









1. 数据集介绍
MNIST手写数字数据集:
http://yann.lecun.com/exdb/mnist/
MNIST 数据集一共有 7 万张图片,其中 6 万张是训练集, 1 万张是测试集。每张图片是 28× 28 的 0−9 的手写数字图片组成。每个图片是黑底白字的形式,黑底用 0 表示,白字用 0-1 之间的浮点数表示,越接近 1 ,颜色越白。

2. 数据处理
下载后解压,会生成一系列的idx1-ubyte文件,需要先进行解析转换。
训练集解析代码:
import numpy as np
import struct
from PIL import Image
import os
# 定义MNIST数据文件的路径
data_file = r'MNIST_data/train-images.idx3-ubyte'
# 定义MNIST标签文件的路径
label_file = r'MNIST_data/train-labels.idx1-ubyte'
# 定义存储图像数据的根目录
datas_root = 'data/train'
# 设置数据文件的大小为47040016字节,但实际读取时应去掉16字节的头部信息
data_file_size = 47040016
data_file_size = str(data_file_size - 16) + 'B'
# 读取数据文件的全部内容
data_buf = open(data_file, 'rb').read()
# 解析数据文件头部的magic number, 图像数量, 图像行数和列数
magic, numImages, numRows, numColumns = struct.unpack_from('>IIII', data_buf, 0)
# 解析数据文件中所有图像的数据,去掉头部信息后为47040000字节
datas = struct.unpack_from('>' + data_file_size, data_buf, struct.calcsize('>IIII'))
# 将解析后的数据转换为NumPy数组,并调整形状为(numImages, 1, numRows, numColumns)
datas = np.array(datas).astype(np.uint8).reshape(numImages, 1, numRows, numColumns)
# 设置标签文件的大小为60008字节,但实际读取时应去掉8字节的头部信息
label_file_size = 60008
label_file_size = str(label_file_size - 8) + 'B'
# 读取标签文件的全部内容
label_buf = open(label_file, 'rb').read()
# 解析标签文件头部的magic number和标签数量
magic, numLabels = struct.unpack_from('>II', label_buf, 0)
# 解析标签文件中的所有标签数据,去掉头部信息后为60000字节
labels = struct.unpack_from('>' + label_file_size, label_buf, struct.calcsize('>II'))
# 将解析后的标签数据转换为NumPy数组
labels = np.array(labels).astype(np.int64)
# 如果根目录不存在,则创建该目录
if not os.path.exists(datas_root):
os.mkdir(datas_root)
# 为每个标签创建一个子目录
for i in range(10):
file_name = datas_root + os.sep + str(i)
if not os.path.exists(file_name):
os.mkdir(file_name)
# 将每张图像保存到对应标签的子目录下,并命名为mnist_train_索引.png
for ii in range(numLabels):
img = Image.fromarray(datas[ii, 0, 0:28, 0:28])
label = labels[ii]
file_name = datas_root + os.sep + str(label) + os.sep + 'mnist_train_' + str(ii) + '.png'
img.save(file_name)测试集解析代码:
import numpy as np
import struct
from PIL import Image
import os
# 定义MNIST数据文件的路径
data_file = r'MNIST_data/t10k-images.idx3-ubyte'
# 定义MNIST标签文件的路径
label_file = r'MNIST_data/t10k-labels.idx1-ubyte'
# 定义存储图像数据的根目录
datas_root = 'data/test'
# 设置数据文件的大小为7840016字节,但实际读取时应去掉16字节的头部信息
data_file_size = 7840016
data_file_size = str(data_file_size - 16) + 'B'
# 读取数据文件的全部内容
data_buf = open(data_file, 'rb').read()
# 解析数据文件头部的magic number, 图像数量, 图像行数和列数
magic, numImages, numRows, numColumns = struct.unpack_from(
'>IIII', data_buf, 0)
# 解析数据文件中所有图像的数据,去掉头部信息后为7840000字节
datas = struct.unpack_from(
'>' + data_file_size, data_buf, struct.calcsize('>IIII'))
# 将解析后的数据转换为NumPy数组,并调整形状为(numImages, 1, numRows, numColumns)
datas = np.array(datas).astype(np.uint8).reshape(
numImages, 1, numRows, numColumns)
# 设置标签文件的大小为10008字节,但实际读取时应去掉8字节的头部信息
label_file_size = 10008
label_file_size = str(label_file_size - 8) + 'B'
# 读取标签文件的全部内容
label_buf = open(label_file, 'rb').read()
# 解析标签文件头部的magic number和标签数量
magic, numLabels = struct.unpack_from('>II', label_buf, 0)
# 解析标签文件中的所有标签数据,去掉头部信息后为10000字节
labels = struct.unpack_from(
'>' + label_file_size, label_buf, struct.calcsize('>II'))
# 将解析后的标签数据转换为NumPy数组
labels = np.array(labels).astype(np.int64)
# 如果根目录不存在,则创建该目录
if not os.path.exists(datas_root):
os.mkdir(datas_root)
# 为每个标签创建一个子目录
for i in range(10):
file_name = datas_root + os.sep + str(i)
if not os.path.exists(file_name):
os.mkdir(file_name)
# 将每张图像保存到对应标签的子目录下,并命名为mnist_test_索引.png
for ii in range(numLabels):
img = Image.fromarray(datas[ii, 0, 0:28, 0:28])
label = labels[ii]
file_name = datas_root + os.sep + str(label) + os.sep + \
'mnist_test_' + str(ii) + '.png'
img.save(file_name)运行上述代码后,会在项目的data下分别生成train和test两个文件夹,每个文件下保存对应的图片:
3.构建Pytorch下的resnet152
部分示例
import torch
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
from torchvision.models import resnet152
import torch.nn as nn
import torch.optim as optim
from tqdm import tqdm
import argparse
import warnings
warnings.filterwarnings("ignore")
def init_argparse():
parser = argparse.ArgumentParser(description="手写体数字识别")
parser.add_argument("--train_path", type=str, default='data/test', help="训练集数据路径")
parser.add_argument("--test_path", type=str, default='data/test', help="测试集数据路径")
parser.add_argument("--epochs", type=int, default=5, help="训练轮数")
parser.add_argument("--batch_size", type=int, default=512, help="GPU批大小")
parser.add_argument("--num_workers", type=int, default=4, help="CPU进程")
parser.add_argument("--lr", type=float, default=0.001, help="学习率")
parser.add_argument("--momentum", type=float, default=0.9, help="动量")
parser.add_argument("--save", type=str, default='best.pt', help="权重保存名字")
return parser4. 结果展示
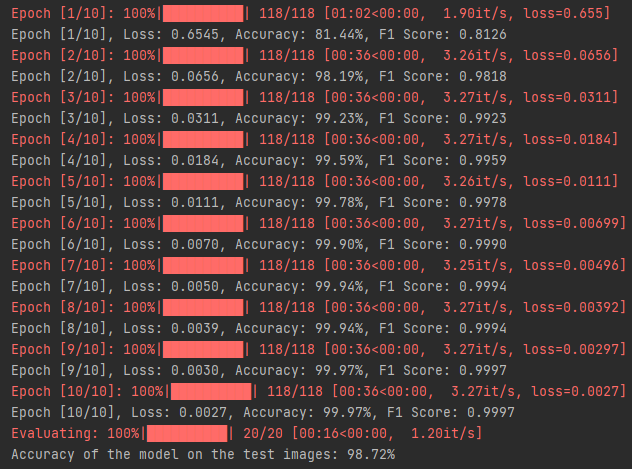
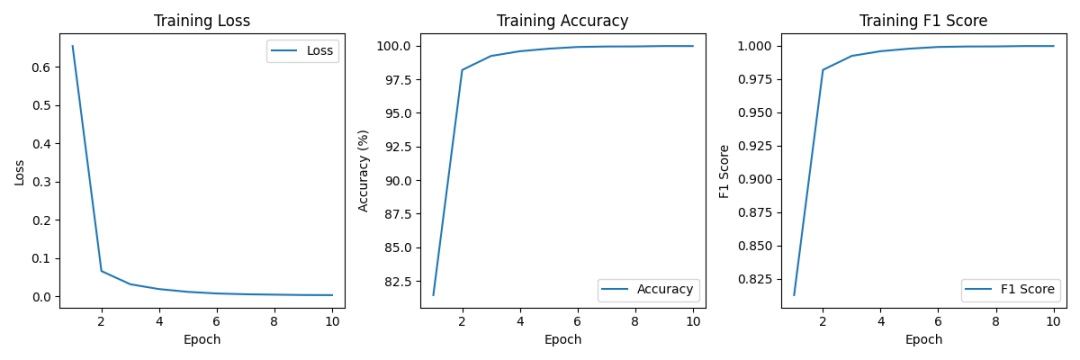
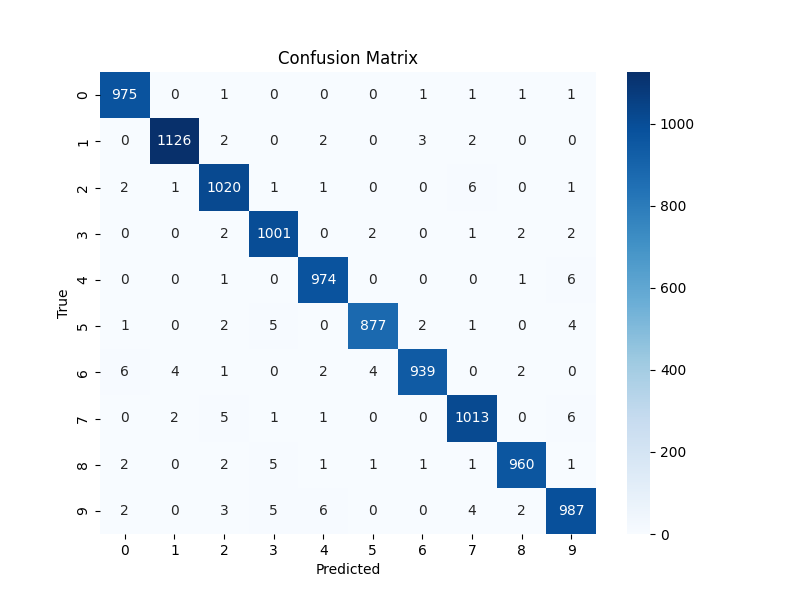
测试集混淆矩阵
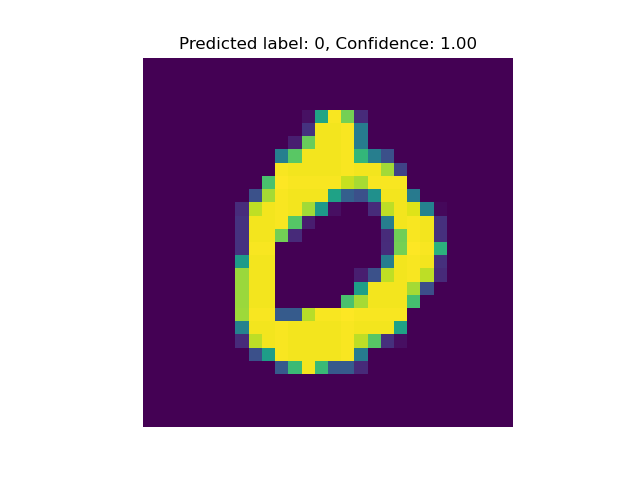
5. 单张图像数字识别
完整代码及数据集获取
Python图像处理——基于Pytorch框架ResNet152特征提取的MNIST手写数字识别
最后:
小编会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











