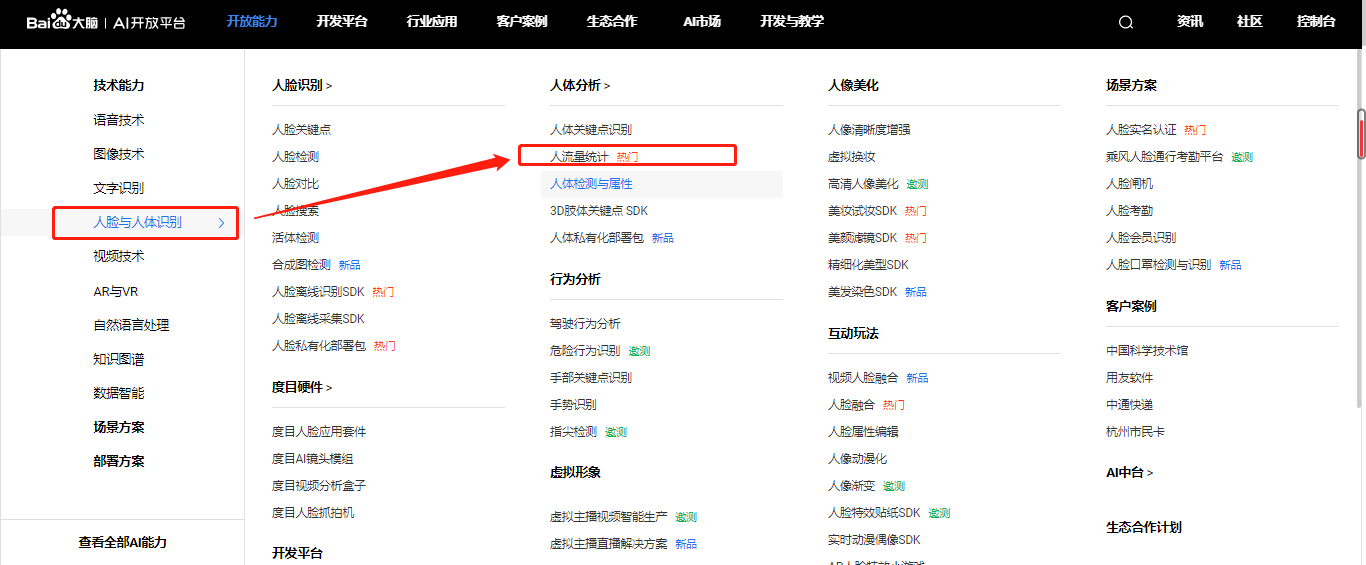
进入控制台创建一个应用,然后使用 AK 和 SK 获得自己的请求TOKEN
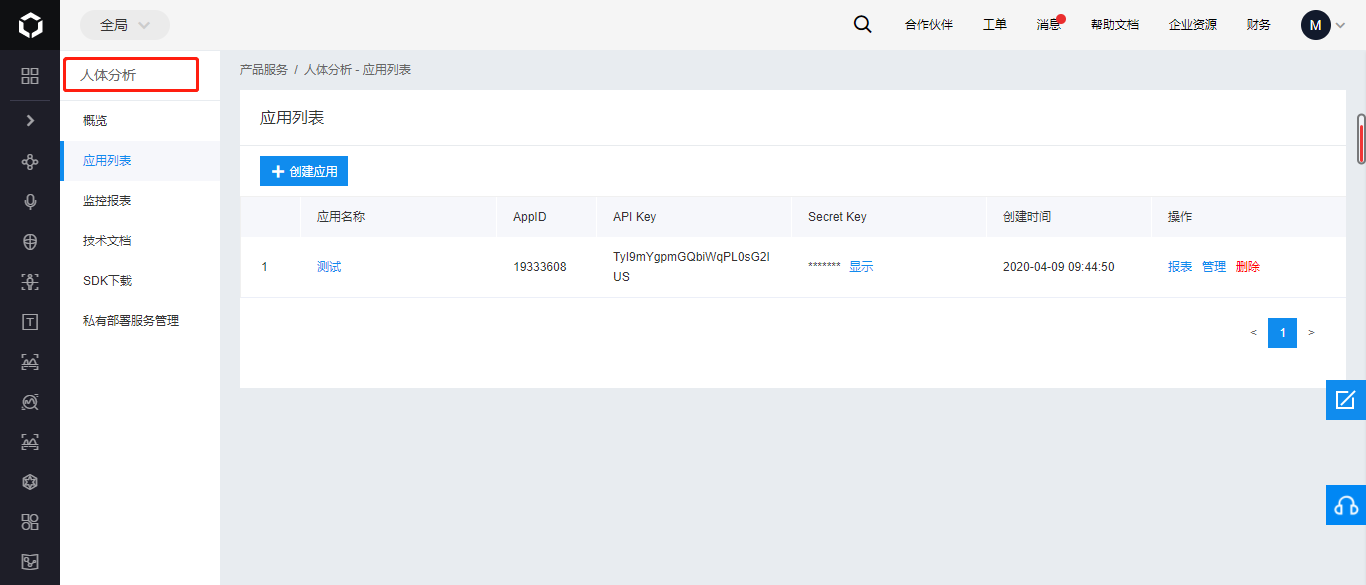
项目重点
检测人流
关于检测人流部分使用的是百度AL的动态人流统计,具体的操作流程如下:使用opencv 获取视频,然后把视频流分帧并使用base64编码进行编码,随后请求百度AL的动态人流统计的接口,从返回值里面获得当前帧的检测结果,检测结果是一个json字符串,从中我们抽取到人数的结果以及检测后的图像(同样base64编码)。为了进行检测后视频流的实时显示,使用ffmpeg把检测后的帧组成视频并且推送到流媒体服务器中以便在前端进行拉流显示。
显示检测结果
为了能够实现显示检测结果采用的方案是设计多线程,让程序分开执行。通过全局变量来传递检测后的视频流完成实时的推流。实施细节:为了完成功能需求一共设计了三个线程。
1、拉取视频流线程
2、检测视频流线程
3、推送检测结果线程
神经网络
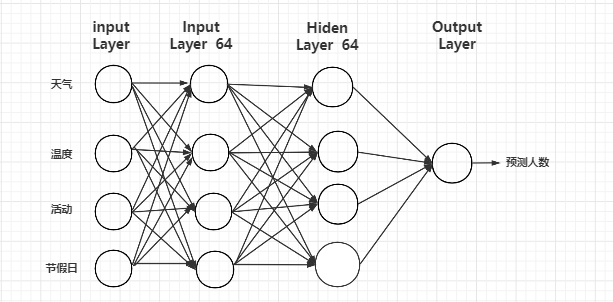
网络的搭建选取的是 Keras 框架,Keras 是一个开放源码的高级深度学习 程序库,使用 Python 编写,能够运行在 TensorFlow 或 Theano 之上。其主要作 者和维护者是 Google 公司的工程师,以 MIT 开放源码方式授权。Keras 使用最 少的程序代码、花费最少的时间就可以建立深度学习模型,进行训练、评估准确 率,并进行预测,搭建神经网络要确定初始化学习率,输入向量,输出向量,隐 层层数,每一个隐层的神经元的个数,以及输入层与隐层之间,隐层与隐层之间 和隐层与输出层之间的连接权值和激活函数。 预测客流量的神经网络包含四层:输入层、隐藏层、隐藏层、输入层,其中 隐藏层的神经元个数都是 64 个,输入向量的大小为 1*4,输入向量大小为 网络的搭建过程参考了波士顿房价预测比赛中优秀案例程序,在学习的同时把别人优秀的经验应用到自己模型中。
具体的模型如下
运行项目
运行方式
| 开发工具 | pycharm idea |
|---|---|
| 数据库 | mysql |
| 服务器 | spring boot |
| 可视化工具 | echarts |
| linux | centso 7 |
- spring boot
- 导入sql 文件
- 修改sql配置 账号密码
- 配置 idea maven 镜像
- 等待依赖加载完毕
- 运行项目
- python
- 首先下载项目所需依赖
- 运行项目
运行Python 模块
此模块的主要作用是:调用摄像头,调用百度AL检测,请求Java接口传递检测结果,推送检测后的图像帧
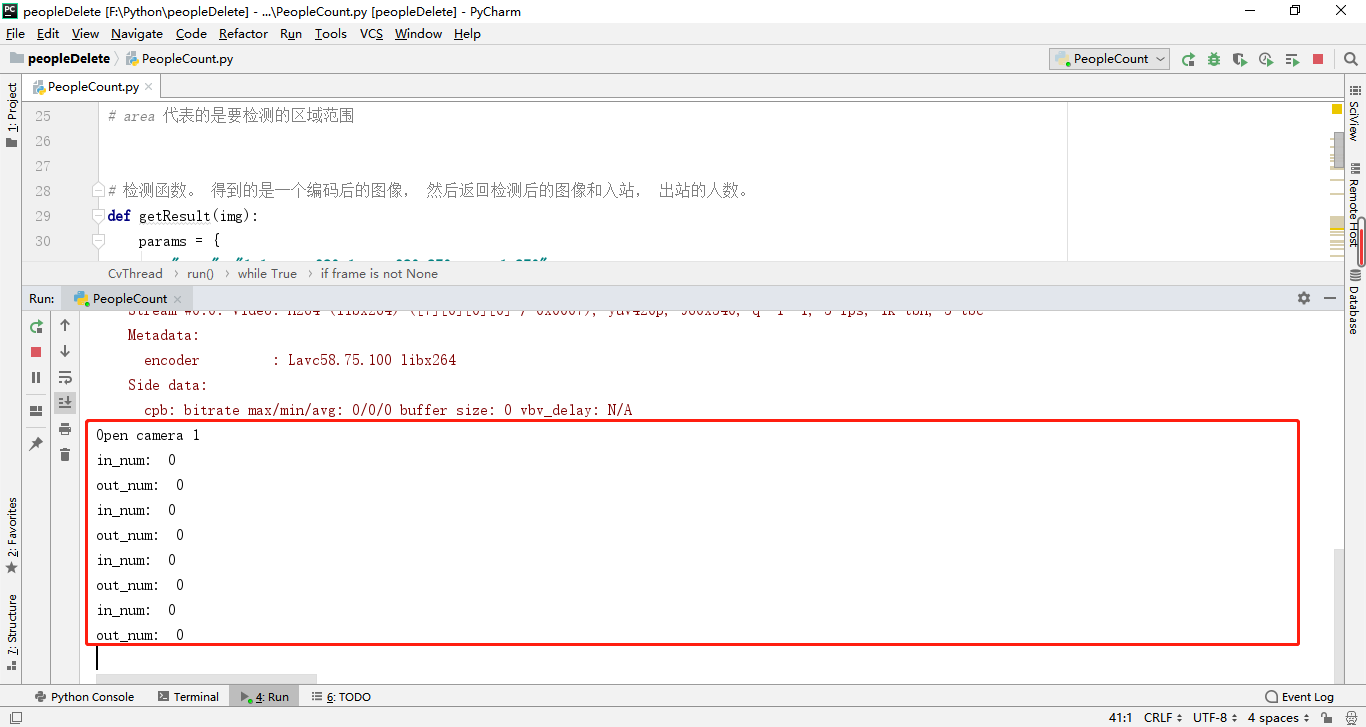
运行JAVA 模块
此模块作用为:接受Python中传递的检测结果,拉取检测后的视频流,对数据可视化展示,收集影响因子数据
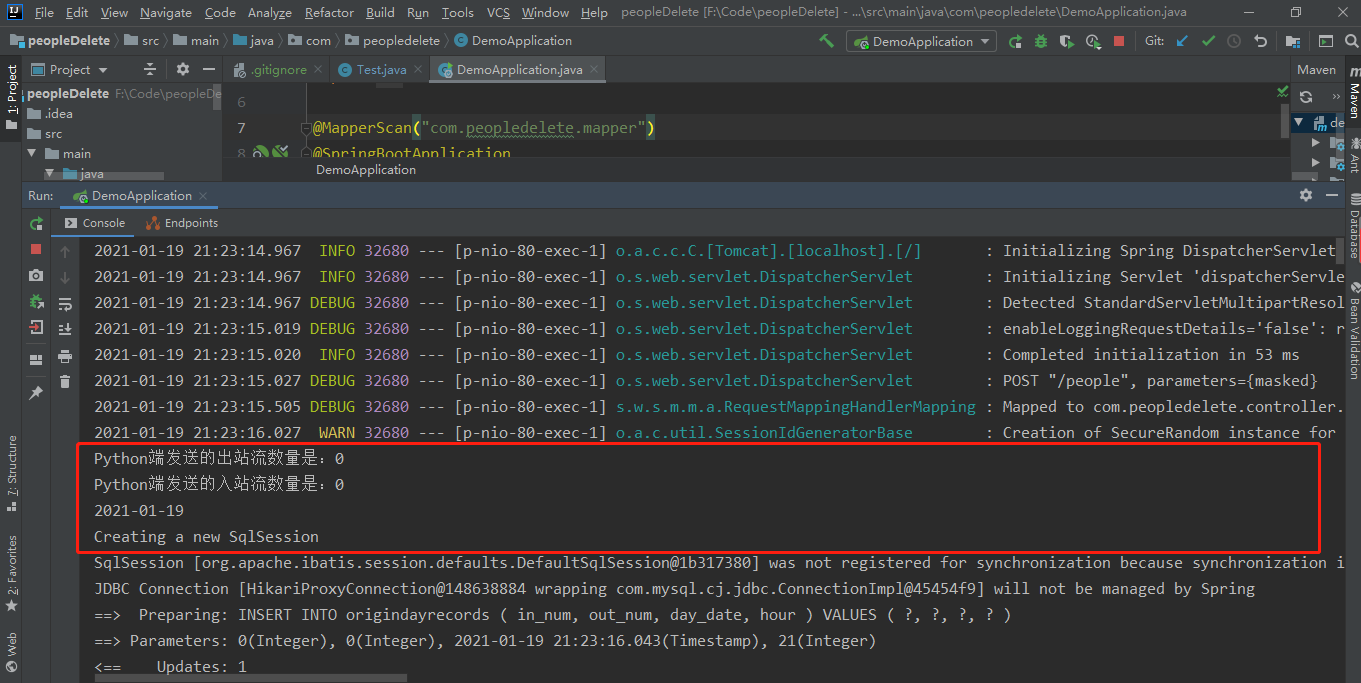

关键程序
获取视频、检测视频、推送检测后的视频
# python3
import cv2
import base64
from PIL import Image
from io import BytesIO
import requests
import json
import numpy as np
import threading
import time
import subprocess as sp
# 导入 数据库的工具
from conDatabase import dataUtils
shared_image = (np.ones((540, 960, 3), dtype=np.uint8) * 255).astype(np.uint8)
process_image = (np.ones((540, 960, 3), dtype=np.uint8) * 255).astype(np.uint8)
dataUtils = dataUtils()
in_num = 0
out_num = 0
# 左上角
# 右上角
# 左下角
# 右下角
# area 代表的是要检测的区域范围
# 检测函数。 得到的是一个编码后的图像, 然后返回检测后的图像和入站, 出站的人数。
def getResult(img):
params = {
"area": "1,1, 930,1, 930,350, 1,350",
"case_id": 1,
"case_init": "false",
"dynamic": "true",
"image": img,
"show": "true", }
# 请求参数
request_url = "https://aip.baidubce.com/rest/2.0/image-classify/v1/body_tracking"
access_token = '#################################################################'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
res = requests.post(request_url, data=params, headers=headers)
return res
# 定义CV线程, 提取视频流 抽帧, 返回抽帧后的 图像 shared_image 全局变量
class CvThread(threading.Thread):
def __init__(self):
super(CvThread, self).__init__() # 注意:一定要显式的调用父类的初始化函数。
def run(self): # 定义每个线程要运行的函数
print('CvThread thread is run!')
global shared_image
camera = cv2.VideoCapture(0)
if (camera.isOpened()):
print('Open camera 1')
else:
print('Fail to open camera 1!')
time.sleep(0.05)
camera.set(cv2.CAP_PROP_FRAME_WIDTH, 864) # 2560x1920 2217x2217 2952×1944 1920x1080
camera.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
camera.set(cv2.CAP_PROP_FPS, 5) # 抽帧参数
size = (int(camera.get(cv2.CAP_PROP_FRAME_WIDTH)), int(camera.get(cv2.CAP_PROP_FRAME_HEIGHT)))
sizeStr = str(960) + 'x' + str(540)
fps = camera.get(cv2.CAP_PROP_FPS) # 30p/self
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('res_mv.avi', fourcc, fps, size)
while True:
ret, frame = camera.read() # 逐帧采集视频流
if frame is not None:
image = Image.fromarray(frame)
image = image.resize((960, 540))
frame = np.array(image)
shared_image = frame
# 定义检测线程, 检测视频 得到 CvThread 返回的全局参数 shared_image,把shared_image 转为BASE64。
# 调用 getResult 调用 AI 接口 返回转化后的 图像
# 并且 process_image 赋值为 res , 为检测后的图像
class BaiDuThread(threading.Thread):
def __init__(self):
super(BaiDuThread, self).__init__() # 注意:一定要显式的调用父类的初始化函数。
def run(self): # 定义每个线程要运行的函数
print('BaiDuThread thread is run!')
global shared_image
global process_image
global in_num
global out_num
while True:
# 把图片编码
img = Image.fromarray(shared_image) # 将每一帧转为Image
output_buffer = BytesIO() # 创建一个BytesIO
img.save(output_buffer, format='JPEG') # 写入output_buffer
byte_data = output_buffer.getvalue() # 在内存中读取
base64_data = base64.b64encode(byte_data) # 转为BASE64
response = getResult(base64_data)
json_str = json.dumps(response.json())
if response:
# 将 Python 字典类型转换为 JSON 对象
# print(response.json())
json_str = json.dumps(response.json())
# 转化为 json字符串
d = json.loads(json_str)
person_count = d['person_count']
in_num = person_count['in']
out_num = person_count['out']
print("in_num: ", in_num)
print("out_num: ", out_num)
# 再把加密后的结果解码, 结果为二进制数据
temp = base64.b64decode(d['image'])
# print(temp)
# 二进制数据流转np.ndarray [np.uint8: 8位像素]
img = cv2.imdecode(np.frombuffer(temp, np.uint8), cv2.IMREAD_COLOR)
# 将bgr转为rbg
rgb_img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
process_image = rgb_img
time.sleep(0.05)
# 推流设置的一些参数
RTMP_HOST = '######'
rtmpUrl = 'rtmp://' + RTMP_HOST + ':1935/live/test'
command = ['ffmpeg',
'-y',
'-f', 'rawvideo',
'-vcodec','rawvideo',
'-pix_fmt', 'bgr24',
'-s', '960x540',
'-r', str(5),
'-i', '-',
'-c:v', 'libx264',
'-pix_fmt', 'yuv420p',
'-preset', 'ultrafast',
'-f', 'flv',
rtmpUrl]
global pipe
pipe = sp.Popen(command, stdin=sp.PIPE)
# 推流线程
# 拿到BaiDuThread 线程检测后的 process_image 图像,然后讲 process_image 推流
class PushThread(threading.Thread):
def __init__(self):
super(PushThread, self).__init__() # 注意:一定要显式的调用父类的初始化函数。
# self.arg=arg
def run(self): # 定义每个线程要运行的函数
print('PushThread thread is run!')
# 可以在这里推送当前的 in 、out 数
global process_image
url = "http://127.0.0.1:80/people"
count = 0
while True:
pipe.stdin.write(process_image.tostring()) # 存入管道
cv2.imwrite('1.jpg',process_image)
param = {'inNum': str(in_num),'outNum': str(out_num) }
count += 1
if count % 25 == 0:
try:
r = requests.post(url=url, data=param)
except:
pass
time.sleep(0.198)
# 定义CV线程, 提取视频流 抽帧, 返回抽帧后的 图像 shared_image 全局变量
CvThread = CvThread()
CvThread.start()
# 定义检测线程,检测视频 得到 CvThread 返回的全局参数 shared_image,把shared_image 转为BASE64。
BaiDuThread = BaiDuThread()
BaiDuThread.start()
# 推流线程
PushThread = PushThread()
PushThread.start()
部分截图
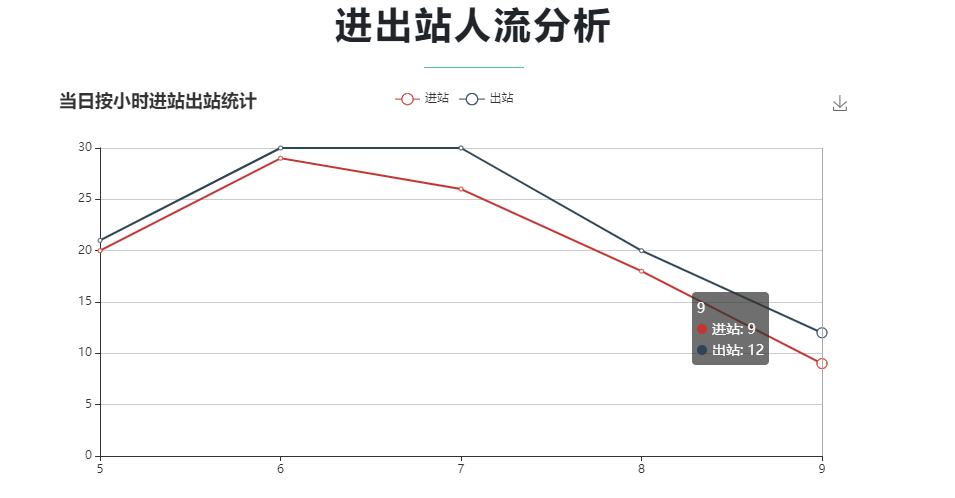
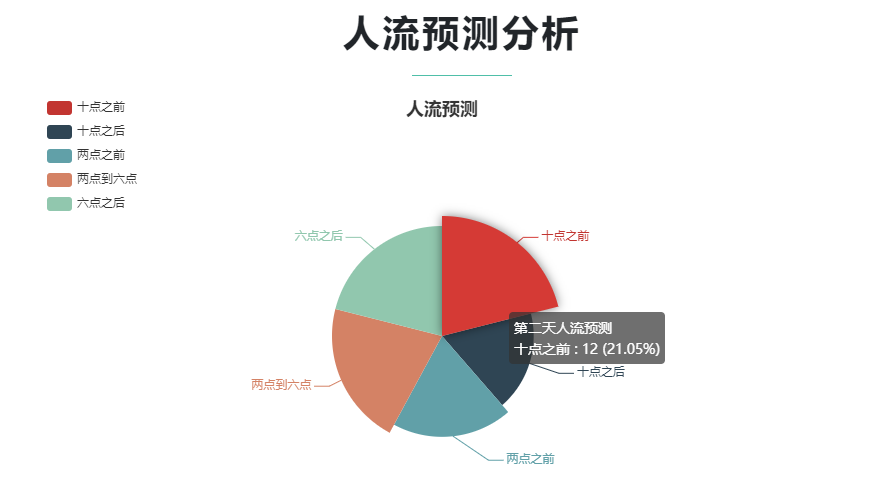

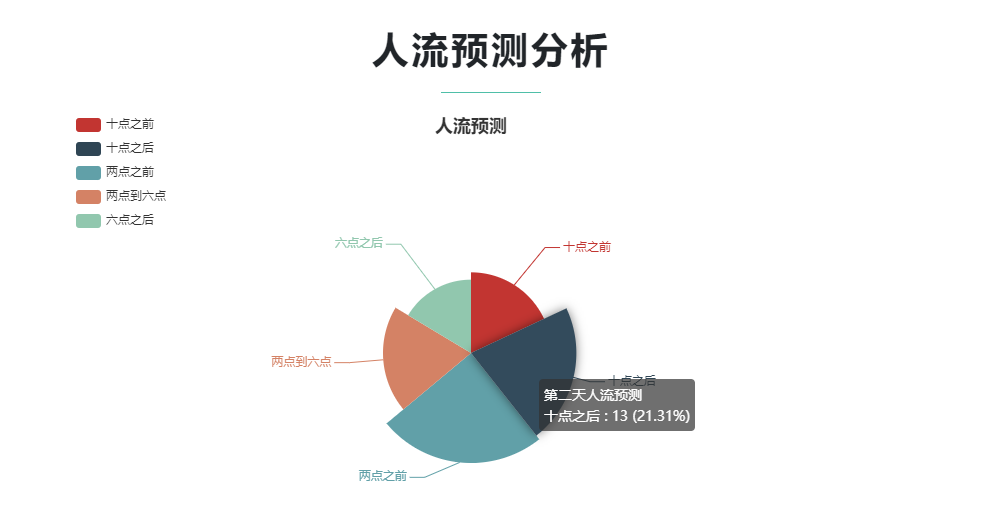

















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









