





文本分类评估指标
Recently, zero-shot text classification attracted a huge interest due to its simplicity. In this post, we will see how to use zero-shot text classification with any labels and explain the background model. Then, we will evaluate its performance by human annotated datasets in sentiment analysis, news categorization, and emotion classification.
最近,零镜头文本分类由于其简单性而引起了极大的兴趣。 在这篇文章中,我们将看到如何对任何标签使用零击文本分类并解释背景模型。 然后,我们将通过情感分析,新闻分类和情感分类中的人类注释数据集评估其性能。
Zero-Shot Text Classification
零射文本分类
In zero-shot text classification, the model can classify any text between given labels without any prior data.
在零击文本分类中,该模型可以对给定标签之间的任何文本进行分类,而无需任何先验数据。
With zero-shot text classification, it is possible to perform:
使用零击文本分类,可以执行:
- Sentiment analysis 情绪分析
- News categorization新闻分类
- Emotion analysis情绪分析
背景(Background)
Actually, the latest implementations of zero-shot text classification born out of a very simple but brilliant idea. There is a field called Natural Language Inference (NLI) in NLP. This field investigates whether a hypothesis is true (entailment), false (contradiction), or undetermined (neutral) for a given premise.
实际上,零镜头文本分类的最新实现源于一个非常简单但精妙的想法。 NLP中有一个称为自然语言推断(NLI)的字段。 该字段调查给定前提的假设是正确的(蕴含),错误的(矛盾)还是不确定的(中立)。
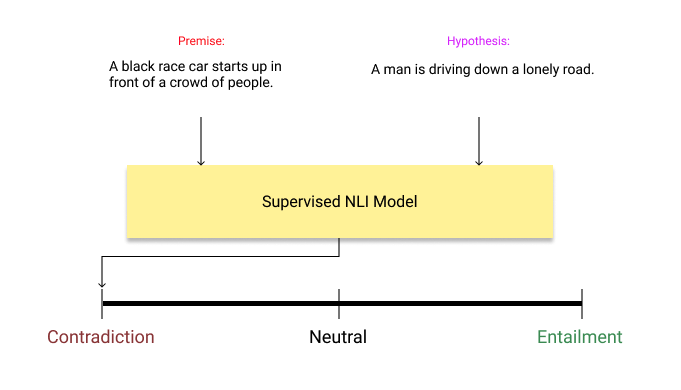
Now, let’s assume our text is “I love this movie.” and we want to predict the sentiment of the text between candidate labels of positive and negative. We give these two hypothesis-premise pairs to already trained NLI model and check the results.
现在,假设我们的文字是“我喜欢这部电影”。 我们要预测正面和负面的候选标签中的文字的感悟。 我们将这两个假设-前提对提供给已经训练好的NLI模型,并检查结果。
Premise: I love this movie.Hypothesis-1: This example is positive.
前提:我喜欢这部电影。 假设1:这个例子是肯定的。
Premise: I love this movie.Hypothesis-2: This example is negative.
前提:我喜欢这部电影。 假设2:这个例子是负面的。
Basically, it creates hypothesis template of “this example is …” for each class to predict the class of the premise. If the inference is entailment, it means that the premise belongs to that class. In this case, it is positive.
基本上,它为每个类别创建“此示例为...”的假设模板以预测前提的类别。 如果推断是必然的,则意味着前提属于该类别。 在这种情况下,它是肯定的。
码 (Code)
Thanks to HuggingFace, it can be easily used through the pipeline module.
感谢HuggingFace,它可以通过管道模块轻松使用。
#!pip install transformers datasets
from transformers import pipelineclassifier = pipeline("zero-shot-classification", device=0) #GPUcandidate_labels = ["positive", "negative"]
text = "I don't know why I like this movie so well, but I never get tired of watching it."
classifier(text, candidate_labels)> {'labels': ['positive', 'negative'],
> 'scores': [0.8987422585487366, 0.10125774145126343],
> 'sequence': "I don't know why I like this movie so well, but I
never get tired of watching it."}In the first example, we initialize the classifier from transformers pipeline and then give an example from IMDB dataset. You can see that the classifier produces scores for each label. In the first example, it predicts the sentiment of the text as positive, correctly.
在第一个示例中,我们从变压器管道初始化分类器,然后从IMDB数据集给出示例。 您可以看到分类器为每个标签生成分数。 在第一个示例中,它正确地预测了文本的积极情绪。
candidate_labels = ["world", "sports", "business", "sci/tech"]
text = "Quality Gets Swept Away Quality Distribution is hammered after reporting a large loss for the second quarter."
classifier(text, candidate_labels)> {'labels': ['business', 'world', 'sci/tech', 'sports'],
> 'scores': [0.8066419363021851, 0.16538377106189728, 0.018306914716959, 0.009667363949120045],
> 'sequence': 'Quality Gets Swept Away Quality Distribution is hammered after reporting a large loss for the second quarter.'}Our second example is for news categorization from AG News dataset. It correctly predicts the news in business category.
我们的第二个示例是从AG News数据集中对新闻进行分类的。 它可以正确预测业务类别中的新闻。
candidate_labels = ["anger", "fear", "joy", "love", "sadness", "surprise"]
text = "i didnt feel humiliated"
classifier(text, candidate_labels)> {'labels': ['surprise', 'joy', 'love', 'sadness', 'fear', 'anger'],
> 'scores': [0.66361004114151, 0.1976112276315689, 0.04634414240717888, 0.03801531344652176, 0.03516925126314163, 0.01925000175833702],
> 'sequence': 'i didnt feel humiliated'}In our last example, we investigated an example from Emotion dataset. Zero-shot classification model predicts emotion of the sentence “i didnt feel humiliated” as surprise, however gold label is sadness.
在我们的最后一个示例中,我们研究了Emotion数据集中的一个示例。 零镜头分类模型预测了“我没有被羞辱”一词的情绪令人惊讶,但是金标是悲伤。
评价 (Evaluation)
Zero-shot classification looks promising in these examples. However, its performance should be evaluated with correct measurements by using already labeled examples.
在这些示例中,零镜头分类看起来很有希望。 但是,应使用已标记的示例通过正确的测量来评估其性能。

By using the latest dataset library of HuggingFace, we can easily evaluate its performance on several datasets.
通过使用最新的HuggingFace数据集库,我们可以轻松地评估其在多个数据集上的性能。
IMDB dataset: sentiment analysis
IMDB数据集:情感分析
Classes:
类:
positive, negative
正负
AG-News dataset: news categorization
AG-News数据集:新闻分类
Classes:
类:
world, sports, business, sci/tech
世界,体育,商业,科技
Emotion dataset: emotion classification
情绪数据集:情绪分类
Classes:
类:
anger, fear, joy, love, sadness, surprise
愤怒,恐惧,喜悦,爱,悲伤,惊奇
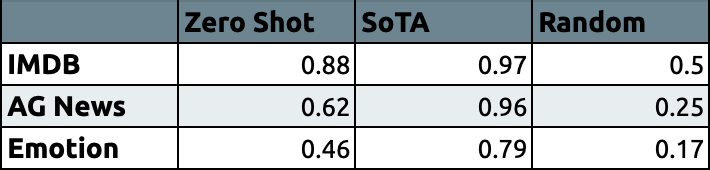
Let’s compare our zero-shot text classification model with the state-of-the-art models and random pick in micro-average F1.
让我们将零射文本分类模型与最新模型和微观平均F1中的随机选择进行比较。
For more details about initializing zero-shot classification pipeline and evaluation code, check out this well-prepared Colab Notebook:
有关初始化零镜头分类管道和评估代码的更多详细信息,请查看此准备充分的Colab笔记本:
结论 (Conclusion)
We can see that zero-shot text classification performs significant results in sentiment analysis and news categorization. The performance in the emotion classification with 6 class is rather poor. I believe that it might be due to the similarity between classes. It is a very hard task to make a distinction between joy, love, and surprise classes without any prior data.
我们可以看到零击文本分类在情感分析和新闻分类中表现出显着的效果。 6类情感分类的表现较差。 我相信这可能是由于类之间的相似性。 在没有任何先验数据的情况下,区分欢乐,爱情和惊喜类别是一项艰巨的任务。
Performance of zero-shot classification is lower than supervised models for each task as expected. Even so, it’s worth trying if you don’t have any data for a specific classification problem!
按预期,零镜头分类的性能低于监督模型。 即使这样,如果您没有任何有关特定分类问题的数据,还是值得尝试的!
Originally published at https://akoksal.com.
最初发布在https://akoksal.com 。
Follow me on Twitter: https://twitter.com/alkksl
在Twitter上关注我: https : //twitter.com/alkksl
翻译自: https://towardsdatascience.com/zero-shot-text-classification-evaluation-c7ba0f56688e
文本分类评估指标














 1015
1015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









