







摘要
传统自训练(self-training)方法采用固定的探索式算法,在不同数据集上表现不一。
本文采用强化学习框架学习数据选择策略,提供更可靠的数据。
介绍
处理零样本文本分类通常有两个主要的方法,目前工作主要在第1点,忽略了第2点:
- 整合更多的外部知识,建立更多复杂的类型连接
- 整合无标签数据提升泛化能力
直接用传统的自训练方式可能会遇到一些问题:
- 传统自训练方式采用手工制定的探索式算法选择数据,调整选择策略开销很大
- 传统的自训练方法在跨领域方面不太可靠,主要是数据选择方法不太可靠
本文主要贡献:
- 本文提出的方法利用了无标签数据,并且能够缓解领域迁移问题
- 提出了一个强化学习框架,可用于自动选择数据
- 实验效果在选定的数据集上提升很大
自训练
自训练有两个缺陷:
- 如果数据选择策略是简单的基于自信度,那么数据选择可能不太可靠,造成误差传播
- 自训练依赖于预先定义的自信度,不同数据集手动调整训练开销大
方法
模型框架如下:
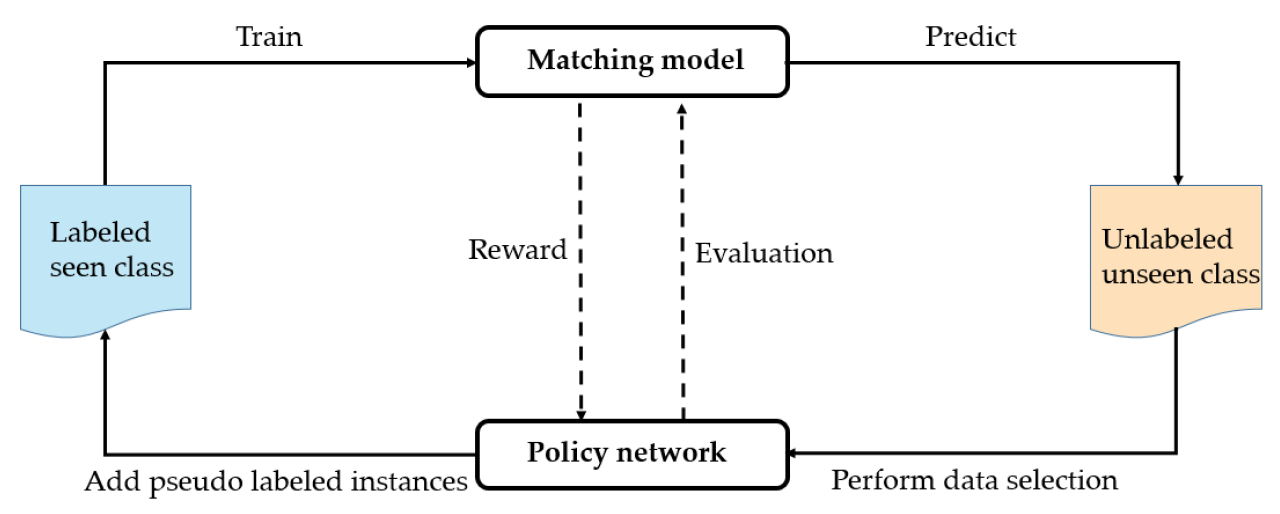
首先在训练集上训练基础的文本匹配模型,然后在测试集上预测。策略网络在预测的结果中进行样本的挑选,策略网络的奖励来源于匹配模型在验证集上的效果。若当前策略网络采取了正确的策略,挑选出了高质量的样本,那么模型期望会在验证集上获得较好的 performance,则会获得正向的奖励;相反若策略网络采取错误的策略,则模型获得较差的结果和负向的奖励。
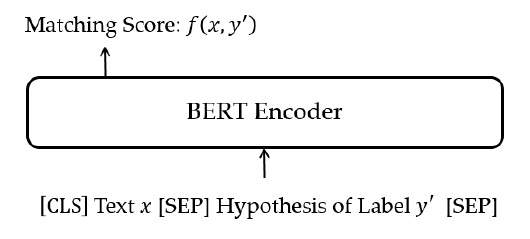
对于基础的文本匹配模型,本文采用了预训练模型 BERT,BERT 的输入为句子和类别文本的拼接输出为该句子和类别的匹配分数,如图所示。
强化学习模块
state:当前状态包括两部分:[CLS]对应的向量表示
c
x
,
y
∗
c_{x,y^*}
cx,y∗,以及预测的confidence分数
p
x
,
y
∗
p_{x,y*}
px,y∗
action:agent 需要判断是否选择当前实例
(
x
,
y
∗
)
(x, y^*)
(x,y∗)
reward:根据验证集的匹配效果计算 reward,计算公式如下:
r
k
=
(
F
k
s
−
μ
s
)
σ
s
+
λ
⋅
(
F
k
u
−
μ
u
)
σ
u
r_{k}=\frac{\left(F_{k}^{s}-\mu^{s}\right)}{\sigma^{s}}+\lambda \cdot \frac{\left(F_{k}^{u}-\mu^{u}\right)}{\sigma^{u}}
rk=σs(Fks−μs)+λ⋅σu(Fku−μu)
其中:
- F S F^S FS:可以看见类型的序列
- F U F^U FU:不可以看见类型的序列
- λ:权重
- μ:均值
- σ:方差
policy Network:使用多层感知机作为挑选策略网络,输入为state,输出为是否挑选当前实例的概率(action 的概率),计算公式如下,
z
t
=
ReLU
(
W
1
T
c
x
,
y
∗
+
W
2
T
p
x
,
y
∗
+
b
1
)
P
(
a
∣
s
t
)
=
softmax
(
W
3
T
z
t
+
b
2
)
\begin{gathered} z_{t}=\operatorname{ReLU}\left(W_{1}^{T} c_{x, y^{*}}+W_{2}^{T} p_{x, y^{*}}+b_{1}\right) \\ P\left(a \mid s_{t}\right)=\operatorname{softmax}\left(W_{3}^{T} z_{t}+b_{2}\right) \end{gathered}
zt=ReLU(W1Tcx,y∗+W2Tpx,y∗+b1)P(a∣st)=softmax(W3Tzt+b2)
其中:
- W 1 , W 2 , W 3 , b 1 , b 2 W_1, W_2, W_3, b_1, b_2 W1,W2,W3,b1,b2为多层感知机的参数
- P() 为 action 的概率
整个模型的伪代码如图:

实验
数据
数据集采用 EMNLP19年的工作:Yin W, Hay J, Roth D. Benchmarking zero-shot text classification: Datasets, evaluation and entailment approach[J]. In EMNLP 2019.
包括3个数据集:话题、情感、情景,另外再加电商数据集。去除掉多标签数据,只考虑单标签数据。
方法
文本匹配baseline方法:
- word2vec + 余弦相似度
- Label similarity:基于Sappadla Prateek Veeranna, Jinseok Nam, Eneldo Loza Mencıa, and Johannes F¨urnkranz. Using semantic similarity for multi-label zero-shot classification of text documents.工作,大致是用 embedding + 余弦相似度
- FC 和 RNN+ FC:基于Pushp P K, Srivastava M M. Train once, test anywhere: Zero-shot learning for text classification[J]. arXiv preprint arXiv:1712.05972, 2017.工作,分别对应于论文里的框架1和框架2
本文方法:
- 单纯的BERT
- BERT + self-training
- BERT + RL:就是本文的全部方法
结果
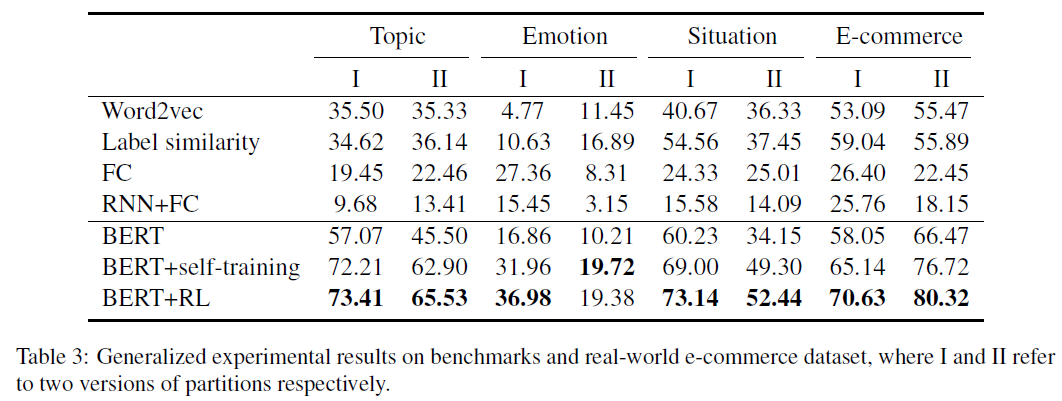
Generalized 方法:类标签来自看不见的类和看到的类
结果:平均提升了15.4%
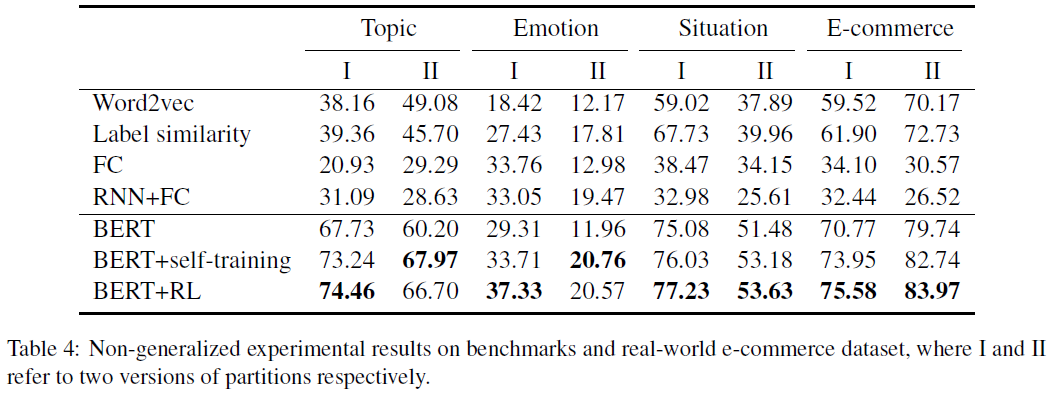
non-generalized 方法:类标签来自看不到的类
结果:平均提升了5.4%
总结
- Self-training可以有效利用未标注样本,减小训练类别和测试类别之间的domain shift;
- 基于强化学习的挑选策略(结合了performance-driven和confidence-based),优于传统confidence-based的greedy selection方法。















 849
849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









