







第2章 H公园客流量初步分析
2.1 H公园客流量数据及初步时间序列分析方法选择
H公园开园于2018年11月,开园时间短,所拥有的历史数据只有一年多,缺少历年来数据的对比,相关人员本身无法根据这些数据得到有价值的信息,例如季节趋势等。并且客流量变化较大,无明显特征,除了天气、节假日等显著的影响之外,导致客流量变化大的影响因素还未被充分找到。H公园历史客流量如图2.1所示。
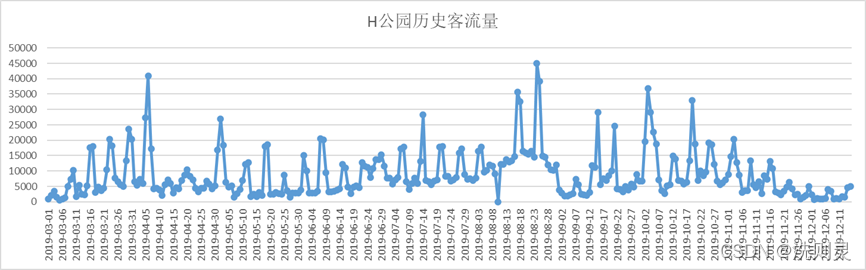
图2.1 H公园历史客流量
Fig. 2.1 Historical passenger flow of H Park
此外,利用数据挖掘技术对客流量进行准确的预测,其成果主要取决于以下几个方面:1)数据集的构造是否合理:在数据挖掘中,训练数据与测试数据必须要满足同分布的条件;2、特征集的特征是否充分且合理:理想的特征集中的特征,其特定的取值能够准确地指向某一信息,是多对一的关系,因此,如果特征集中缺少了重要的特征,或者特征过少,那么就可能导致同样的特征取值指向了不同的信息,从而导致错误的结果;3、算法的选择合理:算法不存在好坏之分,根据实际情况以及数据集的特点合理地选择算法,才能得到好的结果。
基于H公园的客流量存在的客观问题,以及为了利用数据挖掘得到好的结果所应该注意的问题,对H公园进行基本的时间序列分析是有必要的,有助于后续数据挖掘模型的构建。通过时间序列分析,可以找到基本的季节趋势,有助于解决数据集的选择问题,如果使用全部的历史数据,那么应该注意由于季节的原因,某些数据并非是同分布的,如果使用了较少的数据,又有训练数据过少的问题。并且,在时间序列分析中,除了分析基本趋势外,将天气、节假日、周末等基本信息输入之后,得到的结果有助于后续特征集构建,如果得到的结果拟合度不够好,说明在这些基本变量之外,还存在着重要变量。
基于以上分析,本文采用Facebook的时间序列预测模型fbprophet。从已有的应用看,fbprophet在处理存在季节趋势、节假日效应的时间序列数据时,有不错的效果。
2.2 H公园客流量时间序列分析
2.2.1 fbprophet原理
fbprophet是基于时间序列分解的分析方法改进而来的。一般而言,时间序列分解将时间序列 yt 分解成季节部分 St ,趋势部分 Tt ,剩余部分 Rt ,有如下公式:
在实际情况中,除了季节项,趋势项,剩余项之外,通常还有节假日的效应,因此在fbprophet中,Sean J.Taylor和Benjamin Letham同时考虑了以上四项:
yt=gt+st+ht+ϵt (2.2)
其中gt 为趋势项,它表示时间序列在非周期上面的变化趋势;st 表示周期项,或者称为季节项,一般来说是以周或者年为单位;ht 表示节假日项,表示在当天是否存在节假日;ϵt 表示误差项[16]。由于其中包含了节假日项,也是本文使用该框架的原因。
2.2.2 数据拟合
本文使用的数据直接来自于该公园的历史数据,因此,不存在缺失值、异常值等问题。由于H公园于2018年11月开园,因此其前期的历史客流量可能由于该原因人数较少,并且2018年12月至2019年2月存在较多的社会事件及特殊节日,因此使用的数据为2019年3月至2019年12月的数据。
将数据输入fbprophet模型中后,通过调整参数,例如yearly_seasonality (在实例化模型时,可以为每个内置的季节性指定傅里叶级数)、changepoint_ prior_scale (默认情况下,该参数设置为0.05。增加它将使拟合趋势更加灵活) 等,得到一个较好的拟合结果,另外设置模型预测未来7天的数据。结果如图2.2所示。
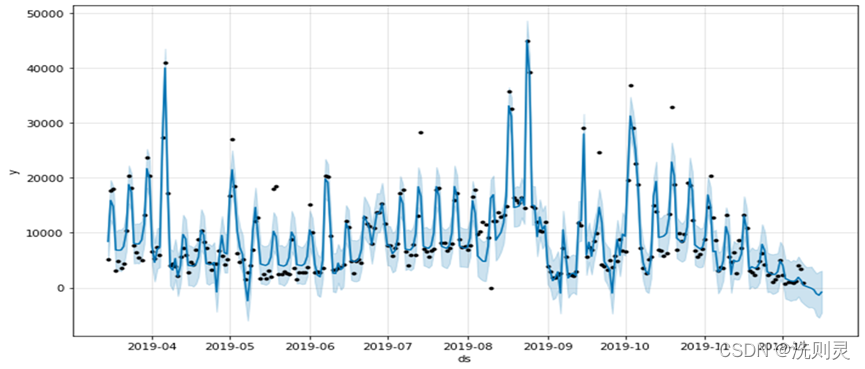
2.2.3 拟合结果分析
通过对数据拟合的结果进行简单的观察可以发现,拟合结果较好但是从预测未来7天的结果来看,其未来7天的预测结果并不符合实际,并且延续了2019年10月至12月的下降趋势,说明该结果属于过拟合。而通过调整参数得到的其他结果,则存在拟合不足的问题,说明目前所拥有的数据信息,包括天气、周次、节假日,不能充足地反映实际情况,还存在很多未知且影响较大的因素,因此,后续模型的建立,需要考虑到能够帮助识别出这些潜在因素。
虽然该结果属于过拟合,但只代表了它不能用于预测,以上的数据拟合结果,还是反映出了季节趋势和周期性。季节趋势如图2.3所示。
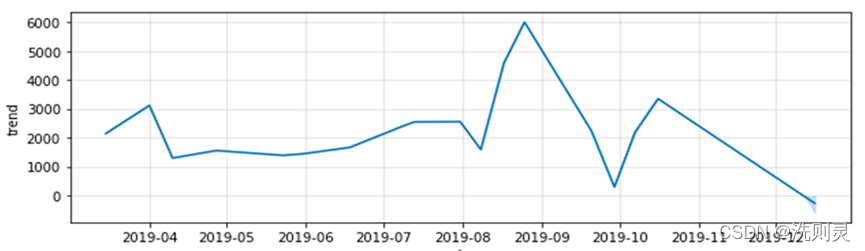
图2.3 季节趋势
Fig. 2.3 Seasonal trend
从季节趋势图2.3可以明显看出,除了5、6月份以为,客流量在不同的月份波动较大,这涉及到了数据集构建的问题。数据集中,训练集和测试集的划分需要满足同分布的条件,如果有足够多且合理的特征集来表示数据,那么特征的不同取值,可以用来区别数据,因此,在合理且足够多的特征集的条件下,数据集可以比较大,不同分布的数据只需要不同的特征取值来表示即可。但在当前问题下,数据集则无法过大,因为时间距离过大的数据之间存在着较为明显的季节趋势,而在特征构造的问题上,季节是难以属于表示的特征,主要原因在于季节属于“模糊变量”,如果简单的以“0-1”来表示季节变化,则不符合实际的季节渐变趋势,而如果以百分位来表示,也无法找到合理的能够实际反映季节渐变趋势的数字。因此,为了找到更为合理的数据集长度,通过以上对于季节趋势的分析,本文决定使用一个月的数据长度作为训练集,测试集为未来一天。另外,通过以上分析,本文认为除了季节属于“模糊变量”以外,实际情况中还存在着其他未知的“模糊变量”。
H公园客流量的周期性如图2.4所示。

从图2.4中可以较为明显的看出,其周期性较为符合人们的一般活动习惯,即工作日人数较少,周末人数较多,周五由于贴近周末,情况较为特殊。根据对于周期性的分析,除了一般结论之外,在后续的特征集构造问题上,应该注意周五的特殊问题,以使特征集能够更加准确地反映实际情况。
通过以上对于H公园历史客流量的基础分析,有助于本文后续模型的建立以及完善,帮助解决客观存在的问题与理想的数据挖掘应用之间存在的问题,从而使后续数据挖掘的应用更具合理性。
2.3 百度搜索指数分析
2.3.1 数据拟合与结果分析
本文直接从百度指数网站(http://index.baidu.com/v2/index.html#/)收集数据,百度搜索指数同样属于时间序列,并且与H公园客流量之间可能存在一定的相关性,如果能够对其加以利用,则对后续的客流量预测会有极大的帮助,因此,同样对其进行时间序列的基本分析是有必要的,同时还应探究其与H公园客流量之间的相关性。
由于搜索信息对于实际情况一般具有一定的“前兆效应”[9],经过合理地推断以及实验,本文决定将百度指数后移一天,之后输入fbpfophet算法中,其他输入不变,结果如图2.5所示。
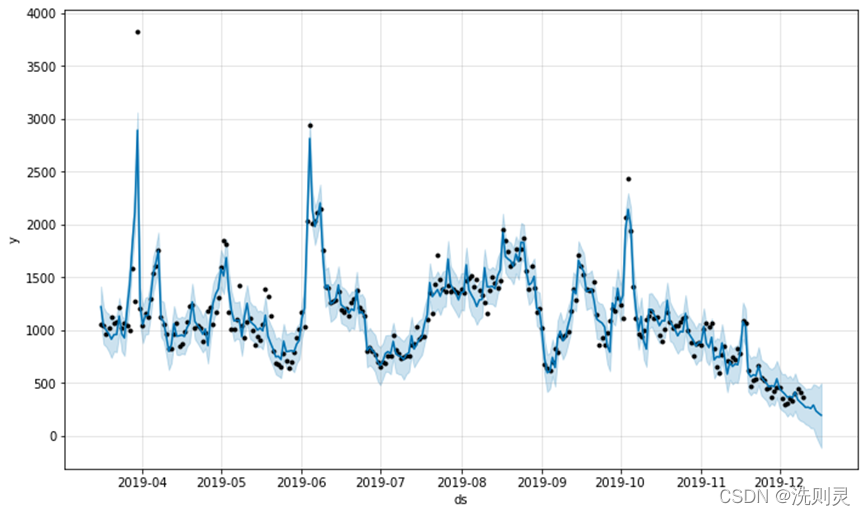
图2.5 百度指数时间序列拟合结果
Fig. 2.5 Time series fitting result of Baidu index
从此百度指数的时间序列图看,与图2.2(数据拟合结果)的历史客流量对比,难以看出之间的相关性,因此需要判断其季节趋势和周期性。
通过对数据的季节性总结,得到以下季节趋势,如图2.6所示。
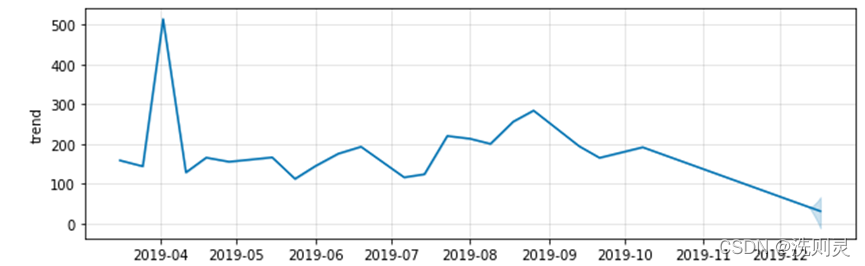
从季节趋势图上看,与图2.3(季节趋势)之间存在着波动幅度大小的差异,但百度指数的季节趋势仍然与H公园客流量的季节趋势有一定的相关性。
为进一步对比周期性,收索整理到百度指数的周期性如图2.7所示。
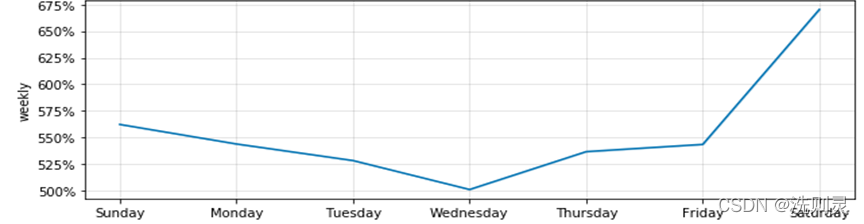
通过对比百度指数的周期性与H公园历史客流量的周期(图2.4)发现,其趋势大致相同。
通过以上的百度指数时间序列分析发现,百度指数可能与H公园客流量之间存在相关性,尽管并非特别明显。因此,为了更加准确的找到两者之间的相关性,还需做更进一步的检验。
2.3.2 相关性及协整检验
相关关系指变量之间存在着的非严格的不确定的关系,需要对它们进行深层次的分析,观察它们的密切程度。百度搜索指数与H公园历史客流量之间的相关性的计算采用了皮尔逊相关系数,其公式为:
r= (x-x')(y-y')(x-x')2(y-y')2 (2.3)
使用2019年3月至12月的全部数据进行相关性计算之后,得到两者之间的相关性为0.53448,相关性并不算太高。另外,由于上一节的讨论,本文采用的数据集为一个月的数据,因此,还需要考察两者之间一个月数据量的相关性。时间为2019年4月至12月,计算结果如图2.8所示。
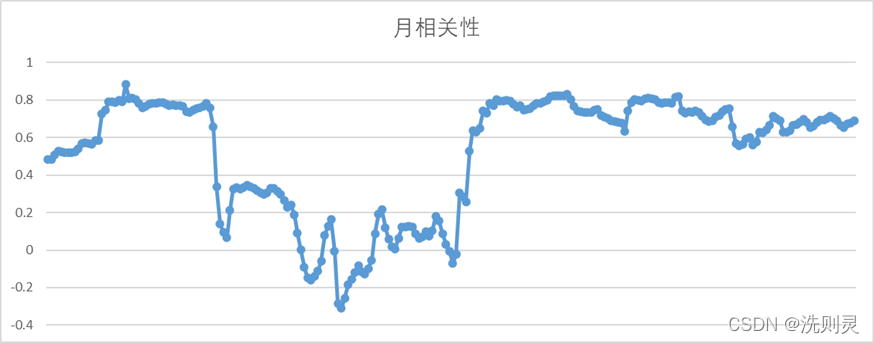
由图2.8可以明显看出,百度指数与H公园历史客流量之间的相关性有较大的波动性,甚至存在负相关,且有些时间段相关性并不高。因此,百度指数可能并不是一个好的变量,因为该变量的性质随时有可能改变。
此外,百度搜索指数与H公园历史客流量有可能是属于非平稳的时间序列,因此,在两者之间建立回归模型可能会出现伪回归,因此,为了检验两者之间是否存在长期均衡关系,在此使用协整检验。
协整理论Engle和格兰杰Granger在1978年提出的,主要是为了解决时间序列的非平稳性,或许单个序列是非平稳的,但是通过协整可以建立起两个或者多个序列之间的平稳关系,进而充分应用平稳性的性质,考察多个序列之间的长期均衡关系,避免伪回归的问题。
进行协整检验有一个前提条件,即序列之间必须同阶单整。本文利用Eviews进行单位根检验,采用ADF检验百度指数和H公园客流量的平稳性[17]。H公园客流量的ADF检验结果如下表2.1。
表2.1 客流量ADF检验
Table 2.1 ADF test of Passenger flow
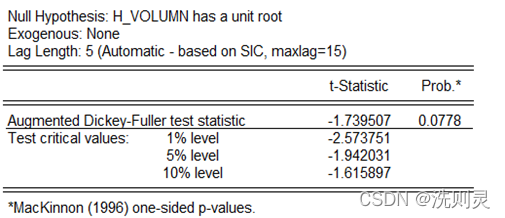
由结果可得,H公园客流量在10%的显著性水平下,是平稳的。
百度指数的ADF检验结果如下表2.2。
表2.2 百度指数ADF检验
Table 2.2 ADF test of Baidu index
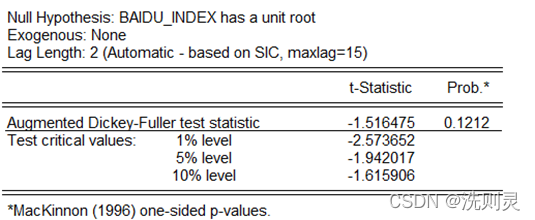
而百度指数在10%的显著性水平下,是不平稳的。因此,在两个原序列并不满足进行协整检验的前提条件.将原序列经过一阶差分后再次进行ADF检验,发现在1%的显著性水平下,是平稳的,因此百度指数是属于一阶单整,但H公园客流量是零阶单整,因此,不能进行协整检验,可以认为百度指数与H公园客流量之间不存在长期均衡关系。
3.1 数据集构建
根据上一章对于H公园客流量的时间序列分析结果来看,H公园客流量在较长的一段时间内,其趋势变化是比较大的,但是由于目前对于H公园客流量的影响因素识别不够充分,仅仅只有天气情况、气温、周次以及节假日,以上几个影响因素显然不能够反映H公园客流量的趋势变化情况。因此,数据集不能以全部历史数据来建立,由于变量不能反映真实的客流量变化情况,使用全部历史数据要么导致拟合不足,要么导致过拟合,两种情况都不利于预测的准确性。
另外,除了季节是属于模糊变量之外,还有许多未知的影响因素同样属于模糊变量,难以被构造成数值的形式,因此这些变量将不可避免的以“噪声”的形式存在。而更长时间的历史数据之中,必然包含更多的“噪声”,并且这些“噪声”的影响是不可忽略的,并不属于随机变量“白噪声”,它们只是无法描述,有些“噪声”的影响大,有些“噪声”的影响小,并且方向也有可能不同。如果使用的历史数据过少,则难以训练模型。因此,如何选择数据集,使“噪声”更少且其影响更趋于一致,是关乎预测准确性的重要问题。
根据上一章中对于H公园历史客流量的季节趋势的分析,客流量月之间的波动是比较大的,说明超过一个月时间的历史数据,其包含的“噪声”可能较多。
综合以上考虑,本文选用30-50天的历史数据作为训练集,以未来一天作为测试集,即在预测阶段,完善后模型(包括调整完参数、特征集)需要以过去30-50天的数据进行训练,再以得到的模型预测未来一天的客流量。
以上的做法进行以下的考虑。H公园的客流量预测与典型的数据挖掘任务不同。H公园客流量预测任务属于短期预测,在其历史数据上,时间越接近的数据,其参考价值也越大,权重也越高,因此在建模时,必须对新鲜的数据给予更多的重视,它更多的包含对于未来一天的客流量有用的信息,并且其“噪声”的影响更可能趋于一致。例如,在最近一个月的时间中,客流量高于平均情况,虽然并不清楚是哪些“噪声”的影响,但是可以推测出未来一天的客流量情况也应该高于平均情况,因为这些“噪声”是模糊变量,不存在突然消失或者突然出现的情况,否则这些“噪声”便能够被以“0-1”的形式记录下来。另外,H公园的客流量预测与天气预报情况有一定的相似之处,天气预报对于未来越长时间的预测,准确率也越低。目前由于计算机技术的发展,数值预报方法更多地应用于天气预报上,主要是利用当前天气情况,和一些已知的物理定理,通过计算机求解出来[18]。在数据集使用的30-50天训练数据中,就包含了“当前的天气情况”——“噪声”,和较为符合30-50天情况的“物理定理”——通过训练得出的模型,因此,能够较为准确地预测未来一天的情况。
综上所述,考虑到预测H公园客流量存在的客观问题,与典型的使用全部历史数据并按一定比例划分为训练集和测试集不同,本文在不违反数据集使用原则的情况下,采用上述的数据集构建方式。
3.2 特征集构建
在数据挖掘中,通常认为数据决定了模型的上限,算法只能尽可能地逼近这个上限。这里数据指的是经过特征工程之后得到的数据。特征工程指的是把原始数据转变为模型的训练数据的过程,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3181
3181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









