






y o l o v 5 基础使用教程 yolov5基础使用教程 yolov5基础使用教程
官方文档:https://docs.ultralytics.com/yolov5/
代码:https://github.com/ultralytics/yolov5
YOLOv5 PyTorch HUB Inference (DetectionModels only)
torch.hub 目前只支持检测模型的推理
1.视频教程:
B站、网易云课堂、腾讯课堂
2.代码地址:
Gitee
Github
3.存储地址:
Google云
百度云:
提取码:
一 Yolov5之图像分类
1 数据集准备
1.1 首先创建存放分类数据的文件夹-my_dataset
1.2 然后在其文件夹分别创建train和test两个子文件夹
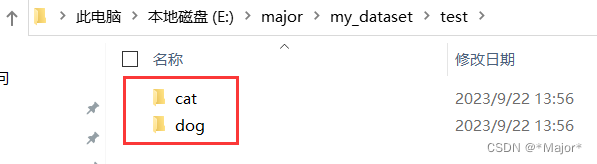
1.3 train和test文件夹下存放各个类别的缺陷图像
2 训练模型
python classify/train.py --model yolov5s-cls.pt --data E:\major\my_dataset--epochs 500 --img 224 --batch 4
3 验证模型
python classify/val.py --weights yolov5m-cls.pt --data E:\major\my_dataset --img 224
4 模型推理
python classify/predict.py --weights yolov5s-cls.pt --source data/images/bus.jpg
二 Yolov5之图像检测
1 数据集准备
path: D:\workplace\yolov5-master-latest\datasets\CatDogDet # dataset root dir
train: images/train # train images (relative to 'path')
val: images/val # val images (relative to 'path')
test: # test images (optional)
# Classes
names:
0: dog
1: cat
labelme数据集转检yolov5检测数据集
# -*- coding: utf-8 -*-
import os
import numpy as np
import json
from glob import glob
import cv2
import shutil
import yaml
from sklearn.model_selection import train_test_split
from tqdm import tqdm
# 获取当前路径
ROOT_DIR = os.getcwd()
'''
统一图像格式
'''
def change_image_format(label_path=ROOT_DIR, suffix='.jpg'):
"""
统一当前文件夹下所有图像的格式,如'.jpg'
:param suffix: 图像文件后缀
:param label_path:当前文件路径
:return:
"""
externs = ['png', 'jpg', 'JPEG', 'BMP', 'bmp']
files = list()
# 获取尾缀在ecterns中的所有图像
for extern in externs:
files.extend(glob(label_path + "\\*." + extern))
# 遍历所有图像,转换图像格式
for file in files:
name = ''.join(file.split('.')[:-1])
file_suffix = file.split('.')[-1]
if file_suffix != suffix.split('.')[-1]:
# 重命名为jpg
new_name = name + suffix
# 读取图像
image = cv2.imread(file)
# 重新存图为jpg格式
cv2.imwrite(new_name, image)
# 删除旧图像
os.remove(file)
'''
读取所有json文件,获取所有的类别
'''
def get_all_class(file_list, label_path=ROOT_DIR):
"""
从json文件中获取当前数据的所有类别
:param file_list:当前路径下的所有文件名
:param label_path:当前文件路径
:return:
"""
# 初始化类别列表
classes = list()
# 遍历所有json,读取shape中的label值内容,添加到classes
for filename in tqdm(file_list):
json_path = os.path.join(label_path, filename + '.json')
json_file = json.load(open(json_path, "r", encoding="utf-8"))
for item in json_file["shapes"]:
label_class = item['label']
if label_class not in classes:
classes.append(label_class)
print('read file done')
return classes
'''
划分训练集、验证机、测试集
'''
def split_dataset(label_path, test_size=0.3, isUseTest=False, useNumpyShuffle=False):
"""
将文件分为训练集,测试集和验证集
:param useNumpyShuffle: 使用numpy方法分割数据集
:param test_size: 分割测试集或验证集的比例
:param isUseTest: 是否使用测试集,默认为False
:param label_path:当前文件路径
:return:
"""
# 获取所有json
files = glob(label_path + "\\*.json")
files = [i.replace("\\", "/").split("/")[-1].split(".json")[0] for i in files]
if useNumpyShuffle:
file_length = len(files)
index = np.arange(file_length)
np.random.seed(32)
np.random.shuffle(index) # 随机划分
test_files = None
# 是否有测试集
if isUseTest:
trainval_files, test_files = np.array(files)[index[:int(file_length * (1 - test_size))]], np.array(files)[
index[int(file_length * (1 - test_size)):]]
else:
trainval_files = files
# 划分训练集和测试集
train_files, val_files = np.array(trainval_files)[index[:int(len(trainval_files) * (1 - test_size))]], \
np.array(trainval_files)[index[int(len(trainval_files) * (1 - test_size)):]]
else:
test_files = None
if isUseTest:
trainval_files, test_files = train_test_split(files, test_size=test_size, random_state=55)
else:
trainval_files = files
train_files, val_files = train_test_split(trainval_files, test_size=test_size, random_state=55)
return train_files, val_files, test_files, files
'''
生成yolov5的训练、验证、测试集的文件夹
'''
def create_save_file(label_path=ROOT_DIR):
"""
按照训练时的图像和标注路径创建文件夹
:param label_path:当前文件路径
:return:
"""
# 生成训练集
train_image = os.path.join(label_path, 'train', 'images')
if not os.path.exists(train_image):
os.makedirs(train_image)
train_label = os.path.join(label_path, 'train', 'labels')
if not os.path.exists(train_label):
os.makedirs(train_label)
# 生成验证集
val_image = os.path.join(label_path, 'valid', 'images')
if not os.path.exists(val_image):
os.makedirs(val_image)
val_label = os.path.join(label_path, 'valid', 'labels')
if not os.path.exists(val_label):
os.makedirs(val_label)
# 生成测试集
test_image = os.path.join(label_path, 'test', 'images')
if not os.path.exists(test_image):
os.makedirs(test_image)
test_label = os.path.join(label_path, 'test', 'labels')
if not os.path.exists(test_label):
os.makedirs(test_label)
return train_image, train_label, val_image, val_label, test_image, test_label
'''
转换,根据图像大小,返回box框的中点和高宽信息
'''
def convert(size, box):
# 宽
dw = 1. / (size[0])
# 高
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
# 宽
w = box[1] - box[0]
# 高
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
'''
移动图像和标注文件到指定的训练集、验证集和测试集中
'''
def push_into_file(file, images, labels, label_path=ROOT_DIR, suffix='.jpg'):
"""
最终生成在当前文件夹下的所有文件按image和label分别存在到训练集/验证集/测试集路径的文件夹下
:param file: 文件名列表
:param images: 存放images的路径
:param labels: 存放labels的路径
:param label_path: 当前文件路径
:param suffix: 图像文件后缀
:return:
"""
# 遍历所有文件
for filename in file:
# 图像文件
image_file = os.path.join(label_path, filename + suffix)
# 标注文件
label_file = os.path.join(label_path, filename + '.txt')
# yolov5存放图像文件夹
if not os.path.exists(os.path.join(images, filename + suffix)):
try:
shutil.move(image_file, images)
except OSError:
pass
# yolov5存放标注文件夹
if not os.path.exists(os.path.join(labels, filename + suffix)):
try:
shutil.move(label_file, labels)
except OSError:
pass
'''
'''
def json2txt(classes, txt_Name='allfiles', label_path=ROOT_DIR, suffix='.jpg'):
"""
将json文件转化为txt文件,并将json文件存放到指定文件夹
:param classes: 类别名
:param txt_Name:txt文件,用来存放所有文件的路径
:param label_path:当前文件路径
:param suffix:图像文件后缀
:return:
"""
store_json = os.path.join(label_path, 'json')
if not os.path.exists(store_json):
os.makedirs(store_json)
_, _, _, files = split_dataset(label_path)
if not os.path.exists(os.path.join(label_path, 'tmp')):
os.makedirs(os.path.join(label_path, 'tmp'))
list_file = open('tmp/%s.txt' % txt_Name, 'w')
for json_file_ in tqdm(files):
json_filename = os.path.join(label_path, json_file_ + ".json")
imagePath = os.path.join(label_path, json_file_ + suffix)
list_file.write('%s\n' % imagePath)
out_file = open('%s/%s.txt' % (label_path, json_file_), 'w')
json_file = json.load(open(json_filename, "r", encoding="utf-8"))
if os.path.exists(imagePath):
height, width, channels = cv2.imread(imagePath).shape
for multi in json_file["shapes"]:
if len(multi["points"][0]) == 0:
out_file.write('')
continue
points = np.array(multi["points"])
xmin = min(points[:, 0]) if min(points[:, 0]) > 0 else 0
xmax = max(points[:, 0]) if max(points[:, 0]) > 0 else 0
ymin = min(points[:, 1]) if min(points[:, 1]) > 0 else 0
ymax = max(points[:, 1]) if max(points[:, 1]) > 0 else 0
label = multi["label"]
if xmax <= xmin:
pass
elif ymax <= ymin:
pass
else:
cls_id = classes.index(label)
b = (float(xmin), float(xmax), float(ymin), float(ymax))
bb = convert((width, height), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# print(json_filename, xmin, ymin, xmax, ymax, cls_id)
if not os.path.exists(os.path.join(store_json, json_file_ + '.json')):
try:
shutil.move(json_filename, store_json)
except OSError:
pass
'''
创建yaml文件
'''
def create_yaml(classes, label_path, isUseTest=False):
nc = len(classes)
if not isUseTest:
desired_caps = {
'path': label_path,
'train': 'train/images',
'val': 'valid/images',
'nc': nc,
'names': classes
}
else:
desired_caps = {
'path': label_path,
'train': 'train/images',
'val': 'valid/images',
'test': 'test/images',
'nc': nc,
'names': classes
}
yamlpath = os.path.join(label_path, "data" + ".yaml")
# 写入到yaml文件
with open(yamlpath, "w+", encoding="utf-8") as f:
for key, val in desired_caps.items():
yaml.dump({key: val}, f, default_flow_style=False)
# 首先确保当前文件夹下的所有图片统一后缀,如.jpg,如果为其他后缀,将suffix改为对应的后缀,如.png
def ChangeToYolo5(label_path=ROOT_DIR, suffix='.jpg', test_size=0.1, isUseTest=False):
"""
生成最终标准格式的文件
:param test_size: 分割测试集或验证集的比例
:param label_path:当前文件路径
:param suffix: 文件后缀名
:param isUseTest: 是否使用测试集
:return:
"""
# step1:统一图像格式
change_image_format(label_path)
# step2:根据json文件划分训练集、验证集、测试集
train_files, val_files, test_file, files = split_dataset(label_path, test_size=test_size, isUseTest=isUseTest)
# step3:根据json文件,获取所有类别
classes = get_all_class(files)
# step4:将json文件转化为txt文件,并将json文件存放到指定文件夹
json2txt(classes)
# step5:创建yolov5训练所需的yaml文件
create_yaml(classes, label_path, isUseTest=isUseTest)
# step6:生成yolov5的训练、验证、测试集的文件夹
train_image, train_label, val_image, val_label, test_image, test_label = create_save_file(label_path)
# step7:将所有图像和标注文件,移动到对应的训练集、验证集、测试集
push_into_file(train_files, train_image, train_label, suffix=suffix) # 将文件移动到训练集文件中
push_into_file(val_files, val_image, val_label, suffix=suffix) # 将文件移动到验证集文件夹中
if test_file is not None: # 如果测试集存在,则将文件移动到测试集文件中
push_into_file(test_file, test_image, test_label, suffix=suffix)
print('create dataset done')
if __name__ == "__main__":
ChangeToYolo5()
2 训练模型
普通训练
python train.py --epochs 1000 --weights yolov5s.pt --batch-size 16 --data .\wheatDetect\wheat.yaml --workers 0 --project AI_Model --name wheat --imgsz 1024 --device 0 --rect --exist-ok
数据增强版训练
- 自定义马赛克数据增强
- MixUp
- 大幅度数据增强
--hyp .\data\hyps\hyp.scratch-high.yaml
python train.py --epochs 1000 --weights .\AI_Model\wheat\weights\best.pt --batch-size 18 --data .\wheatDetect\wheat.yaml --workers 0 --project AI_Model --name wheat2 --imgsz 1024 --device 0 --exist-ok --hyp .\data\hyps\hyp.scratch-high.yaml
使用遗传算法自动调参训练--evolve
yolov5项目中,遗传算法使用了在两个地方中,
对anchor进行变异优化;
对超参数进行变异优化(yolov5中包含30个左右的超参数来对训练过程进行设置,如此多的超参数如果使用网格搜索来获得最佳结果是比较困难的,所以使用了遗传算法来求出一个局部最优解——获得较好的超参数结果。)
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve
3 验证模型
3.1 基本验证
python val.py --weights .\AI_Model\wheat2\weights\best.pt --data .\wheatDetect\wheat.yaml --img 1024 --half --batch 12
3.2 TTA 增强验证
python val.py --weights .\AI_Model\wheat2\weights\best.pt --data .\wheatDetect\wheat.yaml --img 1024 --half --batch 12 --augment
3.3 模型集成-验证
python val.py --weights .\weights\best1.pt .\weights\best2.pt --data .\wheatDetect\wheat.yaml --img 1024 --half --batch 12
4 模型推理
python detect.py --weights .\AI_Model\wheat\weights\best.pt --source .\WheatDataSet\images\val --img 1024
命令运行-导出onnx,tensorrt-engine,openvino
python export.py --weights yolov5s.pt --include torchscript onnx openvino engine coreml tflite ...
5 使用torch.hub加载训练模型,进行预测
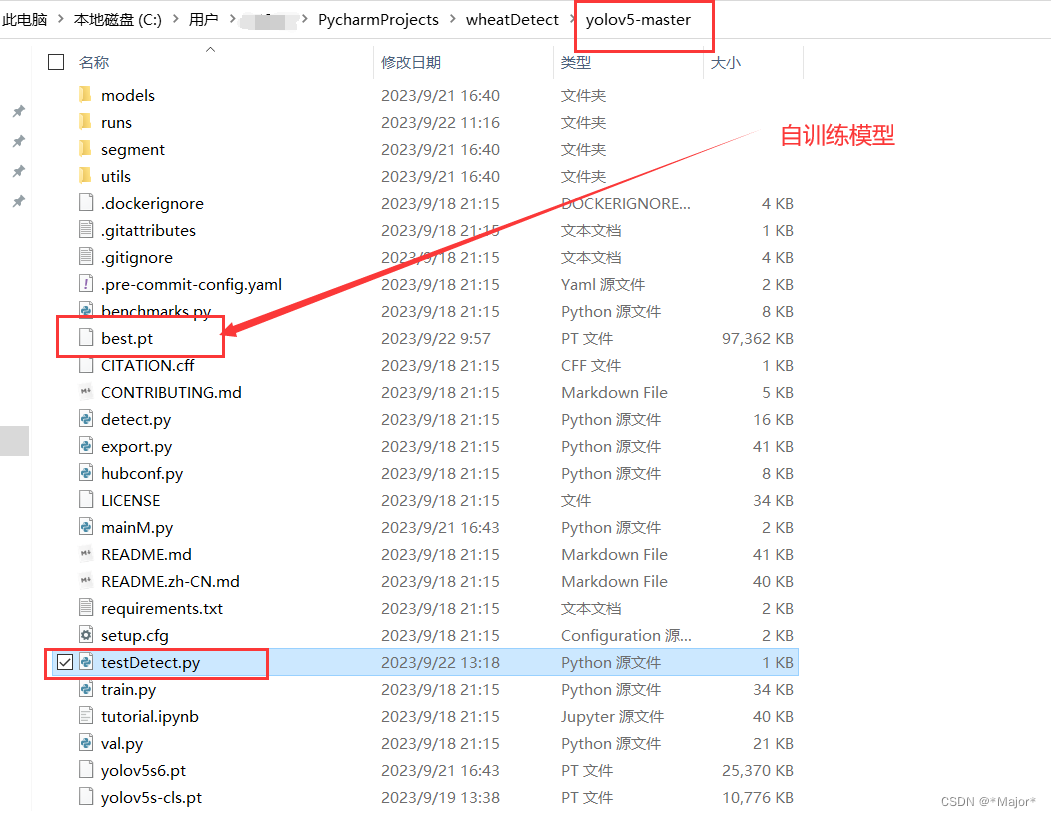
testDetect.py
import torch
# Model
model = torch.hub.load('.', 'custom', path=r'best.pt',source='local')
# Images
img = r'D:\PycharmProjects\wheatDetect\WheatDataSet\images\val\0a4408b37.jpg' # or file, PIL, OpenCV, numpy, multiple
# Inference
results = model(img, augment=False) # <--- TTA inference
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
results.show()


6 使用torch.hub加载tenorRT引擎、onnx、openVino等
model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.pt') # PyTorch
'yolov5s.torchscript') # TorchScript
'yolov5s.onnx') # ONNX
'yolov5s_openvino_model/') # OpenVINO
'yolov5s.engine') # TensorRT
'yolov5s.mlmodel') # CoreML (macOS-only)
'yolov5s.tflite') # TFLite
'yolov5s_paddle_model/') # PaddlePaddle
7 flask-restful-API部署测试
"""
Run a Flask REST API exposing one or more YOLOv5s models
"""
import argparse
import io
import torch
from flask import Flask, request
from PIL import Image
app = Flask(__name__)
models = {}
DETECTION_URL = '/v1/object-detection/<model>'
@app.route(DETECTION_URL, methods=['POST'])
def predict(model):
if request.method != 'POST':
return
if request.files.get('image'):
# Method 1
# with request.files["image"] as f:
# im = Image.open(io.BytesIO(f.read()))
# Method 2
im_file = request.files['image']
im_bytes = im_file.read()
im = Image.open(io.BytesIO(im_bytes))
if model in models:
results = models[model](im, size=640) # reduce size=320 for faster inference
return results.pandas().xyxy[0].to_json(orient='records')
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Flask API exposing YOLOv5 model')
parser.add_argument('--port', default=5000, type=int, help='port number')
parser.add_argument('--model', nargs='+', default=['yolov5s'], help='model(s) to run, i.e. --model yolov5n yolov5s')
opt = parser.parse_args()
for m in opt.model:
# models[m] = torch.hub.load('ultralytics/yolov5', m, force_reload=True, skip_validation=True)
models[m] = torch.hub.load('../..', 'custom', path=r'../../best.pt', source='local')
app.run(host='0.0.0.0', port=opt.port) # debug=True causes Restarting with stat
模拟客户端发送请求
import pprint
import requests
DETECTION_URL = 'http://localhost:5000/v1/object-detection/yolov5s'
IMAGE = r'C:\Users\29939\PycharmProjects\wheatDetect\WheatDataSet\images\val\1a94773a1.jpg'
# Read image
with open(IMAGE, 'rb') as f:
image_data = f.read()
response = requests.post(DETECTION_URL, files={'image': image_data}).json()
pprint.pprint(response)

三 Yolov5之图像实例分割
1 数据集准备
labelme数据集转检yolov5分割数据集
path: D:\workplace\yolov5-master-latest\datasets\DogCat-seg # dataset root dir
train: images/train # train images (relative to 'path')
val: images/val # val images (relative to 'path')
test: # test images (optional)
# Classes
names:
0: dog
1: cat
# -*- coding: utf-8 -*-
import os
import numpy as np
import json
from glob import glob
import cv2
import shutil
import yaml
from sklearn.model_selection import train_test_split
from tqdm import tqdm
from PIL import Image
'''
辅助函数
'''
'''
转换,根据图像大小,返回box框的中点和高宽信息
'''
def convert(size, points):
# 转换后的返回列表
converted_points_list = []
# 宽
dw = 1. / (size[0])
# 高
dh = 1. / (size[1])
for point in points:
x = point[0] * dw
converted_points_list.append(x)
y = point[1] * dh
converted_points_list.append(y)
return converted_points_list
'''
# step1:统一图像格式
'''
def change_image_format(label_path, suffix='.jpg'):
"""
统一当前文件夹下所有图像的格式,如'.jpg'
:param suffix: 图像文件后缀
:param label_path:当前文件路径
:return:
"""
print("step1:统一图像格式")
# 修改尾缀列表
externs = ['png', 'jpg', 'JPEG', 'bmp']
files = list()
# 获取尾缀在externs中的所有图像
for extern in externs:
files.extend(glob(label_path + "\\*." + extern))
# 遍历所有图像,转换图像格式
for index,file in enumerate(tqdm(files)):
name = ''.join(file.split('.')[:-1])
file_suffix = file.split('.')[-1]
if file_suffix != suffix.split('.')[-1]:
# 重命名为jpg
new_name = name + suffix
# 读取图像
image = Image.open(file)
image = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
# 重新存图为jpg格式
cv2.imwrite(new_name, image)
# 删除旧图像
os.remove(file)
'''
# step2:根据json文件划分训练集、验证集、测试集
'''
def split_dataset(ROOT_DIR, test_size=0.3, isUseTest=False, useNumpyShuffle=False):
"""
将文件分为训练集,测试集和验证集
:param useNumpyShuffle: 使用numpy方法分割数据集
:param test_size: 分割测试集或验证集的比例
:param isUseTest: 是否使用测试集,默认为False
:param label_path:当前文件路径
:return:
"""
# 获取所有json
print('step2:根据json文件划分训练集、验证集、测试集')
# 获取所有json文件路径
files = glob(ROOT_DIR + "\\*.json")
# 转换为json名称
files = [i.replace("\\", "/").split("/")[-1].split(".json")[0] for i in files]
# 是否打乱
if useNumpyShuffle:
file_length = len(files)
index = np.arange(file_length)
np.random.seed(32)
np.random.shuffle(index) # 随机划分
test_files = None
# 是否有测试集
if isUseTest:
trainval_files, test_files = np.array(files)[index[:int(file_length * (1 - test_size))]], np.array(files)[
index[int(file_length * (1 - test_size)):]]
else:
trainval_files = files
# 划分训练集和测试集
train_files, val_files = np.array(trainval_files)[index[:int(len(trainval_files) * (1 - test_size))]], \
np.array(trainval_files)[index[int(len(trainval_files) * (1 - test_size)):]]
else:
test_files = None
# 判断是否启用测试集
if isUseTest:
trainval_files, test_files = train_test_split(files, test_size=test_size, random_state=55)
else:
trainval_files = files
if len(trainval_files) != 0:
# 划分训练集和验证集
train_files, val_files = train_test_split(trainval_files, test_size=test_size, random_state=55)
else:
print("数据文件为空")
return train_files, val_files, test_files, files
'''
# step3:根据json文件,获取所有类别
'''
def get_all_class(file_list, ROOT_DIR):
"""
从json文件中获取当前数据的所有类别
:param file_list:当前路径下的所有文件名
:param label_path:当前文件路径
:return:
"""
print('step3:根据json文件,获取所有类别')
# 初始化类别列表
classes = list()
# 遍历所有json,读取shape中的label值内容,添加到classes
for filename in tqdm(file_list):
json_path = os.path.join(ROOT_DIR, filename + '.json')
json_file = json.load(open(json_path, "r", encoding="utf-8"))
for item in json_file["shapes"]:
label_class = item['label']
# 如果没有添加新的类型,则
if label_class not in classes:
classes.append(label_class)
print('read file done')
return classes
'''
# step4:将json文件转化为txt文件,并将json文件存放到指定文件夹
'''
def json2txt(classes, txt_Name='allfiles', ROOT_DIR="", suffix='.jpg'):
"""
将json文件转化为txt文件,并将json文件存放到指定文件夹
:param classes: 类别名
:param txt_Name:txt文件,用来存放所有文件的路径
:param label_path:当前文件路径
:param suffix:图像文件后缀
:return:
"""
print('step4:将json文件转化为txt文件,并将json文件存放到指定文件夹')
store_json = os.path.join(ROOT_DIR, 'json')
if not os.path.exists(store_json):
os.makedirs(store_json)
_, _, _, files = split_dataset(ROOT_DIR)
if not os.path.exists(os.path.join(ROOT_DIR, 'tmp')):
os.makedirs(os.path.join(ROOT_DIR, 'tmp'))
list_file = open(os.path.join(ROOT_DIR,'tmp/%s.txt'% txt_Name) , 'w')
for json_file_ in tqdm(files):
# json路径
json_filename = os.path.join(ROOT_DIR, json_file_ + ".json")
# 图像路径
imagePath = os.path.join(ROOT_DIR, json_file_ + suffix)
# 写入图像文件夹路径
list_file.write('%s\n' % imagePath)
# 转换后txt标签文件夹路径
out_file = open('%s/%s.txt' % (ROOT_DIR, json_file_), 'w')
# 加载标签json文件
json_file = json.load(open(json_filename, "r", encoding="utf-8"))
'''
核心:标签转换(json转txt)
'''
if os.path.exists(imagePath):
# 读取图像
image = Image.open(imagePath)
image = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
# 获取图像高、宽、通道
height, width, channels = image.shape
# 获取shapes的Value值
for multi in json_file["shapes"]:
# 如果点位为空
if len(multi["points"][0]) == 0:
out_file.write('')
continue
# 获取单个缺陷的点位(x,y的list)
points = np.array(multi["points"])
# 标签
label = multi["label"]
# 类别id
cls_id = classes.index(label)
# 根据图像大小,返回box框的中点和高宽信息
xy_list = convert((width, height), points)
# 写txt标签文件
out_file.write(str(cls_id) + " " + " ".join([str(xy) for xy in xy_list]) + '\n')
if not os.path.exists(os.path.join(store_json, json_file_ + '.json')):
try:
shutil.move(json_filename, store_json)
except OSError:
pass
'''
# step5:创建yolov5训练所需的yaml文件
'''
def create_yaml(classes, ROOT_DIR, isUseTest=False):
print('step5:创建yolov5训练所需的yaml文件')
classes_dict = {}
for index, item in enumerate(classes):
classes_dict[index] = item
if not isUseTest:
desired_caps = {
'path': ROOT_DIR,
'train': 'images/train',
'val': 'images/val',
'names': classes_dict
}
else:
desired_caps = {
'path': ROOT_DIR,
'train': 'images/train',
'val': 'images/val',
'test': 'images/test',
'names': classes_dict
}
yamlpath = os.path.join(ROOT_DIR, "data" + ".yaml")
# 写入到yaml文件
with open(yamlpath, "w+", encoding="utf-8") as f:
for key, val in desired_caps.items():
yaml.dump({key: val}, f, default_flow_style=False)
'''
# step6:生成yolov5的训练、验证、测试集的文件夹
'''
def create_save_file(ROOT_DIR):
"""
按照训练时的图像和标注路径创建文件夹
:param label_path:当前文件路径
:return:
"""
print('step6:生成yolov5的训练、验证、测试集的文件夹')
# 生成训练集
train_image = os.path.join(ROOT_DIR, 'images','train')
if not os.path.exists(train_image):
os.makedirs(train_image)
train_label = os.path.join(ROOT_DIR, 'labels','train')
if not os.path.exists(train_label):
os.makedirs(train_label)
# 生成验证集
val_image = os.path.join(ROOT_DIR, 'images', 'val')
if not os.path.exists(val_image):
os.makedirs(val_image)
val_label = os.path.join(ROOT_DIR, 'labels', 'val')
if not os.path.exists(val_label):
os.makedirs(val_label)
# 生成测试集
test_image = os.path.join(ROOT_DIR, 'images', 'test')
if not os.path.exists(test_image):
os.makedirs(test_image)
test_label = os.path.join(ROOT_DIR, 'labels', 'test')
if not os.path.exists(test_label):
os.makedirs(test_label)
return train_image, train_label, val_image, val_label, test_image, test_label
'''
# step7:将所有图像和标注文件,移动到对应的训练集、验证集、测试集
'''
def push_into_file(file, images, labels, ROOT_DIR, suffix='.jpg'):
"""
最终生成在当前文件夹下的所有文件按image和label分别存在到训练集/验证集/测试集路径的文件夹下
:param file: 文件名列表
:param images: 存放images的路径
:param labels: 存放labels的路径
:param label_path: 当前文件路径
:param suffix: 图像文件后缀
:return:
"""
print('step7:将所有图像和标注文件,移动到对应的训练集、验证集、测试集')
# 遍历所有文件
for filename in tqdm(file):
# 图像文件
image_file = os.path.join(ROOT_DIR, filename + suffix)
# 标注文件
label_file = os.path.join(ROOT_DIR, filename + '.txt')
# yolov5存放图像文件夹
if not os.path.exists(os.path.join(images, filename + suffix)):
try:
shutil.move(image_file, images)
except OSError:
pass
# yolov5存放标注文件夹
if not os.path.exists(os.path.join(labels, filename + suffix)):
try:
shutil.move(label_file, labels)
except OSError:
pass
'''
labelme的json标签转yolo的txt标签
'''
def ChangeToYolo5(ROOT_DIR="", suffix='.bmp', test_size=0.1, isUseTest=False,useNumpyShuffle=False,auto_genClasses = False):
"""
生成最终标准格式的文件
:param test_size: 分割测试集或验证集的比例
:param label_path:当前文件路径
:param suffix: 文件后缀名
:param isUseTest: 是否使用测试集
:return:
"""
# step1:统一图像格式
change_image_format(ROOT_DIR, suffix=suffix)
# step2:根据json文件划分训练集、验证集、测试集
train_files, val_files, test_file, files = split_dataset(ROOT_DIR, test_size=test_size, isUseTest=isUseTest, useNumpyShuffle=useNumpyShuffle)
# step3:根据json文件,获取所有类别
classes = ['Dent','Scratch']
# 是否自动从数据集中获取类别数
if auto_genClasses:
classes = get_all_class(files, ROOT_DIR)
'''
step4:(***核心***)将json文件转化为txt文件,并将json文件存放到指定文件夹
'''
json2txt(classes, txt_Name='allfiles', ROOT_DIR=ROOT_DIR, suffix=suffix)
# step5:创建yolov5训练所需的yaml文件
create_yaml(classes, ROOT_DIR, isUseTest=isUseTest)
# step6:生成yolov5的训练、验证、测试集的文件夹
train_image_dir, train_label_dir, val_image_dir, val_label_dir, test_image_dir, test_label_dir = create_save_file(ROOT_DIR)
# step7:将所有图像和标注文件,移动到对应的训练集、验证集、测试集file, images, labels, ROOT_DIR, suffix='.jpg'
# 将文件移动到训练集文件中
push_into_file(train_files, train_image_dir, train_label_dir,ROOT_DIR=ROOT_DIR, suffix=suffix)
# 将文件移动到验证集文件夹中
push_into_file(val_files, val_image_dir, val_label_dir,ROOT_DIR=ROOT_DIR, suffix=suffix)
# 如果测试集存在,则将文件移动到测试集文件中
if test_file is not None:
push_into_file(test_file, test_image_dir, test_label_dir, ROOT_DIR=ROOT_DIR, suffix=suffix)
print('create dataset done')
if __name__ == "__main__":
'''
1.ROOT_DIR:图像和json标签的路径
2.suffix:统一图像尾缀
3.test_size:测试集和验证集所占比例
4.isUseTest:是否启用测试集
5.useNumpyShuffle:是否随机打乱
6.auto_genClasses:是否自动根据json标签生成类别列表
'''
ChangeToYolo5(ROOT_DIR = r'D:\dataset\Side_Line_Chang_DataSet\SegYolo2', suffix='.bmp',test_size=0.1, isUseTest=False,useNumpyShuffle=False,auto_genClasses = False)
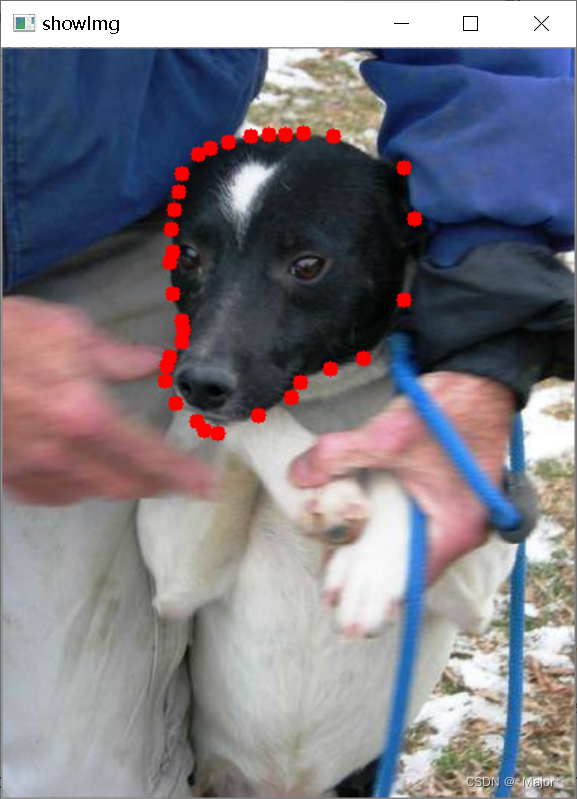
showSeg
import numpy as np
import cv2
# 读取标签
label_path = r"D:\dataset\Side_Line_Chang_DataSet\SegYolo2\labels\train\item_00000000.txt"
# 读取图像
img = cv2.imread(r'D:\dataset\Side_Line_Chang_DataSet\SegYolo\train\images\item_00000000.jpg')
height, width, channels = img.shape
with open(label_path,'r') as f:
current_line = f.readline()
while current_line:
temp_list = current_line.split(' ')
for index in range(1,len(temp_list),2):
num1 = float(temp_list[index])
num2 = float(temp_list[index+1])
# 圆点显示
cv2.circle(img,(int(width * num1), int(height * num2)), 5, (0, 0, 255), -1)
current_line = f.readline()
winname = 'showImg'
cv2.namedWindow(winname)
cv2.imshow(winname, img)
cv2.waitKey(0)
cv2.destroyWindow(winname)
# 保存图像
cv2.imwrite('test.jpg',img)
2 训练模型
python segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640
3 验证模型
python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 # validate
4 模型推理
python segment/predict.py --weights yolov5m-seg.pt --source data/images/bus.jpg
使用yolov5进行图像分类、检测、分割任务(labelme转yolov5分割和检测数据集)
py文件-训练
from train import main,parse_opt
from classify.train import main as cls_main,parse_opt as cls_parse_opt
from segment.train import main as seg_main,parse_opt as seg_parse_opt
# 检测任务
# opt = parse_opt()
# kwargs = {"epochs": 1000,
# "weights": r"yolov5s.pt",
# "batch_size": 4,
# "data": "ZH.yaml",
# "workers": 0,
# "project": "AI_Model",
# "name": "ZH",
# "imgsz": 450,
# "device": 0,
# "rect": True,
# "exist_ok": True}
#
# for k, v in kwargs.items():
# setattr(opt, k, v)
#
# main(opt=opt)
# 分类任务
# cls_opt = cls_parse_opt()
# kwargs = {"epochs": 1000,
# "weights": r"yolov5s-cls.pt",
# "batch_size": 64,
# "data": r"C:\Users\11716\Desktop\dogAndcat-cls\dogAndcat-cls",
# "workers": 0,
# "project": "AI_Model",
# "name": "cat_dog_cls",
# "imgsz": 32,
# "device": 0,
# "rect": True,
# "exist_ok": True}
#
# for k, v in kwargs.items():
# setattr(cls_opt, k, v)
#
# cls_main(opt=cls_opt)
# 分割任务
seg_opt = seg_parse_opt()
kwargs = {"epochs": 1000,
"weights": r"yolov5s-seg.pt",
"batch_size": 4,
"data": r"F:\D\Al_Algo\yolov5-master\data\segTest.yaml",
"workers": 0,
"project": "AI_Model",
"name": "cat_dog_seg",
"imgsz": 512,
"device": 0,
"rect": True,
"exist_ok": True}
for k, v in kwargs.items():
setattr(seg_opt, k, v)
seg_main(opt=seg_opt)
py文件-导出
if __name__ == '__main__':
opt = parse_opt()
kwargs = {
"weights": r"F:\yolov5_OpenVinoAndTensorRT\seg\cat_dog_seg\weights\best.pt",
"include": 'engine',
"imgsz": [512, 512],
"include": ["openvino"],
}
for k, v in kwargs.items():
setattr(opt, k, v)
main(opt)
训练参数
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
# Logger arguments
parser.add_argument('--entity', default=None, help='Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='Version of dataset artifact to use')
return parser.parse_known_args()[0] if known else parser.parse_args()
def main(opt, callbacks=Callbacks()):
# Checks
if RANK in {-1, 0}:
print_args(vars(opt))
check_git_status()
check_requirements(ROOT / 'requirements.txt')
# Resume (from specified or most recent last.pt)
if opt.resume and not check_comet_resume(opt) and not opt.evolve:
last = Path(check_file(opt.resume) if isinstance(opt.resume, str) else get_latest_run())
opt_yaml = last.parent.parent / 'opt.yaml' # train options yaml
opt_data = opt.data # original dataset
if opt_yaml.is_file():
with open(opt_yaml, errors='ignore') as f:















 2357
2357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









