






YOLO-v5
- Yolo-V5
https://github.com/ultralytics/yolov5
自定义数据集
因特尔加速
TensorRT加速
一 分类
二 检测
训练
python train.py --data coco.yaml --cfg yolov5s.yaml --weights '模型路径' --batch-size 16
预测
python detect.py --weights '模型路径' --source '图像路径、图像文件夹路径、视频路径、视频网址、图像网址'
导出ONNX
三 分割加检测
1.训练
python segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640
2.预测
python segment/predict.py --weights yolov5m-seg.pt --data data/images/bus.jpg
3.验证
python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 # validate
== 引入工具包 ==
== step 0 参数配置 ==
== step 1 数据处理 ==
class LoadImagesAndLabels(Dataset):
# YOLOv5 train_loader/val_loader, loads images and labels for training and validation
cache_version = 0.6 # dataset labels *.cache version
rand_interp_methods = [cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4]
def __init__(self,
path,
img_size=640,
batch_size=16,
augment=False,
hyp=None,
rect=False,
image_weights=False,
cache_images=False,
single_cls=False,
stride=32,
pad=0.0,
min_items=0,
prefix=''):
self.img_size = img_size
self.augment = augment
self.hyp = hyp
self.image_weights = image_weights
self.rect = False if image_weights else rect
self.mosaic = self.augment and not self.rect # load 4 images at a time into a mosaic (only during training)
self.mosaic_border = [-img_size // 2, -img_size // 2]
self.stride = stride
self.path = path
self.albumentations = Albumentations(size=img_size) if augment else None
try:
f = [] # image files
for p in path if isinstance(path, list) else [path]:
p = Path(p) # os-agnostic
if p.is_dir(): # dir
f += glob.glob(str(p / '**' / '*.*'), recursive=True)
# f = list(p.rglob('*.*')) # pathlib
elif p.is_file(): # file
with open(p) as t:
t = t.read().strip().splitlines()
parent = str(p.parent) + os.sep
f += [x.replace('./', parent, 1) if x.startswith('./') else x for x in t] # to global path
# f += [p.parent / x.lstrip(os.sep) for x in t] # to global path (pathlib)
else:
raise FileNotFoundError(f'{prefix}{p} does not exist')
self.im_files = sorted(x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in IMG_FORMATS)
# self.img_files = sorted([x for x in f if x.suffix[1:].lower() in IMG_FORMATS]) # pathlib
assert self.im_files, f'{prefix}No images found'
except Exception as e:
raise Exception(f'{prefix}Error loading data from {path}: {e}\n{HELP_URL}') from e
# Check cache
self.label_files = img2label_paths(self.im_files) # labels
cache_path = (p if p.is_file() else Path(self.label_files[0]).parent).with_suffix('.cache')
try:
cache, exists = np.load(cache_path, allow_pickle=True).item(), True # load dict
assert cache['version'] == self.cache_version # matches current version
assert cache['hash'] == get_hash(self.label_files + self.im_files) # identical hash
except Exception:
cache, exists = self.cache_labels(cache_path, prefix), False # run cache ops
# Display cache
nf, nm, ne, nc, n = cache.pop('results') # found, missing, empty, corrupt, total
if exists and LOCAL_RANK in {-1, 0}:
d = f'Scanning {cache_path}... {nf} images, {nm + ne} backgrounds, {nc} corrupt'
tqdm(None, desc=prefix + d, total=n, initial=n, bar_format=TQDM_BAR_FORMAT) # display cache results
if cache['msgs']:
LOGGER.info('\n'.join(cache['msgs'])) # display warnings
assert nf > 0 or not augment, f'{prefix}No labels found in {cache_path}, can not start training. {HELP_URL}'
# Read cache
[cache.pop(k) for k in ('hash', 'version', 'msgs')] # remove items
labels, shapes, self.segments = zip(*cache.values())
nl = len(np.concatenate(labels, 0)) # number of labels
assert nl > 0 or not augment, f'{prefix}All labels empty in {cache_path}, can not start training. {HELP_URL}'
self.labels = list(labels)
self.shapes = np.array(shapes)
self.im_files = list(cache.keys()) # update
self.label_files = img2label_paths(cache.keys()) # update
# Filter images
if min_items:
include = np.array([len(x) >= min_items for x in self.labels]).nonzero()[0].astype(int)
LOGGER.info(f'{prefix}{n - len(include)}/{n} images filtered from dataset')
self.im_files = [self.im_files[i] for i in include]
self.label_files = [self.label_files[i] for i in include]
self.labels = [self.labels[i] for i in include]
self.segments = [self.segments[i] for i in include]
self.shapes = self.shapes[include] # wh
# Create indices
n = len(self.shapes) # number of images
bi = np.floor(np.arange(n) / batch_size).astype(int) # batch index
nb = bi[-1] + 1 # number of batches
self.batch = bi # batch index of image
self.n = n
self.indices = range(n)
# Update labels
include_class = [] # filter labels to include only these classes (optional)
include_class_array = np.array(include_class).reshape(1, -1)
for i, (label, segment) in enumerate(zip(self.labels, self.segments)):
if include_class:
j = (label[:, 0:1] == include_class_array).any(1)
self.labels[i] = label[j]
if segment:
self.segments[i] = segment[j]
if single_cls: # single-class training, merge all classes into 0
self.labels[i][:, 0] = 0
# Rectangular Training
if self.rect:
# Sort by aspect ratio
s = self.shapes # wh
ar = s[:, 1] / s[:, 0] # aspect ratio
irect = ar.argsort()
self.im_files = [self.im_files[i] for i in irect]
self.label_files = [self.label_files[i] for i in irect]
self.labels = [self.labels[i] for i in irect]
self.segments = [self.segments[i] for i in irect]
self.shapes = s[irect] # wh
ar = ar[irect]
# Set training image shapes
shapes = [[1, 1]] * nb
for i in range(nb):
ari = ar[bi == i]
mini, maxi = ari.min(), ari.max()
if maxi < 1:
shapes[i] = [maxi, 1]
elif mini > 1:
shapes[i] = [1, 1 / mini]
self.batch_shapes = np.ceil(np.array(shapes) * img_size / stride + pad).astype(int) * stride
# Cache images into RAM/disk for faster training
if cache_images == 'ram' and not self.check_cache_ram(prefix=prefix):
cache_images = False
self.ims = [None] * n
self.npy_files = [Path(f).with_suffix('.npy') for f in self.im_files]
if cache_images:
b, gb = 0, 1 << 30 # bytes of cached images, bytes per gigabytes
self.im_hw0, self.im_hw = [None] * n, [None] * n
fcn = self.cache_images_to_disk if cache_images == 'disk' else self.load_image
results = ThreadPool(NUM_THREADS).imap(fcn, range(n))
pbar = tqdm(enumerate(results), total=n, bar_format=TQDM_BAR_FORMAT, disable=LOCAL_RANK > 0)
for i, x in pbar:
if cache_images == 'disk':
b += self.npy_files[i].stat().st_size
else: # 'ram'
self.ims[i], self.im_hw0[i], self.im_hw[i] = x # im, hw_orig, hw_resized = load_image(self, i)
b += self.ims[i].nbytes
pbar.desc = f'{prefix}Caching images ({b / gb:.1f}GB {cache_images})'
pbar.close()
def check_cache_ram(self, safety_margin=0.1, prefix=''):
# Check image caching requirements vs available memory
b, gb = 0, 1 << 30 # bytes of cached images, bytes per gigabytes
n = min(self.n, 30) # extrapolate from 30 random images
for _ in range(n):
im = cv2.imread(random.choice(self.im_files)) # sample image
ratio = self.img_size / max(im.shape[0], im.shape[1]) # max(h, w) # ratio
b += im.nbytes * ratio ** 2
mem_required = b * self.n / n # GB required to cache dataset into RAM
mem = psutil.virtual_memory()
cache = mem_required * (1 + safety_margin) < mem.available # to cache or not to cache, that is the question
if not cache:
LOGGER.info(f'{prefix}{mem_required / gb:.1f}GB RAM required, '
f'{mem.available / gb:.1f}/{mem.total / gb:.1f}GB available, '
f"{'caching images ✅' if cache else 'not caching images ⚠️'}")
return cache
def cache_labels(self, path=Path('./labels.cache'), prefix=''):
# Cache dataset labels, check images and read shapes
x = {} # dict
nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number missing, found, empty, corrupt, messages
desc = f'{prefix}Scanning {path.parent / path.stem}...'
with Pool(NUM_THREADS) as pool:
pbar = tqdm(pool.imap(verify_image_label, zip(self.im_files, self.label_files, repeat(prefix))),
desc=desc,
total=len(self.im_files),
bar_format=TQDM_BAR_FORMAT)
for im_file, lb, shape, segments, nm_f, nf_f, ne_f, nc_f, msg in pbar:
nm += nm_f
nf += nf_f
ne += ne_f
nc += nc_f
if im_file:
x[im_file] = [lb, shape, segments]
if msg:
msgs.append(msg)
pbar.desc = f'{desc} {nf} images, {nm + ne} backgrounds, {nc} corrupt'
pbar.close()
if msgs:
LOGGER.info('\n'.join(msgs))
if nf == 0:
LOGGER.warning(f'{prefix}WARNING ⚠️ No labels found in {path}. {HELP_URL}')
x['hash'] = get_hash(self.label_files + self.im_files)
x['results'] = nf, nm, ne, nc, len(self.im_files)
x['msgs'] = msgs # warnings
x['version'] = self.cache_version # cache version
try:
np.save(path, x) # save cache for next time
path.with_suffix('.cache.npy').rename(path) # remove .npy suffix
LOGGER.info(f'{prefix}New cache created: {path}')
except Exception as e:
LOGGER.warning(f'{prefix}WARNING ⚠️ Cache directory {path.parent} is not writeable: {e}') # not writeable
return x
def __len__(self):
return len(self.im_files)
# def __iter__(self):
# self.count = -1
# print('ran dataset iter')
# #self.shuffled_vector = np.random.permutation(self.nF) if self.augment else np.arange(self.nF)
# return self
def __getitem__(self, index):
index = self.indices[index] # linear, shuffled, or image_weights
hyp = self.hyp
mosaic = self.mosaic and random.random() < hyp['mosaic']
if mosaic:
# Load mosaic
img, labels = self.load_mosaic(index)
shapes = None
# MixUp augmentation
if random.random() < hyp['mixup']:
img, labels = mixup(img, labels, *self.load_mosaic(random.randint(0, self.n - 1)))
else:
# Load image
img, (h0, w0), (h, w) = self.load_image(index)
# Letterbox
shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
labels = self.labels[index].copy()
if labels.size: # normalized xywh to pixel xyxy format
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
if self.augment:
img, labels = random_perspective(img,
labels,
degrees=hyp['degrees'],
translate=hyp['translate'],
scale=hyp['scale'],
shear=hyp['shear'],
perspective=hyp['perspective'])
nl = len(labels) # number of labels
if nl:
labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1E-3)
if self.augment:
# Albumentations
img, labels = self.albumentations(img, labels)
nl = len(labels) # update after albumentations
# HSV color-space
augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
# Flip up-down
if random.random() < hyp['flipud']:
img = np.flipud(img)
if nl:
labels[:, 2] = 1 - labels[:, 2]
# Flip left-right
if random.random() < hyp['fliplr']:
img = np.fliplr(img)
if nl:
labels[:, 1] = 1 - labels[:, 1]
# Cutouts
# labels = cutout(img, labels, p=0.5)
# nl = len(labels) # update after cutout
labels_out = torch.zeros((nl, 6))
if nl:
labels_out[:, 1:] = torch.from_numpy(labels)
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
return torch.from_numpy(img), labels_out, self.im_files[index], shapes
def load_image(self, i):
# Loads 1 image from dataset index 'i', returns (im, original hw, resized hw)
im, f, fn = self.ims[i], self.im_files[i], self.npy_files[i],
if im is None: # not cached in RAM
if fn.exists(): # load npy
im = np.load(fn)
else: # read image
im = cv2.imread(f) # BGR
assert im is not None, f'Image Not Found {f}'
h0, w0 = im.shape[:2] # orig hw
r = self.img_size / max(h0, w0) # ratio
if r != 1: # if sizes are not equal
interp = cv2.INTER_LINEAR if (self.augment or r > 1) else cv2.INTER_AREA
im = cv2.resize(im, (math.ceil(w0 * r), math.ceil(h0 * r)), interpolation=interp)
return im, (h0, w0), im.shape[:2] # im, hw_original, hw_resized
return self.ims[i], self.im_hw0[i], self.im_hw[i] # im, hw_original, hw_resized
def cache_images_to_disk(self, i):
# Saves an image as an *.npy file for faster loading
f = self.npy_files[i]
if not f.exists():
np.save(f.as_posix(), cv2.imread(self.im_files[i]))
def load_mosaic(self, index):
# YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
labels4, segments4 = [], []
s = self.img_size
yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y
indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
random.shuffle(indices)
for i, index in enumerate(indices):
# Load image
img, _, (h, w) = self.load_image(index)
# place img in img4
if i == 0: # top left
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
padw = x1a - x1b
padh = y1a - y1b
# Labels
labels, segments = self.labels[index].copy(), self.segments[index].copy()
if labels.size:
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
labels4.append(labels)
segments4.extend(segments)
# Concat/clip labels
labels4 = np.concatenate(labels4, 0)
for x in (labels4[:, 1:], *segments4):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# img4, labels4 = replicate(img4, labels4) # replicate
# Augment
img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
img4, labels4 = random_perspective(img4,
labels4,
segments4,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
return img4, labels4
def load_mosaic9(self, index):
# YOLOv5 9-mosaic loader. Loads 1 image + 8 random images into a 9-image mosaic
labels9, segments9 = [], []
s = self.img_size
indices = [index] + random.choices(self.indices, k=8) # 8 additional image indices
random.shuffle(indices)
hp, wp = -1, -1 # height, width previous
for i, index in enumerate(indices):
# Load image
img, _, (h, w) = self.load_image(index)
# place img in img9
if i == 0: # center
img9 = np.full((s * 3, s * 3, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
h0, w0 = h, w
c = s, s, s + w, s + h # xmin, ymin, xmax, ymax (base) coordinates
elif i == 1: # top
c = s, s - h, s + w, s
elif i == 2: # top right
c = s + wp, s - h, s + wp + w, s
elif i == 3: # right
c = s + w0, s, s + w0 + w, s + h
elif i == 4: # bottom right
c = s + w0, s + hp, s + w0 + w, s + hp + h
elif i == 5: # bottom
c = s + w0 - w, s + h0, s + w0, s + h0 + h
elif i == 6: # bottom left
c = s + w0 - wp - w, s + h0, s + w0 - wp, s + h0 + h
elif i == 7: # left
c = s - w, s + h0 - h, s, s + h0
elif i == 8: # top left
c = s - w, s + h0 - hp - h, s, s + h0 - hp
padx, pady = c[:2]
x1, y1, x2, y2 = (max(x, 0) for x in c) # allocate coords
# Labels
labels, segments = self.labels[index].copy(), self.segments[index].copy()
if labels.size:
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padx, pady) # normalized xywh to pixel xyxy format
segments = [xyn2xy(x, w, h, padx, pady) for x in segments]
labels9.append(labels)
segments9.extend(segments)
# Image
img9[y1:y2, x1:x2] = img[y1 - pady:, x1 - padx:] # img9[ymin:ymax, xmin:xmax]
hp, wp = h, w # height, width previous
# Offset
yc, xc = (int(random.uniform(0, s)) for _ in self.mosaic_border) # mosaic center x, y
img9 = img9[yc:yc + 2 * s, xc:xc + 2 * s]
# Concat/clip labels
labels9 = np.concatenate(labels9, 0)
labels9[:, [1, 3]] -= xc
labels9[:, [2, 4]] -= yc
c = np.array([xc, yc]) # centers
segments9 = [x - c for x in segments9]
for x in (labels9[:, 1:], *segments9):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# img9, labels9 = replicate(img9, labels9) # replicate
# Augment
img9, labels9, segments9 = copy_paste(img9, labels9, segments9, p=self.hyp['copy_paste'])
img9, labels9 = random_perspective(img9,
labels9,
segments9,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
return img9, labels9
@staticmethod
def collate_fn(batch):
im, label, path, shapes = zip(*batch) # transposed
for i, lb in enumerate(label):
lb[:, 0] = i # add target image index for build_targets()
return torch.stack(im, 0), torch.cat(label, 0), path, shapes
@staticmethod
def collate_fn4(batch):
im, label, path, shapes = zip(*batch) # transposed
n = len(shapes) // 4
im4, label4, path4, shapes4 = [], [], path[:n], shapes[:n]
ho = torch.tensor([[0.0, 0, 0, 1, 0, 0]])
wo = torch.tensor([[0.0, 0, 1, 0, 0, 0]])
s = torch.tensor([[1, 1, 0.5, 0.5, 0.5, 0.5]]) # scale
for i in range(n): # zidane torch.zeros(16,3,720,1280) # BCHW
i *= 4
if random.random() < 0.5:
im1 = F.interpolate(im[i].unsqueeze(0).float(), scale_factor=2.0, mode='bilinear',
align_corners=False)[0].type(im[i].type())
lb = label[i]
else:
im1 = torch.cat((torch.cat((im[i], im[i + 1]), 1), torch.cat((im[i + 2], im[i + 3]), 1)), 2)
lb = torch.cat((label[i], label[i + 1] + ho, label[i + 2] + wo, label[i + 3] + ho + wo), 0) * s
im4.append(im1)
label4.append(lb)
for i, lb in enumerate(label4):
lb[:, 0] = i # add target image index for build_targets()
return torch.stack(im4, 0), torch.cat(label4, 0), path4, shapes4
== step 2 模型 ==
class BaseModel(nn.Module):
# YOLOv5 base model
def forward(self, x, profile=False, visualize=False):
return self._forward_once(x, profile, visualize) # single-scale inference, train
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
def _profile_one_layer(self, m, x, dt):
c = m == self.model[-1] # is final layer, copy input as inplace fix
o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPs
t = time_sync()
for _ in range(10):
m(x.copy() if c else x)
dt.append((time_sync() - t) * 100)
if m == self.model[0]:
LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} module")
LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')
if c:
LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
LOGGER.info('Fusing layers... ')
for m in self.model.modules():
if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.forward_fuse # update forward
self.info()
return self
def info(self, verbose=False, img_size=640): # print model information
model_info(self, verbose, img_size)
def _apply(self, fn):
# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
self = super()._apply(fn)
m = self.model[-1] # Detect()
if isinstance(m, (Detect, Segment)):
m.stride = fn(m.stride)
m.grid = list(map(fn, m.grid))
if isinstance(m.anchor_grid, list):
m.anchor_grid = list(map(fn, m.anchor_grid))
return self
检测模型
class DetectionModel(BaseModel):
# YOLOv5 detection model
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
super().__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg, encoding='ascii', errors='ignore') as f:
self.yaml = yaml.safe_load(f) # model dict
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc != self.yaml['nc']:
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value
if anchors:
LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
self.yaml['anchors'] = round(anchors) # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
self.inplace = self.yaml.get('inplace', True)
# Build strides, anchors
m = self.model[-1] # Detect()
if isinstance(m, (Detect, Segment)):
s = 256 # 2x min stride
m.inplace = self.inplace
forward = lambda x: self.forward(x)[0] if isinstance(m, Segment) else self.forward(x)
m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(1, ch, s, s))]) # forward
check_anchor_order(m)
m.anchors /= m.stride.view(-1, 1, 1)
self.stride = m.stride
self._initialize_biases() # only run once
# Init weights, biases
initialize_weights(self)
self.info()
LOGGER.info('')
def forward(self, x, augment=False, profile=False, visualize=False):
if augment:
return self._forward_augment(x) # augmented inference, None
return self._forward_once(x, profile, visualize) # single-scale inference, train
def _forward_augment(self, x):
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
yi = self._forward_once(xi)[0] # forward
# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi = self._descale_pred(yi, fi, si, img_size)
y.append(yi)
y = self._clip_augmented(y) # clip augmented tails
return torch.cat(y, 1), None # augmented inference, train
def _descale_pred(self, p, flips, scale, img_size):
# de-scale predictions following augmented inference (inverse operation)
if self.inplace:
p[..., :4] /= scale # de-scale
if flips == 2:
p[..., 1] = img_size[0] - p[..., 1] # de-flip ud
elif flips == 3:
p[..., 0] = img_size[1] - p[..., 0] # de-flip lr
else:
x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scale
if flips == 2:
y = img_size[0] - y # de-flip ud
elif flips == 3:
x = img_size[1] - x # de-flip lr
p = torch.cat((x, y, wh, p[..., 4:]), -1)
return p
def _clip_augmented(self, y):
# Clip YOLOv5 augmented inference tails
nl = self.model[-1].nl # number of detection layers (P3-P5)
g = sum(4 ** x for x in range(nl)) # grid points
e = 1 # exclude layer count
i = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indices
y[0] = y[0][:, :-i] # large
i = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indices
y[-1] = y[-1][:, i:] # small
return y
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# https://arxiv.org/abs/1708.02002 section 3.3
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b.data[:, 5:5 + m.nc] += math.log(0.6 / (m.nc - 0.99999)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
分割模型
class SegmentationModel(DetectionModel):
# YOLOv5 segmentation model
def __init__(self, cfg='yolov5s-seg.yaml', ch=3, nc=None, anchors=None):
super().__init__(cfg, ch, nc, anchors)
分类模型
class ClassificationModel(BaseModel):
# YOLOv5 classification model
def __init__(self, cfg=None, model=None, nc=1000, cutoff=10): # yaml, model, number of classes, cutoff index
super().__init__()
self._from_detection_model(model, nc, cutoff) if model is not None else self._from_yaml(cfg)
def _from_detection_model(self, model, nc=1000, cutoff=10):
# Create a YOLOv5 classification model from a YOLOv5 detection model
if isinstance(model, DetectMultiBackend):
model = model.model # unwrap DetectMultiBackend
model.model = model.model[:cutoff] # backbone
m = model.model[-1] # last layer
ch = m.conv.in_channels if hasattr(m, 'conv') else m.cv1.conv.in_channels # ch into module
c = Classify(ch, nc) # Classify()
c.i, c.f, c.type = m.i, m.f, 'models.common.Classify' # index, from, type
model.model[-1] = c # replace
self.model = model.model
self.stride = model.stride
self.save = []
self.nc = nc
def _from_yaml(self, cfg):
# Create a YOLOv5 classification model from a *.yaml file
self.model = None
== step 3 损失函数 ==
class ComputeLoss:
sort_obj_iou = False
# Compute losses
def __init__(self, model, autobalance=False):
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
m = de_parallel(model).model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
self.na = m.na # number of anchors
self.nc = m.nc # number of classes
self.nl = m.nl # number of layers
self.anchors = m.anchors
self.device = device
def __call__(self, p, targets): # predictions, targets
lcls = torch.zeros(1, device=self.device) # class loss
lbox = torch.zeros(1, device=self.device) # box loss
lobj = torch.zeros(1, device=self.device) # object loss
tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
# Losses
for i, pi in enumerate(p): # layer index, layer predictions
b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
n = b.shape[0] # number of targets
if n:
# pxy, pwh, _, pcls = pi[b, a, gj, gi].tensor_split((2, 4, 5), dim=1) # faster, requires torch 1.8.0
pxy, pwh, _, pcls = pi[b, a, gj, gi].split((2, 2, 1, self.nc), 1) # target-subset of predictions
# Regression
pxy = pxy.sigmoid() * 2 - 0.5
pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
pbox = torch.cat((pxy, pwh), 1) # predicted box
iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
lbox += (1.0 - iou).mean() # iou loss
# Objectness
iou = iou.detach().clamp(0).type(tobj.dtype)
if self.sort_obj_iou:
j = iou.argsort()
b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
if self.gr < 1:
iou = (1.0 - self.gr) + self.gr * iou
tobj[b, a, gj, gi] = iou # iou ratio
# Classification
if self.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(pcls, self.cn, device=self.device) # targets
t[range(n), tcls[i]] = self.cp
lcls += self.BCEcls(pcls, t) # BCE
# Append targets to text file
# with open('targets.txt', 'a') as file:
# [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
obji = self.BCEobj(pi[..., 4], tobj)
lobj += obji * self.balance[i] # obj loss
if self.autobalance:
self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
if self.autobalance:
self.balance = [x / self.balance[self.ssi] for x in self.balance]
lbox *= self.hyp['box']
lobj *= self.hyp['obj']
lcls *= self.hyp['cls']
bs = tobj.shape[0] # batch size
return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
def build_targets(self, p, targets):
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
na, nt = self.na, targets.shape[0] # number of anchors, targets
tcls, tbox, indices, anch = [], [], [], []
gain = torch.ones(7, device=self.device) # normalized to gridspace gain
ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices
g = 0.5 # bias
off = torch.tensor(
[
[0, 0],
[1, 0],
[0, 1],
[-1, 0],
[0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
],
device=self.device).float() * g # offsets
for i in range(self.nl):
anchors, shape = self.anchors[i], p[i].shape
gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
# Match targets to anchors
t = targets * gain # shape(3,n,7)
if nt:
# Matches
r = t[..., 4:6] / anchors[:, None] # wh ratio
j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter
# Offsets
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1 < g) & (gxy > 1)).T
l, m = ((gxi % 1 < g) & (gxi > 1)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
# Define
bc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
a, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class
gij = (gxy - offsets).long()
gi, gj = gij.T # grid indices
# Append
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
anch.append(anchors[a]) # anchors
tcls.append(c) # class
return tcls, tbox, indices, anch
== step 4 优化器 ==
== step 5 评测函数==
== step 6 训练 ==
== step 7 训练可视化 ==
== inference ==
0.数据增强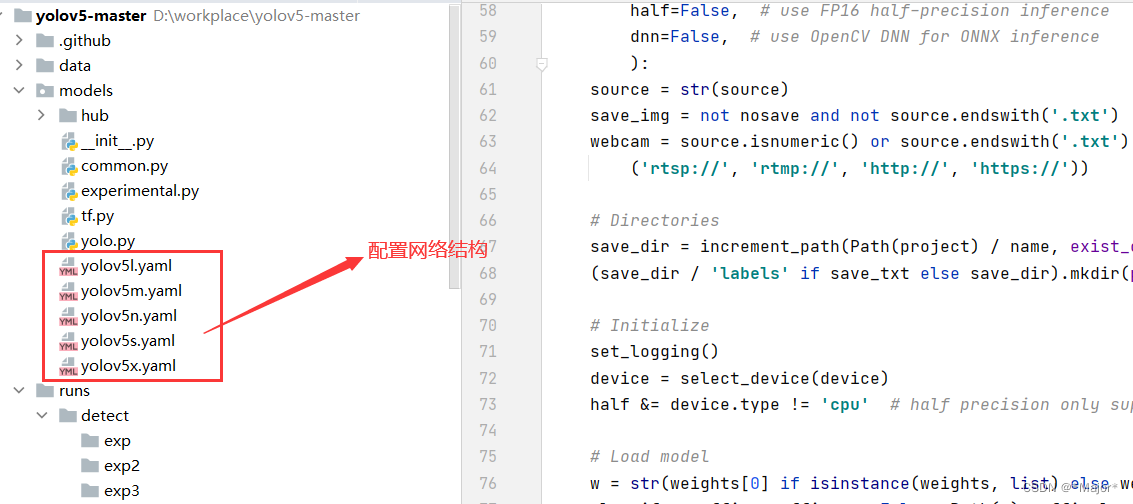

《YOLOv5: The friendliest Al architecture you’ll ever use》
—YOLOv5
作者:Glenn Jocher
单位:
发表会议及时间:2020
Submission history
2021.10.12:发布v6.0版本
- Abstract
核心模块
Conv
C3
SPPF
提升了精度,增加了由浅入深的特征提取过程

一 基于深层神经网络的目标检测
基于深层神经网络的目标检测
双阶段(two-stage):
第一段网络用于候选区域提取;
第二段网络对提取的候选区域进行分类和精确坐标回归,例如RCNN系列。
单阶段(one-stage):
放弃了候选区域提取,只用一段网络来完成了分类和回归两个任务,例如YOLO、SSD等。
Anchor Free:
取消anchor生成机制,加快了速度,代表算法:CenterNet、 CornerNet、 Fcos等
模型由小到大顺序
- 最小的:yolo5n(Nano):适用于移动端或者CPU的部署环境
- yolo5s(small)
- yolo5m(middle)
- yolo5l(large)
- 最大的:yolo5x
[-1, 1, Conv, [256, 3, 2]]
-1:表示输入通道数,由上一层的输出通道数决定(传入对应于common.py中的类模块中)
1: 重复构造1次
Conv:网络模块(名字对应于common.py中的类模块名)
[256, 3, 2]:网络模块参数(传入对应于common.py中的类模块中)
yolo5n
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8 10,13:宽、高 用于检测小目标
- [30,61, 62,45, 59,119] # P4/16 用于检测中目标
- [116,90, 156,198, 373,326] # P5/32 用于检测大目标
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 64表示64通道数,改层的输出通道数
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
yolo5s
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
yolo5m
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4 -1:上一层,6表示backbone的第6层
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
yolo5L
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
yolo5x
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
二 YoloV5网络结构
FOCUS模块
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))

1.激活函数
"""
Activation functions
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
class SiLU(nn.Module):
# SiLU activation https://arxiv.org/pdf/1606.08415.pdf
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
class Hardswish(nn.Module):
# Hard-SiLU activation
@staticmethod
def forward(x):
# return x * F.hardsigmoid(x) # for TorchScript and CoreML
return x * F.hardtanh(x + 3, 0.0, 6.0) / 6.0 # for TorchScript, CoreML and ONNX
class Mish(nn.Module):
# Mish activation https://github.com/digantamisra98/Mish
@staticmethod
def forward(x):
return x * F.softplus(x).tanh()
class MemoryEfficientMish(nn.Module):
# Mish activation memory-efficient
class F(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
return x.mul(torch.tanh(F.softplus(x))) # x * tanh(ln(1 + exp(x)))
@staticmethod
def backward(ctx, grad_output):
x = ctx.saved_tensors[0]
sx = torch.sigmoid(x)
fx = F.softplus(x).tanh()
return grad_output * (fx + x * sx * (1 - fx * fx))
def forward(self, x):
return self.F.apply(x)
class FReLU(nn.Module):
# FReLU activation https://arxiv.org/abs/2007.11824
def __init__(self, c1, k=3): # ch_in, kernel
super().__init__()
self.conv = nn.Conv2d(c1, c1, k, 1, 1, groups=c1, bias=False)
self.bn = nn.BatchNorm2d(c1)
def forward(self, x):
return torch.max(x, self.bn(self.conv(x)))
class AconC(nn.Module):
r""" ACON activation (activate or not)
AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>.
"""
def __init__(self, c1):
super().__init__()
self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.beta = nn.Parameter(torch.ones(1, c1, 1, 1))
def forward(self, x):
dpx = (self.p1 - self.p2) * x
return dpx * torch.sigmoid(self.beta * dpx) + self.p2 * x
class MetaAconC(nn.Module):
r""" ACON activation (activate or not)
MetaAconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is generated by a small network
according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>.
"""
def __init__(self, c1, k=1, s=1, r=16): # ch_in, kernel, stride, r
super().__init__()
c2 = max(r, c1 // r)
self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.fc1 = nn.Conv2d(c1, c2, k, s, bias=True)
self.fc2 = nn.Conv2d(c2, c1, k, s, bias=True)
# self.bn1 = nn.BatchNorm2d(c2)
# self.bn2 = nn.BatchNorm2d(c1)
def forward(self, x):
y = x.mean(dim=2, keepdims=True).mean(dim=3, keepdims=True)
# batch-size 1 bug/instabilities https://github.com/ultralytics/yolov5/issues/2891
# beta = torch.sigmoid(self.bn2(self.fc2(self.bn1(self.fc1(y))))) # bug/unstable
beta = torch.sigmoid(self.fc2(self.fc1(y))) # bug patch BN layers removed
dpx = (self.p1 - self.p2) * x
return dpx * torch.sigmoid(beta * dpx) + self.p2 * x
1.1 Swish激活函数(在0处可导)
1.2 SiLU激活函数
1.3
2.网络结构
3.损失函数
三 代码实现
class Model(nn.Module):
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
super().__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg, errors='ignore') as f:
self.yaml = yaml.safe_load(f) # model dict
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc != self.yaml['nc']:
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value
if anchors:
LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
self.yaml['anchors'] = round(anchors) # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
self.inplace = self.yaml.get('inplace', True)
# Build strides, anchors
m = self.model[-1] # Detect()
if isinstance(m, Detect):
s = 256 # 2x min stride
m.inplace = self.inplace
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases() # only run once
# Init weights, biases
initialize_weights(self)
self.info()
LOGGER.info('')
def forward(self, x, augment=False, profile=False, visualize=False):
if augment:
return self._forward_augment(x) # augmented inference, None
return self._forward_once(x, profile, visualize) # single-scale inference, train
def _forward_augment(self, x):
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
yi = self._forward_once(xi)[0] # forward
# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi = self._descale_pred(yi, fi, si, img_size)
y.append(yi)
y = self._clip_augmented(y) # clip augmented tails
return torch.cat(y, 1), None # augmented inference, train
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
def _descale_pred(self, p, flips, scale, img_size):
# de-scale predictions following augmented inference (inverse operation)
if self.inplace:
p[..., :4] /= scale # de-scale
if flips == 2:
p[..., 1] = img_size[0] - p[..., 1] # de-flip ud
elif flips == 3:
p[..., 0] = img_size[1] - p[..., 0] # de-flip lr
else:
x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scale
if flips == 2:
y = img_size[0] - y # de-flip ud
elif flips == 3:
x = img_size[1] - x # de-flip lr
p = torch.cat((x, y, wh, p[..., 4:]), -1)
return p
def _clip_augmented(self, y):
# Clip YOLOv5 augmented inference tails
nl = self.model[-1].nl # number of detection layers (P3-P5)
g = sum(4 ** x for x in range(nl)) # grid points
e = 1 # exclude layer count
i = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indices
y[0] = y[0][:, :-i] # large
i = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indices
y[-1] = y[-1][:, i:] # small
return y
def _profile_one_layer(self, m, x, dt):
c = isinstance(m, Detect) # is final layer, copy input as inplace fix
o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPs
t = time_sync()
for _ in range(10):
m(x.copy() if c else x)
dt.append((time_sync() - t) * 100)
if m == self.model[0]:
LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} {'module'}")
LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')
if c:
LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# https://arxiv.org/abs/1708.02002 section 3.3
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b.data[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
def _print_biases(self):
m = self.model[-1] # Detect() module
for mi in m.m: # from
b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
LOGGER.info(
('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
# def _print_weights(self):
# for m in self.model.modules():
# if type(m) is Bottleneck:
# LOGGER.info('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
LOGGER.info('Fusing layers... ')
for m in self.model.modules():
if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.forward_fuse # update forward
self.info()
return self
def autoshape(self): # add AutoShape module
LOGGER.info('Adding AutoShape... ')
m = AutoShape(self) # wrap model
copy_attr(m, self, include=('yaml', 'nc', 'hyp', 'names', 'stride'), exclude=()) # copy attributes
return m
def info(self, verbose=False, img_size=640): # print model information
model_info(self, verbose, img_size)
def _apply(self, fn):
# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
self = super()._apply(fn)
m = self.model[-1] # Detect()
if isinstance(m, Detect):
m.stride = fn(m.stride)
m.grid = list(map(fn, m.grid))
if isinstance(m.anchor_grid, list):
m.anchor_grid = list(map(fn, m.anchor_grid))
return self
解析构造网络
def parse_model(d, ch): # model_dict, input_channels(3)
LOGGER.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except NameError:
pass
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost]:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[x] for x in f])
elif m is Detect:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum([x.numel() for x in m_.parameters()]) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n_, np, t, args)) # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
四 问题思索
五 实验参数设置
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
Train a YOLOv5 model on a custom dataset
Usage:
$ python path/to/train.py --data coco128.yaml --weights yolov5s.pt --img 640
"""
import argparse
import logging
import math
import os
import random
import sys
import time
from copy import deepcopy
from pathlib import Path
import numpy as np
import torch
import torch.distributed as dist
import torch.nn as nn
import yaml
from torch.cuda import amp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.optim import Adam, SGD, lr_scheduler
from tqdm import tqdm
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
import val # for end-of-epoch mAP
from models.experimental import attempt_load
from models.yolo import Model
from utils.autoanchor import check_anchors
from utils.datasets import create_dataloader
from utils.general import labels_to_class_weights, increment_path, labels_to_image_weights, init_seeds, \
strip_optimizer, get_latest_run, check_dataset, check_git_status, check_img_size, check_requirements, \
check_file, check_yaml, check_suffix, print_args, print_mutation, set_logging, one_cycle, colorstr, methods
from utils.downloads import attempt_download
from utils.loss import ComputeLoss
from utils.plots import plot_labels, plot_evolve
from utils.torch_utils import EarlyStopping, ModelEMA, de_parallel, intersect_dicts, select_device, \
torch_distributed_zero_first
from utils.loggers.wandb.wandb_utils import check_wandb_resume
from utils.metrics import fitness
from utils.loggers import Loggers
from utils.callbacks import Callbacks
LOGGER = logging.getLogger(__name__)
LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
RANK = int(os.getenv('RANK', -1))
WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
def train(hyp, # path/to/hyp.yaml or hyp dictionary
opt,
device,
callbacks
):
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze, = \
Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
# Directories
w = save_dir / 'weights' # weights dir
(w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
last, best = w / 'last.pt', w / 'best.pt'
# Hyperparameters
if isinstance(hyp, str):
with open(hyp, errors='ignore') as f:
hyp = yaml.safe_load(f) # load hyps dict
LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
# Save run settings
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.safe_dump(hyp, f, sort_keys=False)
with open(save_dir / 'opt.yaml', 'w') as f:
yaml.safe_dump(vars(opt), f, sort_keys=False)
data_dict = None
# Loggers
if RANK in [-1, 0]:
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
if loggers.wandb:
data_dict = loggers.wandb.data_dict
if resume:
weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp
# Register actions
for k in methods(loggers):
callbacks.register_action(k, callback=getattr(loggers, k))
# Config
plots = not evolve # create plots
cuda = device.type != 'cpu'
init_seeds(1 + RANK)
with torch_distributed_zero_first(LOCAL_RANK):
data_dict = data_dict or check_dataset(data) # check if None
train_path, val_path = data_dict['train'], data_dict['val']
nc = 1 if single_cls else int(data_dict['nc']) # number of classes
names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
is_coco = data.endswith('coco.yaml') and nc == 80 # COCO dataset
# Model
check_suffix(weights, '.pt') # check weights
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(csd, strict=False) # load
LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
else:
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
# Freeze
freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print(f'freezing {k}')
v.requires_grad = False
# Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")
g0, g1, g2 = [], [], [] # optimizer parameter groups
for v in model.modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
g2.append(v.bias)
if isinstance(v, nn.BatchNorm2d): # weight (no decay)
g0.append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g1.append(v.weight)
if opt.adam:
optimizer = Adam(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = SGD(g0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
optimizer.add_param_group({'params': g1, 'weight_decay': hyp['weight_decay']}) # add g1 with weight_decay
optimizer.add_param_group({'params': g2}) # add g2 (biases)
LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups "
f"{len(g0)} weight, {len(g1)} weight (no decay), {len(g2)} bias")
del g0, g1, g2
# Scheduler
if opt.linear_lr:
lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
else:
lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
# EMA
ema = ModelEMA(model) if RANK in [-1, 0] else None
# Resume
start_epoch, best_fitness = 0, 0.0
if pretrained:
# Optimizer
if ckpt['optimizer'] is not None:
optimizer.load_state_dict(ckpt['optimizer'])
best_fitness = ckpt['best_fitness']
# EMA
if ema and ckpt.get('ema'):
ema.ema.load_state_dict(ckpt['ema'].float().state_dict())
ema.updates = ckpt['updates']
# Epochs
start_epoch = ckpt['epoch'] + 1
if resume:
assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.'
if epochs < start_epoch:
LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
epochs += ckpt['epoch'] # finetune additional epochs
del ckpt, csd
# Image sizes
gs = max(int(model.stride.max()), 32) # grid size (max stride)
nl = model.model[-1].nl # number of detection layers (used for scaling hyp['obj'])
imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
# DP mode
if cuda and RANK == -1 and torch.cuda.device_count() > 1:
logging.warning('DP not recommended, instead use torch.distributed.run for best DDP Multi-GPU results.\n'
'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
model = torch.nn.DataParallel(model)
# SyncBatchNorm
if opt.sync_bn and cuda and RANK != -1:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
LOGGER.info('Using SyncBatchNorm()')
# Trainloader
train_loader, dataset = create_dataloader(train_path, imgsz, batch_size // WORLD_SIZE, gs, single_cls,
hyp=hyp, augment=True, cache=opt.cache, rect=opt.rect, rank=LOCAL_RANK,
workers=workers, image_weights=opt.image_weights, quad=opt.quad,
prefix=colorstr('train: '))
mlc = int(np.concatenate(dataset.labels, 0)[:, 0].max()) # max label class
nb = len(train_loader) # number of batches
assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
# Process 0
if RANK in [-1, 0]:
val_loader = create_dataloader(val_path, imgsz, batch_size // WORLD_SIZE * 2, gs, single_cls,
hyp=hyp, cache=None if noval else opt.cache, rect=True, rank=-1,
workers=workers, pad=0.5,
prefix=colorstr('val: '))[0]
if not resume:
labels = np.concatenate(dataset.labels, 0)
# c = torch.tensor(labels[:, 0]) # classes
# cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
# model._initialize_biases(cf.to(device))
if plots:
plot_labels(labels, names, save_dir)
# Anchors
if not opt.noautoanchor:
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
model.half().float() # pre-reduce anchor precision
callbacks.run('on_pretrain_routine_end')
# DDP mode
if cuda and RANK != -1:
model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
# Model parameters
hyp['box'] *= 3. / nl # scale to layers
hyp['cls'] *= nc / 80. * 3. / nl # scale to classes and layers
hyp['obj'] *= (imgsz / 640) ** 2 * 3. / nl # scale to image size and layers
hyp['label_smoothing'] = opt.label_smoothing
model.nc = nc # attach number of classes to model
model.hyp = hyp # attach hyperparameters to model
model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
model.names = names
# Start training
t0 = time.time()
nw = max(round(hyp['warmup_epochs'] * nb), 1000) # number of warmup iterations, max(3 epochs, 1k iterations)
# nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
last_opt_step = -1
maps = np.zeros(nc) # mAP per class
results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
scheduler.last_epoch = start_epoch - 1 # do not move
scaler = amp.GradScaler(enabled=cuda)
stopper = EarlyStopping(patience=opt.patience)
compute_loss = ComputeLoss(model) # init loss class
LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
f'Using {train_loader.num_workers} dataloader workers\n'
f"Logging results to {colorstr('bold', save_dir)}\n"
f'Starting training for {epochs} epochs...')
for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
model.train()
# Update image weights (optional, single-GPU only)
if opt.image_weights:
cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
# Update mosaic border (optional)
# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
# dataset.mosaic_border = [b - imgsz, -b] # height, width borders
mloss = torch.zeros(3, device=device) # mean losses
if RANK != -1:
train_loader.sampler.set_epoch(epoch)
pbar = enumerate(train_loader)
LOGGER.info(('\n' + '%10s' * 7) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'labels', 'img_size'))
if RANK in [-1, 0]:
pbar = tqdm(pbar, total=nb) # progress bar
optimizer.zero_grad()
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device, non_blocking=True).float() / 255.0 # uint8 to float32, 0-255 to 0.0-1.0
# Warmup
if ni <= nw:
xi = [0, nw] # x interp
# compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
# Multi-scale
if opt.multi_scale:
sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
sf = sz / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
# Forward
with amp.autocast(enabled=cuda):
pred = model(imgs) # forward
loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
if RANK != -1:
loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
if opt.quad:
loss *= 4.
# Backward
scaler.scale(loss).backward()
# Optimize
if ni - last_opt_step >= accumulate:
scaler.step(optimizer) # optimizer.step
scaler.update()
optimizer.zero_grad()
if ema:
ema.update(model)
last_opt_step = ni
# Log
if RANK in [-1, 0]:
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
pbar.set_description(('%10s' * 2 + '%10.4g' * 5) % (
f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
callbacks.run('on_train_batch_end', ni, model, imgs, targets, paths, plots, opt.sync_bn)
# end batch ------------------------------------------------------------------------------------------------
# Scheduler
lr = [x['lr'] for x in optimizer.param_groups] # for loggers
scheduler.step()
if RANK in [-1, 0]:
# mAP
callbacks.run('on_train_epoch_end', epoch=epoch)
ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
if not noval or final_epoch: # Calculate mAP
results, maps, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=ema.ema,
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
plots=False,
callbacks=callbacks,
compute_loss=compute_loss)
# Update best mAP
fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
if fi > best_fitness:
best_fitness = fi
log_vals = list(mloss) + list(results) + lr
callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
# Save model
if (not nosave) or (final_epoch and not evolve): # if save
ckpt = {'epoch': epoch,
'best_fitness': best_fitness,
'model': deepcopy(de_parallel(model)).half(),
'ema': deepcopy(ema.ema).half(),
'updates': ema.updates,
'optimizer': optimizer.state_dict(),
'wandb_id': loggers.wandb.wandb_run.id if loggers.wandb else None}
# Save last, best and delete
torch.save(ckpt, last)
if best_fitness == fi:
torch.save(ckpt, best)
if (epoch > 0) and (opt.save_period > 0) and (epoch % opt.save_period == 0):
torch.save(ckpt, w / f'epoch{epoch}.pt')
del ckpt
callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
# Stop Single-GPU
if RANK == -1 and stopper(epoch=epoch, fitness=fi):
break
# Stop DDP TODO: known issues shttps://github.com/ultralytics/yolov5/pull/4576
# stop = stopper(epoch=epoch, fitness=fi)
# if RANK == 0:
# dist.broadcast_object_list([stop], 0) # broadcast 'stop' to all ranks
# Stop DPP
# with torch_distributed_zero_first(RANK):
# if stop:
# break # must break all DDP ranks
# end epoch ----------------------------------------------------------------------------------------------------
# end training -----------------------------------------------------------------------------------------------------
if RANK in [-1, 0]:
LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
for f in last, best:
if f.exists():
strip_optimizer(f) # strip optimizers
if f is best:
LOGGER.info(f'\nValidating {f}...')
results, _, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=attempt_load(f, device).half(),
iou_thres=0.65 if is_coco else 0.60, # best pycocotools results at 0.65
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
save_json=is_coco,
verbose=True,
plots=True,
callbacks=callbacks,
compute_loss=compute_loss) # val best model with plots
callbacks.run('on_train_end', last, best, plots, epoch)
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
torch.cuda.empty_cache()
return results
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', type=int, default=0, help='Number of layers to freeze. backbone=10, all=24')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', action='store_true', help='W&B: Upload dataset as artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
def main(opt, callbacks=Callbacks()):
# Checks
set_logging(RANK)
if RANK in [-1, 0]:
print_args(FILE.stem, opt)
check_git_status()
check_requirements(exclude=['thop'])
# Resume
if opt.resume and not check_wandb_resume(opt) and not opt.evolve: # resume an interrupted run
ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent path
assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
with open(Path(ckpt).parent.parent / 'opt.yaml', errors='ignore') as f:
opt = argparse.Namespace(**yaml.safe_load(f)) # replace
opt.cfg, opt.weights, opt.resume = '', ckpt, True # reinstate
LOGGER.info(f'Resuming training from {ckpt}')
else:
opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
if opt.evolve:
opt.project = str(ROOT / 'runs/evolve')
opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
# DDP mode
device = select_device(opt.device, batch_size=opt.batch_size)
if LOCAL_RANK != -1:
assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
assert opt.batch_size % WORLD_SIZE == 0, '--batch-size must be multiple of CUDA device count'
assert not opt.image_weights, '--image-weights argument is not compatible with DDP training'
assert not opt.evolve, '--evolve argument is not compatible with DDP training'
torch.cuda.set_device(LOCAL_RANK)
device = torch.device('cuda', LOCAL_RANK)
dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo")
# Train
if not opt.evolve:
train(opt.hyp, opt, device, callbacks)
if WORLD_SIZE > 1 and RANK == 0:
LOGGER.info('Destroying process group... ')
dist.destroy_process_group()
# Evolve hyperparameters (optional)
else:
# Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
meta = {'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
'box': (1, 0.02, 0.2), # box loss gain
'cls': (1, 0.2, 4.0), # cls loss gain
'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
'iou_t': (0, 0.1, 0.7), # IoU training threshold
'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
'scale': (1, 0.0, 0.9), # image scale (+/- gain)
'shear': (1, 0.0, 10.0), # image shear (+/- deg)
'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
'mosaic': (1, 0.0, 1.0), # image mixup (probability)
'mixup': (1, 0.0, 1.0), # image mixup (probability)
'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
with open(opt.hyp, errors='ignore') as f:
hyp = yaml.safe_load(f) # load hyps dict
if 'anchors' not in hyp: # anchors commented in hyp.yaml
hyp['anchors'] = 3
opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
# ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
if opt.bucket:
os.system(f'gsutil cp gs://{opt.bucket}/evolve.csv {save_dir}') # download evolve.csv if exists
for _ in range(opt.evolve): # generations to evolve
if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
# Select parent(s)
parent = 'single' # parent selection method: 'single' or 'weighted'
x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
n = min(5, len(x)) # number of previous results to consider
x = x[np.argsort(-fitness(x))][:n] # top n mutations
w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
if parent == 'single' or len(x) == 1:
# x = x[random.randint(0, n - 1)] # random selection
x = x[random.choices(range(n), weights=w)[0]] # weighted selection
elif parent == 'weighted':
x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
# Mutate
mp, s = 0.8, 0.2 # mutation probability, sigma
npr = np.random
npr.seed(int(time.time()))
g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
ng = len(meta)
v = np.ones(ng)
while all(v == 1): # mutate until a change occurs (prevent duplicates)
v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
hyp[k] = float(x[i + 7] * v[i]) # mutate
# Constrain to limits
for k, v in meta.items():
hyp[k] = max(hyp[k], v[1]) # lower limit
hyp[k] = min(hyp[k], v[2]) # upper limit
hyp[k] = round(hyp[k], 5) # significant digits
# Train mutation
results = train(hyp.copy(), opt, device, callbacks)
# Write mutation results
print_mutation(results, hyp.copy(), save_dir, opt.bucket)
# Plot results
plot_evolve(evolve_csv)
print(f'Hyperparameter evolution finished\n'
f"Results saved to {colorstr('bold', save_dir)}\n"
f'Use best hyperparameters example: $ python train.py --hyp {evolve_yaml}')
def run(**kwargs):
# Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
opt = parse_opt(True)
for k, v in kwargs.items():
setattr(opt, k, v)
main(opt)
if __name__ == "__main__":
opt = parse_opt()
main(opt)
六 额外补充
ComputeLoss
class ComputeLoss:
# Compute losses
def __init__(self, model, autobalance=False):
self.sort_obj_iou = False
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, .02]) # P3-P7
self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 index
self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
for k in 'na', 'nc', 'nl', 'anchors':
setattr(self, k, getattr(det, k))
def __call__(self, p, targets): # predictions, targets, model
device = targets.device
lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
# Losses
for i, pi in enumerate(p): # layer index, layer predictions
b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
n = b.shape[0] # number of targets
if n:
ps = pi[b, a, gj, gi] # prediction subset corresponding to targets
# Regression
pxy = ps[:, :2].sigmoid() * 2. - 0.5
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
pbox = torch.cat((pxy, pwh), 1) # predicted box
iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)
lbox += (1.0 - iou).mean() # iou loss
# Objectness
score_iou = iou.detach().clamp(0).type(tobj.dtype)
if self.sort_obj_iou:
sort_id = torch.argsort(score_iou)
b, a, gj, gi, score_iou = b[sort_id], a[sort_id], gj[sort_id], gi[sort_id], score_iou[sort_id]
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * score_iou # iou ratio
# Classification
if self.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
t[range(n), tcls[i]] = self.cp
lcls += self.BCEcls(ps[:, 5:], t) # BCE
# Append targets to text file
# with open('targets.txt', 'a') as file:
# [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
obji = self.BCEobj(pi[..., 4], tobj)
lobj += obji * self.balance[i] # obj loss
if self.autobalance:
self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
if self.autobalance:
self.balance = [x / self.balance[self.ssi] for x in self.balance]
lbox *= self.hyp['box']
lobj *= self.hyp['obj']
lcls *= self.hyp['cls']
bs = tobj.shape[0] # batch size
return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
def build_targets(self, p, targets):
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
na, nt = self.na, targets.shape[0] # number of anchors, targets
tcls, tbox, indices, anch = [], [], [], []
gain = torch.ones(7, device=targets.device) # normalized to gridspace gain
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
g = 0.5 # bias
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g # offsets
for i in range(self.nl):
anchors = self.anchors[i]
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
# Match targets to anchors
t = targets * gain
if nt:
# Matches
r = t[:, :, 4:6] / anchors[:, None] # wh ratio
j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter
# Offsets
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
# Define
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()
gi, gj = gij.T # grid xy indices
# Append
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
anch.append(anchors[a]) # anchors
tcls.append(c) # class
return tcls, tbox, indices, anch
Detect.py
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
Run inference on images, videos, directories, streams, etc.
Usage:
$ python path/to/detect.py --source path/to/img.jpg --weights yolov5s.pt --img 640
"""
import argparse
import os
import sys
from pathlib import Path
import cv2
import numpy as np
import torch
import torch.backends.cudnn as cudnn
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.experimental import attempt_load
from utils.datasets import LoadImages, LoadStreams
from utils.general import apply_classifier, check_img_size, check_imshow, check_requirements, check_suffix, colorstr, \
increment_path, non_max_suppression, print_args, save_one_box, scale_coords, set_logging, \
strip_optimizer, xyxy2xywh
from utils.plots import Annotator, colors
from utils.torch_utils import load_classifier, select_device, time_sync
@torch.no_grad()
def run(weights=ROOT / 'yolov5s.pt', # model.pt path(s)
source=ROOT / 'data/images', # file/dir/URL/glob, 0 for webcam
imgsz=640, # inference size (pixels)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
source = str(source)
save_img = not nosave and not source.endswith('.txt') # save inference images
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://', 'https://'))
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(device)
half &= device.type != 'cpu' # half precision only supported on CUDA
# Load model
w = str(weights[0] if isinstance(weights, list) else weights)
classify, suffix, suffixes = False, Path(w).suffix.lower(), ['.pt', '.onnx', '.tflite', '.pb', '']
check_suffix(w, suffixes) # check weights have acceptable suffix
pt, onnx, tflite, pb, saved_model = (suffix == x for x in suffixes) # backend booleans
stride, names = 64, [f'class{i}' for i in range(1000)] # assign defaults
if pt:
model = torch.jit.load(w) if 'torchscript' in w else attempt_load(weights, map_location=device)
stride = int(model.stride.max()) # model stride
names = model.module.names if hasattr(model, 'module') else model.names # get class names
if half:
model.half() # to FP16
if classify: # second-stage classifier
modelc = load_classifier(name='resnet50', n=2) # initialize
modelc.load_state_dict(torch.load('resnet50.pt', map_location=device)['model']).to(device).eval()
elif onnx:
if dnn:
# check_requirements(('opencv-python>=4.5.4',))
net = cv2.dnn.readNetFromONNX(w)
else:
check_requirements(('onnx', 'onnxruntime-gpu' if torch.has_cuda else 'onnxruntime'))
import onnxruntime
session = onnxruntime.InferenceSession(w, None)
else: # TensorFlow models
check_requirements(('tensorflow>=2.4.1',))
import tensorflow as tf
if pb: # https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxt
def wrap_frozen_graph(gd, inputs, outputs):
x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=""), []) # wrapped import
return x.prune(tf.nest.map_structure(x.graph.as_graph_element, inputs),
tf.nest.map_structure(x.graph.as_graph_element, outputs))
graph_def = tf.Graph().as_graph_def()
graph_def.ParseFromString(open(w, 'rb').read())
frozen_func = wrap_frozen_graph(gd=graph_def, inputs="x:0", outputs="Identity:0")
elif saved_model:
model = tf.keras.models.load_model(w)
elif tflite:
interpreter = tf.lite.Interpreter(model_path=w) # load TFLite model
interpreter.allocate_tensors() # allocate
input_details = interpreter.get_input_details() # inputs
output_details = interpreter.get_output_details() # outputs
int8 = input_details[0]['dtype'] == np.uint8 # is TFLite quantized uint8 model
imgsz = check_img_size(imgsz, s=stride) # check image size
# Dataloader
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
if pt and device.type != 'cpu':
model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.parameters()))) # run once
dt, seen = [0.0, 0.0, 0.0], 0
for path, img, im0s, vid_cap in dataset:
t1 = time_sync()
if onnx:
img = img.astype('float32')
else:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img = img / 255.0 # 0 - 255 to 0.0 - 1.0
if len(img.shape) == 3:
img = img[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
if pt:
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(img, augment=augment, visualize=visualize)[0]
elif onnx:
if dnn:
net.setInput(img)
pred = torch.tensor(net.forward())
else:
pred = torch.tensor(session.run([session.get_outputs()[0].name], {session.get_inputs()[0].name: img}))
else: # tensorflow model (tflite, pb, saved_model)
imn = img.permute(0, 2, 3, 1).cpu().numpy() # image in numpy
if pb:
pred = frozen_func(x=tf.constant(imn)).numpy()
elif saved_model:
pred = model(imn, training=False).numpy()
elif tflite:
if int8:
scale, zero_point = input_details[0]['quantization']
imn = (imn / scale + zero_point).astype(np.uint8) # de-scale
interpreter.set_tensor(input_details[0]['index'], imn)
interpreter.invoke()
pred = interpreter.get_tensor(output_details[0]['index'])
if int8:
scale, zero_point = output_details[0]['quantization']
pred = (pred.astype(np.float32) - zero_point) * scale # re-scale
pred[..., 0] *= imgsz[1] # x
pred[..., 1] *= imgsz[0] # y
pred[..., 2] *= imgsz[1] # w
pred[..., 3] *= imgsz[0] # h
pred = torch.tensor(pred)
t3 = time_sync()
dt[1] += t3 - t2
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
# Second-stage classifier (optional)
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], f'{i}: ', im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # img.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
# Print time (inference-only)
print(f'{s}Done. ({t3 - t2:.3f}s)')
# Stream results
im0 = annotator.result()
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.mp4'
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer[i].write(im0)
# Print results
t = tuple(x / seen * 1E3 for x in dt) # speeds per image
print(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
print(f"Results saved to {colorstr('bold', save_dir)}{s}")
if update:
strip_optimizer(weights) # update model (to fix SourceChangeWarning)
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(FILE.stem, opt)
return opt
def main(opt):
check_requirements(exclude=('tensorboard', 'thop'))
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
main(opt)
一 安装环境
train.py
# pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow>=7.1.2
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
# Logging -------------------------------------
tensorboard>=2.4.1
# wandb
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=4.1 # CoreML export
# onnx>=1.9.0 # ONNX export
# onnx-simplifier>=0.3.6 # ONNX simplifier
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TFLite export
# tensorflowjs>=3.9.0 # TF.js export
# Extras --------------------------------------
# albumentations>=1.0.3
# Cython # for pycocotools https://github.com/cocodataset/cocoapi/issues/172
# pycocotools>=2.0 # COCO mAP
# roboflow
thop # FLOPs computation
二 预测
python detect.py --source 0 # webcam
file.jpg # image
file.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/NUsoVlDFqZg' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
三 训练
python train.py --data coco.yaml --cfg yolov5s.yaml --weights '' --batch-size 16

















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









