







网络结构
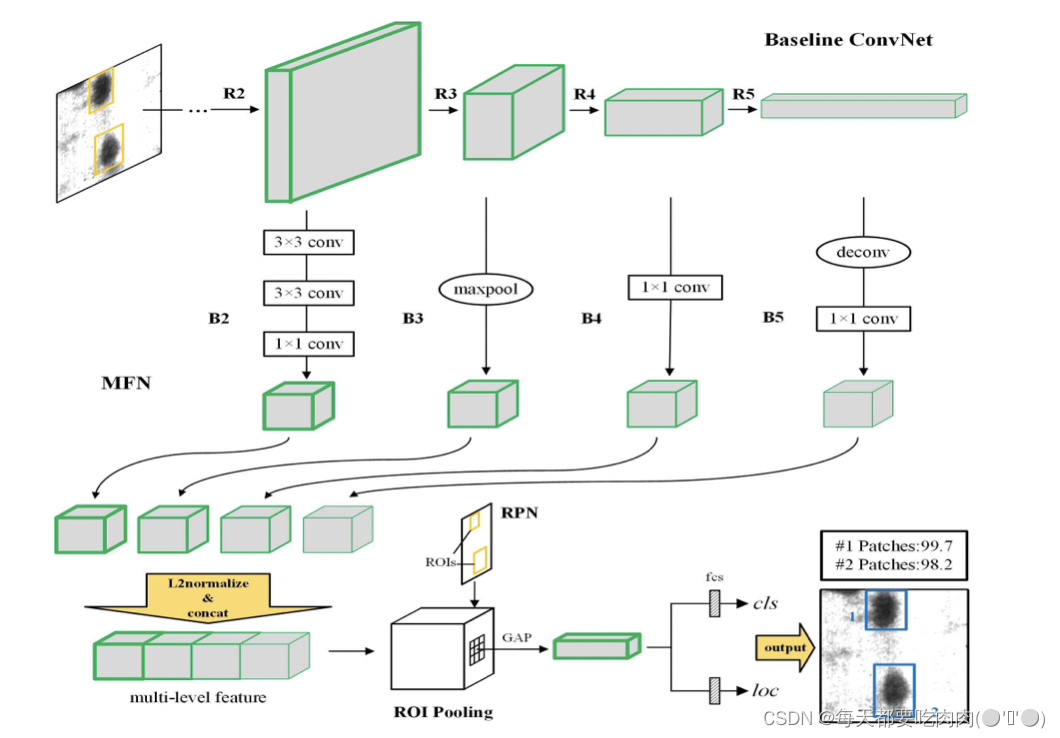
建立了一个端到端的ADI系统,即缺陷检测网络(DDN)。使用ResNet在每个阶段生成特征图,然后所提出的多级特征融合网络(MFN)将ResNet的所有阶段的特征合并到一个特征中,该特征可以包括更多缺陷的位置细节。基于这些多层次特征,采用区域建议网络(RPN)生成感兴趣区域(ROI)。通过ROI池和全局平均池化层(GAP),将每个ROI对应的MFN特征转换为固定长度特征。得到的特征送到两个全连接层中,一个是(C+1)缺陷分类层(“cls”),另一个是边界框回归层(“loc”)分别输出类分数和边界框坐标。最后建立了一个缺陷检测数据集NEU DET,用于训练和评估上述方法。
论文主要解决了三个问题:
- 构建分类能力强大的模型:先在imagenet上预训练ResNet(作为backbone)来获得强大的分类能力的网络,然后在NEU-DET数据集上进行微调。
- 融合所有阶段的多个特征:由于工业界数据集普遍使用灰色图像,而灰色图像的信息比彩色图像少,所以提出MFN结构融合所有阶段的特征(Hypernet主要融合网络的后部分,没有融合低级特征)。此外,MFN可以通过修改1×1滤波器数量来减少参数,并且在融合之前统一了多个特征的大小。
- 建立缺陷检测数据集NEU -DET:公开了缺陷检测数据集NEU DET用于预训练,以便执行缺陷检测任务
损失函数
同faster rcnn
五步联合训练法
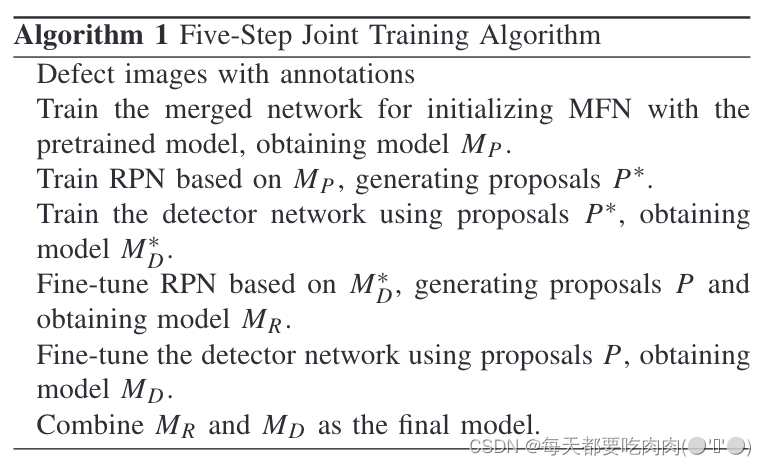
对于预训练的网络,MFN和RPN是新的层。因此,我们需要通过训练使这三个网络共享卷积特征。预训练模型本质上是一个分类网络,而MFN生成的特征图可以直接输入到分类层。因此,预训练网络和MFN可以合并为一个网络,然后执行端到端训练。将DDN除去RPN的其余部称为检测网络。为了与RPN共享特征,采用五步联合交替训练策略,在训练RPN和训练检测器网络之间交替。在步骤2和步骤3之后,RPN和检测器网络依次使用ImageNet预训练模型初始化。然而这两个网络在此时没有共享卷积特征。在完成步骤3和步骤4的微调过程后得到共享卷积层。具体来说,我们冻结了共享的卷积层,只对非共享层进行微调。最后将两个网络合并为独立网络。
评估指标:mAP
AP与mAP的详解_micro wen的博客-CSDN博客_ap和map
目标检测中map的计算_RooKiChen的博客-CSDN博客_map计算公式
缺陷检测数据集NEU DET

缺陷检测需要考虑缺陷的数量、类别和复杂性将作为评估钢板质量的主要指标。
热轧钢板有六种缺陷,包括裂纹、夹杂物、补丁、麻面、轧成鳞和划痕。每个类有300个图像,但这并不意味着一个图像包含一个缺陷。注释保存为XML文件,内容为图像中出现的每个缺陷的类别和边界框(左上角和右下角坐标)总共有近5000个gt边界框
训练集1260,测试集540
可改进点
一个是数据增强技术,这是由于检测数据集中的人工注释非常昂贵。另一种是使用DL技术执行缺陷分割任务,这可以获得更精确的缺陷边界。
其它
- DL可以通过深度网络[例如卷积神经网络(CNN)]提取特征。这些特征可以达到高度抽象,因此具有很强的表征能力。相比之下,人工提取的特征仅仅是低级特征的组合。
- CNN的卷积层可以被视为过滤器,这导致当图像在CNN中流动时,某些位置细节将逐渐变为最模糊。而浅层特征具有丰富的信息(点线面),但不具有足够的辨别力,深层特征具有较强的语义,但丢失了太多细节->融合多层次特征
- 1×1卷积:可以保存更多的图像细节,使用更少的模型参数。使得MFN在计算效率和泛化能力方面都很强。可能会损害精度,但在训练数据不足的情况下会防止过度拟合
- MFN应该组合哪些层?有两个基本条件:不相邻,因为相邻层具有高度的局部相关性,以及覆盖性,应包括从低层到高层的特征。所以组合了ResNet每个剩余块中的最后一层
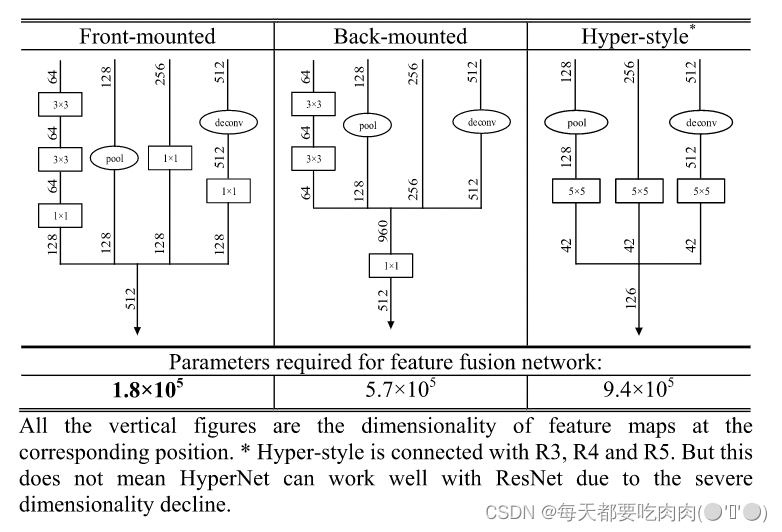
- MFN中使用1*1卷积来统一维度,有两种放置方式:front-mounted和back-mounted,back-mounted方式更简单但需要更多的参数量,
- 关于RPN的解释:RPN通过在特征图上滑动来提取候选框。RPN以任意大小的图像作为输入,并输出anchor(候选框),每个anchor都有一个表示其是否为缺陷的分数。RPN的独创性是以多种大小和尺度比制作anchor。然后将anchor分层映射到输入图像,从而产生多种大小和尺度比的候选框。由于MFN特征的分辨率大小,RPN可被视为在R4特征上滑动。我们设置了三个尺度比{1:1,1:2,2:1},四个大小{64^2、128^2、256^2、512^2}。因此,RPN在每个滑动位置产生12个anchor。候选框提取器总是以ROI pooling层结束。该层对ROI每个特征层执行max pooling将其转换为固定大小为W×H(本文中为7×7)的特征向量(ResNet34为512-d,ResNet50为2048-d)。最后基于这些特征向量,计算每个候选框与相邻gt的偏移以及是否存在缺陷的概率。对于单个图像,RPN可以提取数千个候选框。为了处理冗余信息,将NMS的IOU阈值设置为0.7来消除高重叠的候选框。NMS之后,从剩余候选框中选择前k个。我们使用前300个候选框对DDN进行微调,在测试时减少该数字以加快检测速度,而不影响准确度。
- 一个好的检测器应该有尽可能少的候选框,同时也要有相对高的IOU阈值














 1993
1993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









