







目标检测architecture通常可以分为两个阶段:
(1)region proposal:给定一张输入image找出objects可能存在的所有位置。这一阶段的输出应该是一系列object可能位置的bounding box。这些通常称之为region proposals或者 regions of interest(ROI),在这一过程中用到的方法是基于滑窗的方式和selective search。
(2)final classification:确定上一阶段的每个region proposal是否属于目标一类或者背景。
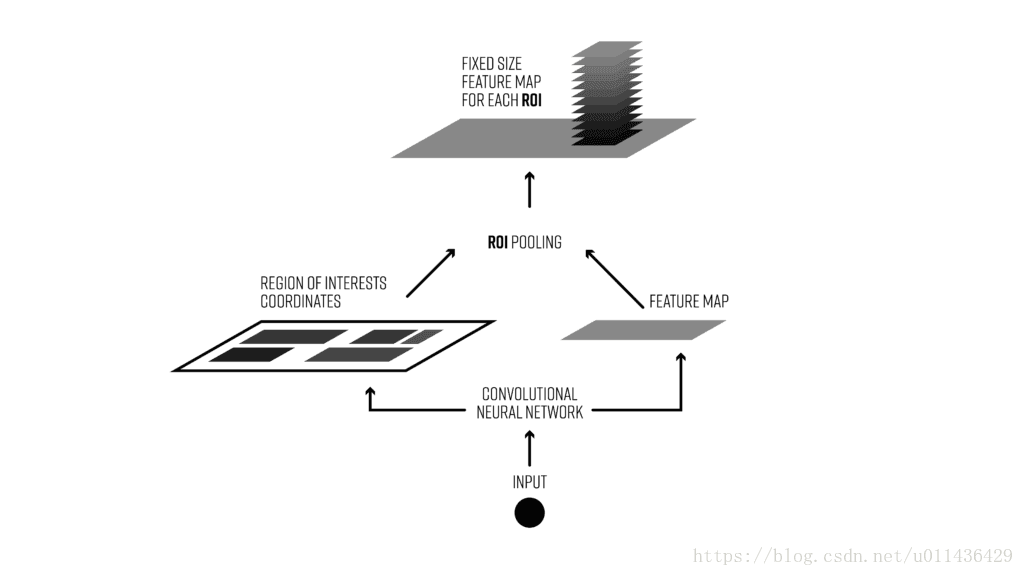
这个architecture存在的一些问题是:
- 产生大量的region proposals 会导致performance problems,很难达到实时目标检测。
- 在处理速度方面是suboptimal。
- 无法做到end-to-end training。
这就是ROI pooling提出的根本原因,ROI pooling层能实现training和testing的显著加速,并提高检测accuracy。该层有两个输入:
- 从具有多个卷积核池化的深度网络中获得的固定大小的feature maps;
- 一个表示所有ROI的N*5的矩阵,其中N表示ROI的数目。第一列表示图像index,其余四列表示其余的左上角和右下角坐标;
ROI pooling具体操作如下:
- 根据输入image,将ROI映射到feature map对应位置;
- 将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
- 对每个sections进行max pooling操作;
这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。ROI pooling 最大的好处就在于极大地提高了处理速度。
ROI pooling example
我们有一个8*8大小的feature map,一个ROI,以及输出大小为2*2.
- 输入的固定大小的feature map
- region proposal 投影之后位置(左上角,右下角坐标):(0,3),(7,8)。
- 将其划分为(2*2)个sections(因为输出大小为2*2),我们可以得到:
- 对每个section做max pooling,可以得到:
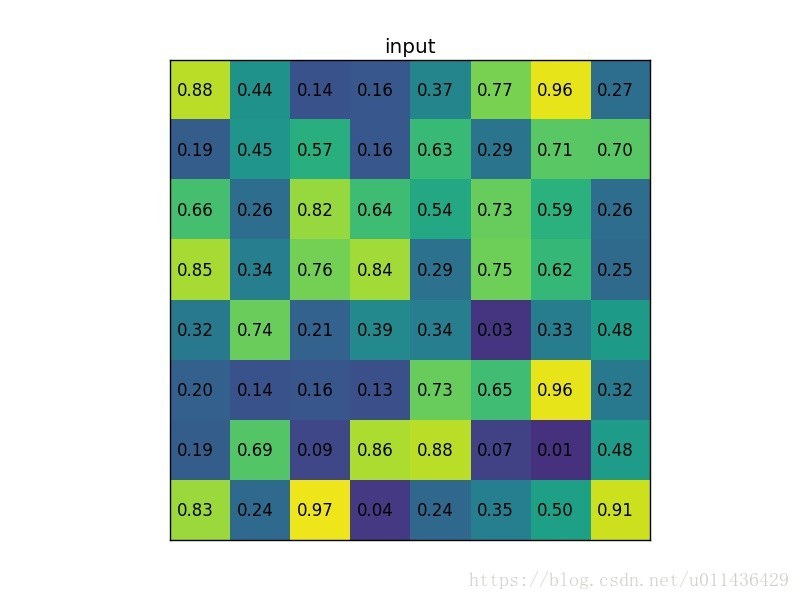
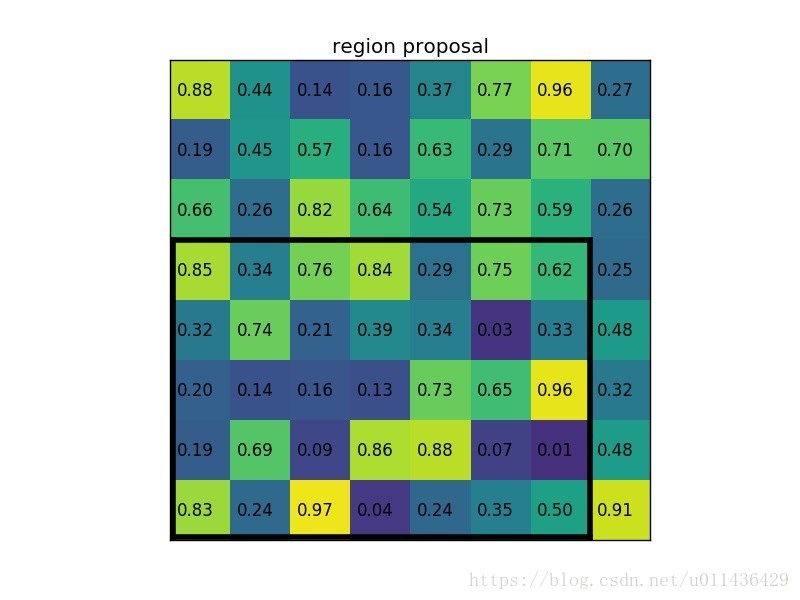
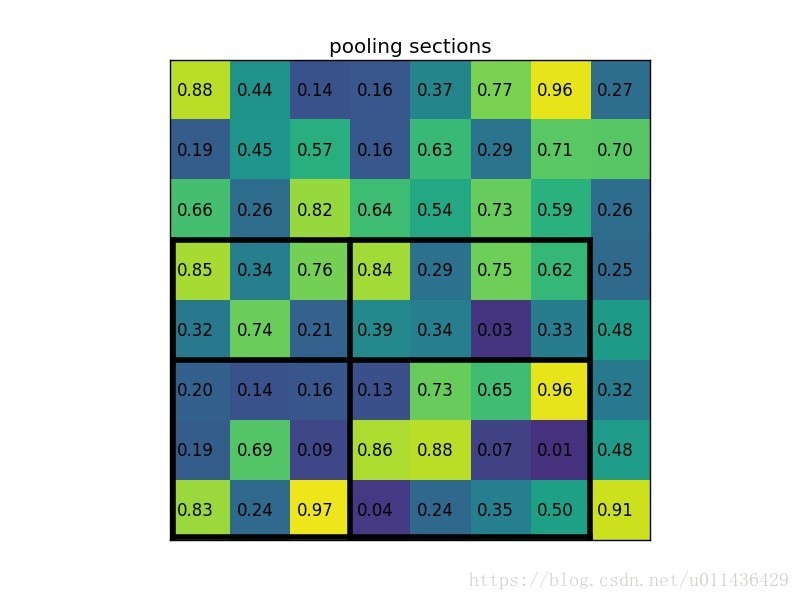
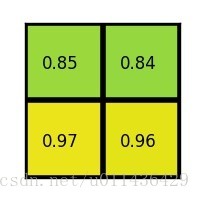
整体过程如下:
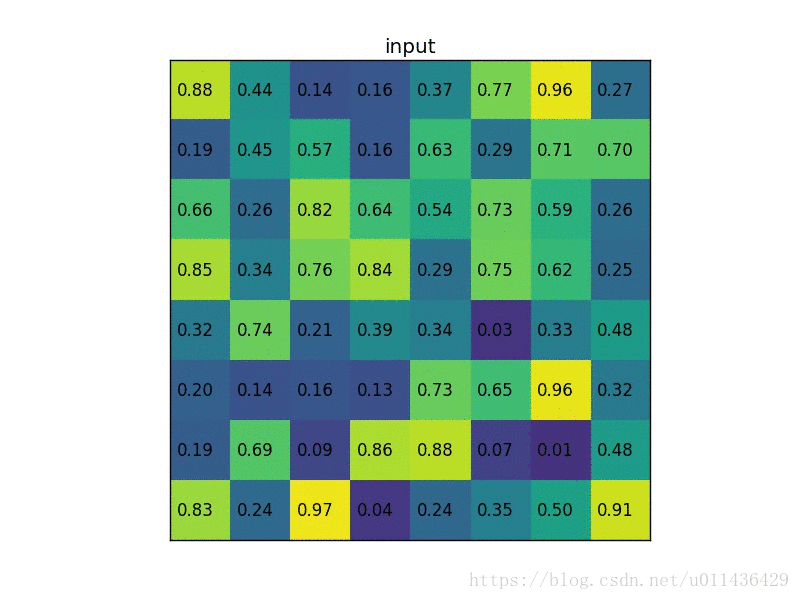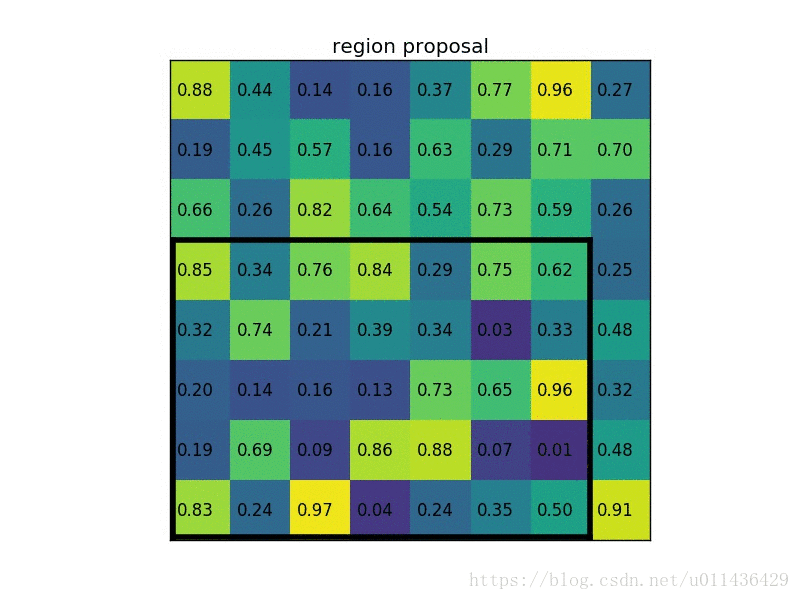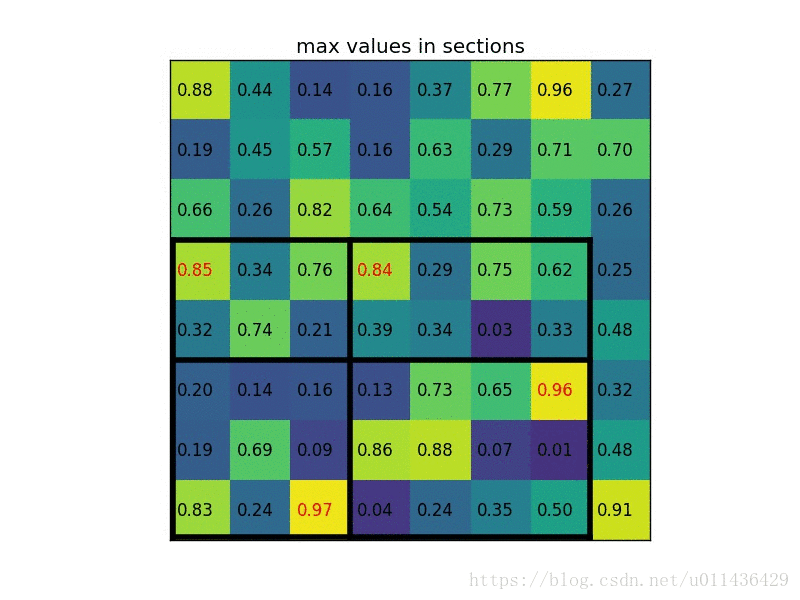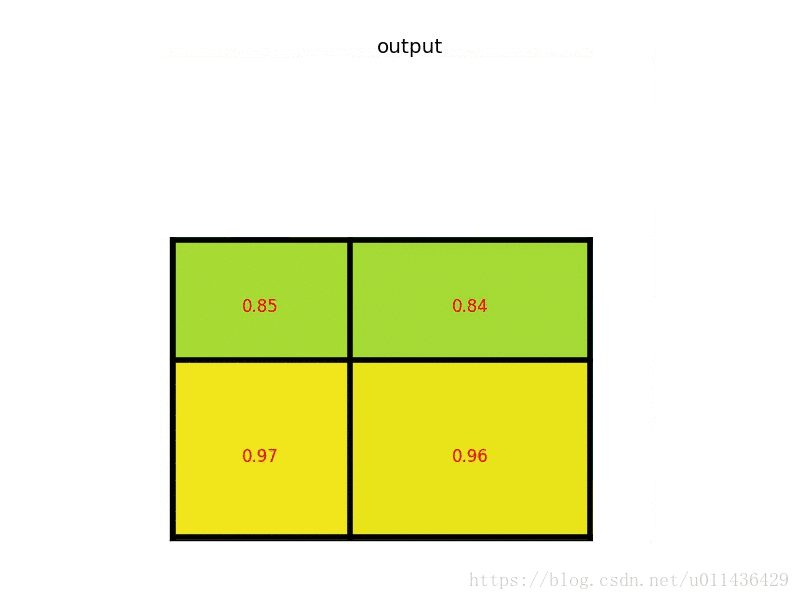
说明:在此案例中region proposals 是5*7大小的,在pooling之后需要得到2*2的,所以在5*7的特征图划分成2*2的时候不是等分的,行是5/2,第一行得到2,剩下的那一行是3,列是7/2,第一列得到3,剩下那一列是4。
ROI Pooling 就是将大小不同的feature map 池化成大小相同的feature map,利于输出到下一层网络中。
代码实现
$ git clone git@github.com:deepsense-io/roi-pooling.git
$ cd roi-pooling
$ python setup.py installfrom __future__ import print_function
import tensorflow as tf
import numpy as np
from roi_pooling.roi_pooling_ops import roi_pooling
# 4x4 feature map with only 1 channel
input_value = [[
[[1], [2], [4], [4]],
[[3], [4], [1], [2]],
[[6], [2], [1], [7]],
[[1], [3], [2], [8]]
]]
input_value = np.asarray(input_value, dtype='float32')
# regions of interest as lists of:
# feature map index, upper left, bottom right coordinates
rois_value = [
[0, 0, 0, 1, 3],
[0, 2, 2, 3, 3],
[0, 1, 0, 3, 2]
]
rois_value = np.asarray(rois_value, dtype='int32')
# in this case we have 3 RoI pooling operations:
# * channel 0, rectangular region (0, 0) to (1, 3)
# xx..
# xx..
# xx..
# xx..
#
# * channel 0, rectangular region (2, 2) to (3, 3)
# ....
# ....
# ..xx
# ..xx
# * channel 0, rectangular region (1, 0) to (3, 2)
# ....
# xxx.
# xxx.
# xxx.
input_featuremap = tf.placeholder(tf.float32)
rois = tf.placeholder(tf.int32)
input_const = tf.constant(input_value, tf.float32)
rois_const = tf.constant(rois_value, tf.int32)
y = roi_pooling(input_const, rois_const, pool_height=2, pool_width=2)
with tf.Session('') as sess:
y_output = sess.run(y, feed_dict={input_featuremap: input_value, rois: rois_value})
print(y_output) 输出
[[[[ 3. 4.]
[ 6. 3.]]]
[[[ 1. 7.]
[ 2. 8.]]]
[[[ 4. 4.]
[ 4. 7.]]]] 














 923
923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









