L
i
b
T
o
r
c
h
之
D
a
t
a
S
e
t
数据集处理方法
LibTorch之DataSet数据集处理方法
LibTorch之DataSet数据集处理方法
Pytorch
from torch.utils.data import Dataset
from PIL import Image
import os
def get_imgs_labels(data_dir):
dict_label = {"ants": 0, "bees": 1}
data_info = list()
for root, dirs, _ in os.walk(data_dir):
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = dict_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
class LoadDataset(Dataset):
def __init__(self, data_dir=None, transform=None):
self.imgs_labels = get_imgs_labels(data_dir)
self.transform = transform
def __getitem__(self, index):
img_path,label = self.imgs_labels[index]
img = Image.open(img_path)
img.show()
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs_labels)
if __name__ == '__main__':
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
norm_mean = [0.33424968, 0.33424437, 0.33428448]
norm_std = [0.24796878, 0.24796101, 0.24801227]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
train_dataset = LoadDataset(data_dir=r"D:\PycharmProjects\AI_Easy_Demo\MyData\split_data\train",transform=train_transform)
train_loader = DataLoader(dataset=train_dataset, batch_size=8, shuffle=True)
for idx,data_info in enumerate(train_loader):
print(idx)
inputs, labels = data_info
print(data_info)
Libtorch
#include<opencv2/opencv.hpp>
#include <torch/torch.h>
#include <torch/script.h>
#include <filesystem>
using namespace std;
namespace fs = std::filesystem;
vector<pair<string, int>> get_imgs_labels(const std::string& data_dir, map<string, int> dict_label)
{
vector<pair<string, int>> data_info;
for (map<string, int>::iterator it = dict_label.begin(); it != dict_label.end(); it++)
{
for (const auto& file_path : fs::directory_iterator(data_dir))
{
if (file_path.path().filename() == it->first) {
for (const auto& img_path : fs::directory_iterator(data_dir + "\\" + it->first))
{
data_info.push_back(pair<string, int>(img_path.path().string(), it->second));
}
}
}
}
return data_info;
}
class MyDataset :public torch::data::Dataset<MyDataset> {
private:
vector<pair<string, int>> data_info;
torch::Tensor imgs, labels;
public:
MyDataset(const std::string& data_dir,std::map<string,int> dict_label);
torch::data::Example<> get(size_t index) override;
torch::optional<size_t> size() const override {
return data_info.size();
};
};
MyDataset::MyDataset(const std::string& data_dir, std::map<string, int> dict_label) {
data_info = get_imgs_labels(data_dir, dict_label);
}
torch::data::Example<> MyDataset::get(size_t index)
{
auto img_path = data_info[index].first;
auto label = data_info[index].second;
auto image = cv::imread(img_path);
cv::resize(image, image, cv::Size(224, 224));
auto input_tensor = torch::from_blob(image.data, { image.rows, image.cols, 3 }, torch::kByte).permute({ 2, 0, 1 }).unsqueeze(0).to(torch::kFloat32) / 225.0;
torch::Tensor label_tensor = torch::tensor(label);
return {input_tensor,label_tensor };
}
int main()
{
try
{
map<string, int> dict_label;
dict_label.insert(pair<string, int>("ants", 0));
dict_label.insert(pair<string, int>("bees", 1));
auto dataset_train = MyDataset("D:\\dataset\\hymenoptera_data\\train", dict_label).map(torch::data::transforms::Stack<>());
int batchSize = 1;
auto dataLoader = torch::data::make_data_loader<torch::data::samplers::SequentialSampler>(std::move(dataset_train), batchSize);
for (auto& batch : *dataLoader) {
auto data = batch.data;
auto target = batch.target;
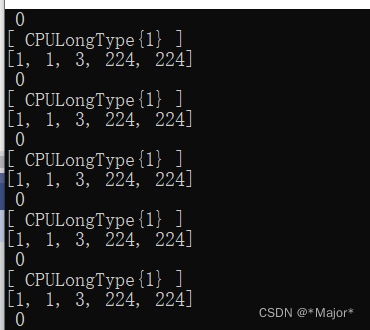
std::cout << data.sizes() << std::endl;
std::cout << target << std::endl;
int ssss;
cin >> ssss;
}
}
catch (const std::exception& e)
{
cout << e.what() << endl;
}
return 0;
}






















 819
819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









