






视频教程:B站、网易云课堂、腾讯课堂
代码地址:Gitee、Github
存储地址:
百度云-提取码:
Google云
- SSD-Model(pytorch版本)
《SSD:Single Shot MultiBox Dectector》
–单点多尺寸目标检测器
作者:Wei Lu,etc
单位:
发表会议及时间:ECCV 2016
Submission history
边框回归是怎么做到的
实际上是,将P(推荐框)和G(真实框)之间的差值α,通过损失函数,将α与模型的输出w*x进行关联,将w*x逼近-α,这样的话通过输出就可以将P框+w*x就可以得到逼近G框的预测框
- Abstract
We present a method for detecting objects in images using a single deep neural network. Our approach, named SSD, discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location.
At prediction time, the network generates scores for the presence of each object category in each default box and produces adjustments to the box to better match the object shape. Additionally, the network combines predictions from multiple feature maps with different resolutions to naturally handle objects of various sizes.
Our SSD model is simple relative to methods that require object proposals because it completely eliminates proposal generation and subsequent pixel or feature resampling stage and encapsulates all computation in a single network. This makes SSD easy to train and straightforward to integrate into systems that require a detection component.
Experimental results on the PASCAL VOC, MS COCO, and ILSVRC datasets confirm that SSD has comparable accuracy to methods that utilize an additional object proposal step and is much faster, while providing a unified framework for both training and inference.
Compared to other single stage methods, SSD has much better accuracy, even with a smaller input image size. For 300×300 input, SSD achieves 72.1% mAP on VOC2007 test at 58 FPS on a Nvidia Titan X and for 500×500 input, SSD achieves 75.1% mAP, outperforming a comparable state of the art Faster R-CNN model.
一 论文导读
补充:fps=frame per second 每秒多少帧
30fps是可以勉强实用的
检测有两类阈值:置信度、IOU值
极大值抑制:两两比较,在IOU值大于60%的之中删除置信度小的,这样一直删除下去,剩下最后一个。
深度学习的检测,都是在特征图上采样,减少了推荐框的数量,提升了速度
图像检测的精度一般要求是在70%左右

看到上面这个图,我突然恍然大悟,以前一个很搞笑的问题,我突然懂了。就是为什么锚框只有1*1,1*3,3*3等等那么大,为什么可以表示原图那么大。emmmmm,好吧,其实我应该在就知道,有点懵,怎么突然有一种恍然大悟的感觉。
这里做个补充吧:也很重要
小特征图的大Anchor框用来捕捉-大物体
大特征图的小Anchor框用来捕捉-小物体
在计算边框box的时候,要记住有三种框,一是groundtruth 二是卷积的扫描框 三是置信度最大的框,由此三框计算出边框损失

优点:
- 速度快
- 在不同层次的feature map 上进行预测,还设置了不同比例的推荐框
- 可以确保低分辨率的图像,检测也比较准确
- 损失函数
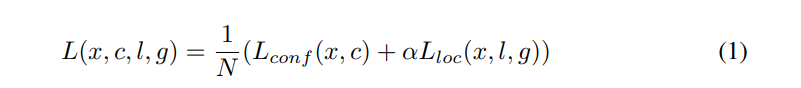
α决定了偏向于那种精度需求,1.5就更要求位置精度,0.5就更要求分类精度

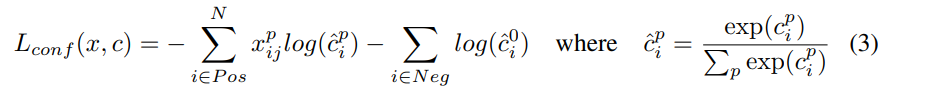















 7179
7179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









