





 本文介绍了一种利用预训练模型实现零样本文本分类的技术,并通过HuggingFace的pipeline进行了实践,展示了如何通过调整模板和候选标签来进行主题识别、问题回答及情感分析。
本文介绍了一种利用预训练模型实现零样本文本分类的技术,并通过HuggingFace的pipeline进行了实践,展示了如何通过调整模板和候选标签来进行主题识别、问题回答及情感分析。
PS:用deepL翻译的这篇博客,感觉翻译的一般,建议看原文。
零样本学习(Zero-shot learning,ZSL)是一种机器学习范式,它引入了用初始训练阶段从未观察到的类标签测试样本的想法。这类似于我们人类在长期收集的现有知识的基础上,将我们的学习结果推断到新的概念。ZSL范式最近变得越来越流行,这主要是因为获得任何特定领域的标签数据是一个相当昂贵和耗时的过程。根据你想优化的成本,你可以让主题专家(SME)给每个输入样本贴上标签,或者向他们寻求帮助,编写任务和特定领域的手工制作的规则,帮助以每周监督的方式启动训练阶段。ZSL在机器学习的各个垂直领域有许多应用,其中一些流行的和有趣的应用是文本分类、图像分类、文本到图像生成、语音翻译等。
文本分类是为一个给定的文本片段分配一组预定义的类别的任务。它通常是在有监督的环境下建模的,你有特定领域文本的标记数据及其相关的类别标签/类别。然后你学习一些映射函数X->Y;其中,X:输入样本,Y:类别。文本分类的一些例子包括 - 情感分析、垃圾邮件分类、新闻分类等等。请随时关注本博客,了解使用变形金刚进行文本分类的快速教程。
因此,零样本文本分类是指将给定的文本归类到一些预先定义的组或类标签,而不需要在包含文本和标签映射的下游数据集上明确地训练一个专门的机器学习模型。
如果你不经常使用NLP,有可能没有听说过Hugging Face 🤗。但是,作为复习,Hugging Face是一个机器学习技术的开源和平台供应商。它在NLP开发者中得到了真正的普及,因为它的变形金刚支持,为下载、训练和推断最先进的NLP模型提供了一个简单的方法。
在这篇博客中,我们将通过一个快速教程,介绍如何使用Hugging Face🤗的零样本文本分类的管道/流水线(pipeline),并讨论使之成为可能的算法的内部情况。
首先安装transformers
pip install transformersHugging Face提供了管道的概念,通过抽象出大部分复杂的代码,使得从已经训练好的模型中进行推断变得非常容易。我们将在 "零点分类 "的任务中使用同样的想法。管道类是基类,所有特定任务的管道都继承于此。因此,在管道中定义任务会触发一个特定任务的子管道,在这种情况下,它将是ZeroShotClassificationPipeline。还有许多其他的任务,你可以去探索,值得花一些时间去看抱脸管道任务的整个任务列表。
接下来,我们继续导入pipeline,并定义一个相关的任务,促进任务的底层模型(关于模型的更多信息将在后面的章节中介绍),以及设备(device=0或任何正值是指使用GPU,device=-1是指使用CPU)。
from transformers import pipeline
classifier = pipeline(
task="zero-shot-classification",
device=0,
model="facebook/bart-large-mnli"
)一旦我们的分类器对象准备好了,我们就把text_piece的例子、候选标签和多类预测与否的选择传进去。
import pprint
text_piece = "The food at this place is really good."
labels = ["Food", "Employee", "Restaurant", "Party", "Nature", "Car"]
predictions = classifier(text_piece, labels, multi_class=False)
pprint.pprint(predictions){'labels': ['Food', 'Restaurant', 'Employee', 'Car', 'Party', 'Nature'],
'scores': [0.6570185422897339,
0.15241318941116333,
0.10275784879922867,
0.04373772069811821,
0.027072520926594734,
0.01700017973780632],
'sequence': 'The food at this place is really good.'}从上面的片段可以看出,我们的模型在候选标签集上输出了一个Softmax分布。该模型似乎已经完美地捕捉到了围绕所谈论的中心主题的意图,即食物。
现在,让我们调整一下,加入一个特定的模式,试图以我们希望的方式进行分类。我把模板写成 "食客在{}",模型应该在括号"{}"中填入与上下文有关的位置。让我们看看这个模型是否足够聪明,能够做到这一点。
import pprint
text_piece = "The food at this place is really good."
labels = ["Food", "Employee", "Restaurant", "Party", "Nature", "Car"]
template = "The diners are in the {}"
predictions = classifier(text_piece,
labels,
multi_class=False,
hypothesis_template=template
){'labels': ['Food', 'Restaurant', 'Employee', 'Car', 'Party', 'Nature'],
'scores': [0.6570185422897339,
0.15241318941116333,
0.10275784879922867,
0.04373772069811821,
0.027072520926594734,
0.01700017973780632],
'sequence': 'The food at this place is really good.'}哇! 该模型得到了这个正确的结果(在最可能的意义上)。考虑到我们的模型从未被明确地训练为回答问题式的文本分类,其表现似乎仍然相当不错
(PS:原文这里加了template之后的结果与不加template的结果是一样的,但我自己测试的时候结果是不同的,可能是他写错了。我用的模型是mDeBERTa-v3-base-mnli-xnli,结果如下。
不使用template:
import pprint
text_piece = "The food at this place is really good."
labels = ["Food", "Employee", "Restaurant", "Party", "Nature", "Car"]
predictions = classifier(text_piece, labels, multi_class=False)
pprint.pprint(predictions)The `multi_class` argument has been deprecated and renamed to `multi_label`. `multi_class` will be removed in a future version of Transformers.
{'labels': ['Food', 'Restaurant', 'Employee', 'Nature', 'Party', 'Car'],
'scores': [0.7872213125228882,
0.16676197946071625,
0.013325047679245472,
0.013299668207764626,
0.011664658784866333,
0.007727398071438074],
'sequence': 'The food at this place is really good.'}使用template:
import pprint
text_piece = "The food at this place is really good."
labels = ["Food", "Employee", "Restaurant", "Party", "Nature", "Car"]
template = "The diners are in the {}"
predictions = classifier(text_piece,
labels,
multi_class=False,
hypothesis_template=template
)
pprint.pprint(predictions)The `multi_class` argument has been deprecated and renamed to `multi_label`. `multi_class` will be removed in a future version of Transformers.
{'labels': ['Restaurant', 'Food', 'Car', 'Nature', 'Employee', 'Party'],
'scores': [0.45250198245048523,
0.27823406457901,
0.08449206501245499,
0.0671515092253685,
0.059678733348846436,
0.05794164910912514],
'sequence': 'The food at this place is really good.'})
让我们这次再框定一个模板和不同的候选集来定义文本中传达的整体情感。
import pprint
text_piece = "The food at this place is really good."
labels = ["Positive", "Negative", "Neutral"]
template = "The sentiment of this review is {}"
predictions = classifier(text_piece,
labels,
multi_class=False,
hypothesis_template=template
)
pprint.pprint(predictions){'labels': ['Positive', 'Neutral', 'Negative'],
'scores': [0.8981141448020935, 0.07974622398614883, 0.02213958650827408],
'sequence': 'The food at this place is really good.'}很好! 通过上面讨论的例子,很明显,这个问题的表述可以推广到各种下游任务。你现在可以继续玩下去,建立其他的零散的用例。另外,请随时查看这个在线演示。现在,让我们继续前进,深入了解一些小细节。
藏在表面之下的机制/结构:
在这一部分,我们将研究在调用管道时,引擎盖下有哪些步骤,看看系统究竟如何在没有明确训练的情况下,将我们的文本正确分类为相关标签。
管道的工作流程是一组堆叠的函数,定义如下------
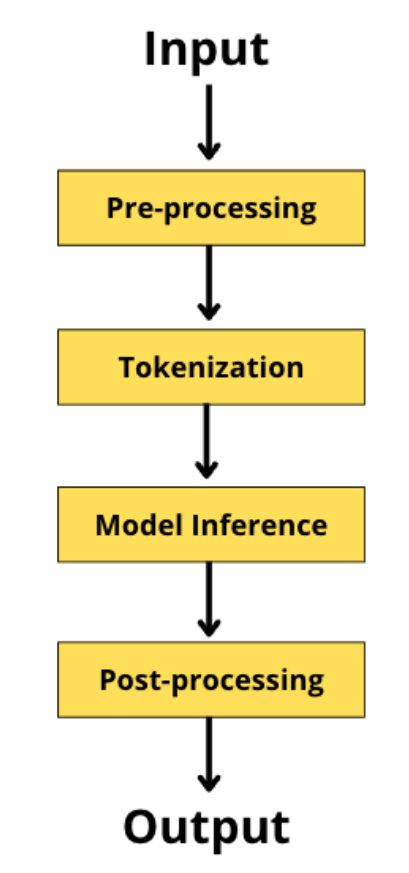
如上图所示,我们从文本序列开始输入,然后根据底层预训练模型和使用情况,在需要的地方添加任何必要的特殊标记(如SEP、CLS等)。然后,我们使用标记器,将我们的序列分成更小的块,将其映射到预定义的词汇索引,并通过我们的模型进行推理。下一步,后处理,是可选的,取决于使用情况和基础模型的输出。这包括任何需要做的额外工作,如删除特殊标记,修剪到特定的最大长度,等等。最后,我们以我们的输出结束。
谈到上图中的推理步骤,底层模型(facebook/bart-large-mnli)被训练为自然语言推理(NNLI)的任务。NLI的任务是确定两个序列,"前提 "和 "假设 "是否彼此相随(entails)或不相随(concadict),或未确定(中性)或彼此不相关。按照下面这个来自nlpprogress的例子,可以更好地理解它 -
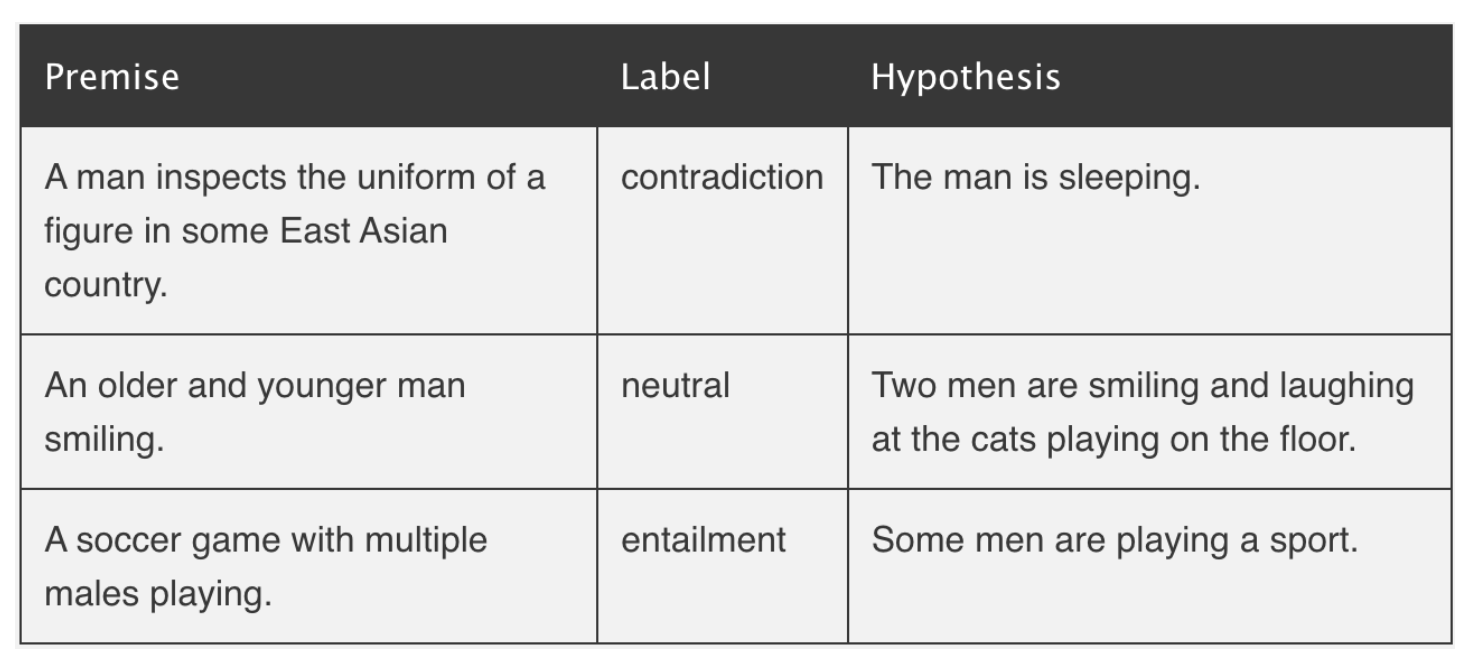
"facebook/bart-large-mnli "在多流派自然语言推理(MNLI)语料库上对BART模型进行了微调。该语料库有近50万个句子对,并标注了文本尾随信息。BART模型的输入是一对序列(前提和假设),针对一个长度为3的热输出向量(蕴涵、中性、矛盾)进行训练。
令人惊讶的是,这个问题的表述可以通过将文本片段和候选标签分别作为前提和假设来适应零拍文本分类的任务。希望通过对NLI任务的预训练,该模型现在能够理解并学习两个文本片段之间的错综复杂的关系。这些知识现在可以被用来确定候选标签集中的任何标签是否包含该文本片段。如果是,我们就把这个候选标签当作真正的标签。你可以通过加载 "joeddav/xlm-roberta-large-xnli "将同样的技术扩展到非英语句子,这是一个在XLM RoBERTa之上的XNLI数据集上微调的跨语言模型。
结论性的想法
那么这篇博客就到此为止。无论我们今天讨论的是什么,都只是进行零散文本分类的一种可能方式。我们看到了扩展NLI问题表述的方法,可以做主题识别、问题回答和情感分析。但是根据提示的格式,可能性是无穷的。你可以在Zero-Shot Learning in Modern NLP中阅读更多的方法,并关注这个播放列表,了解NLP中Zero-shot和Few-shot学习的最新研究。
谢谢你!

















 1924
1924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









