






(一个自然语言理解任务,一般需要分词、词性标注、句法分析、语义分析、语义推理等步骤。)
1.3 机器学习
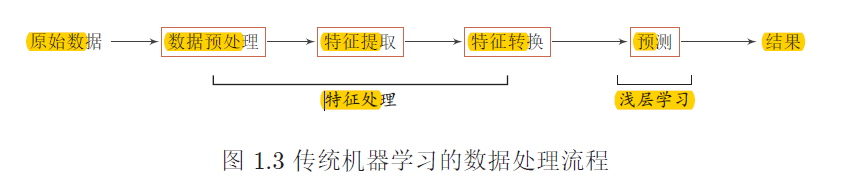
1)传统的机器学习模型主要关注于最后一步,即构建预测函数。但是实际操作过程中,不同预测模型的性能相差不多,而前三步中的特征处理对最终系统的准确性有着十分关键的作用(数据预处理:文本分类中,去
除停用词等。,特征提取,特征转换)。
1.4 表示学习
1)为提高机器学习系统的准确率,需将输入信息转换为有效的特征(称为表示)。若有一种算法可以自动地学习出有效的特征,并提高模型性能,叫做表示学习。
1、语义鸿沟
1)语义鸿沟问题是指输入数据的底层特征和高层语义信息之间的不一致性和差异性。比如给定一些关于“车”的图片,但每辆车的颜色和形状等属性都不尽相同。
2)好的表示:同样大小的向量可以表示更多信息;使后续的学习任务变得简单;具有一般性(普适性)
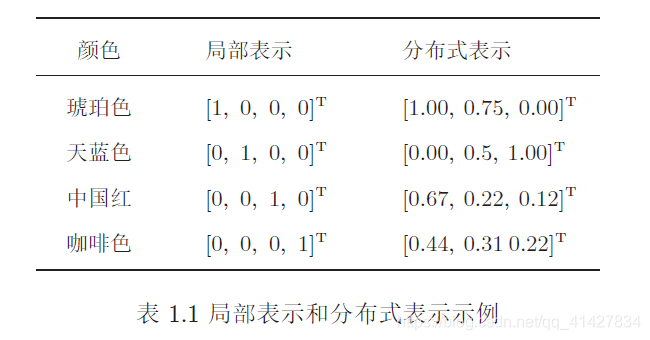
3)表示特征(两种),
《1.局部表示》以不同名字来命名不同的颜色,这种表示方式叫做局部表示,也称为离散表示或符号表示。局部表示通常可以 表示为one-hot (即使用一维数组中不同位置的1来代表值)向量的形式。
不足之处:(1)one-hot 向量的维数很高,且不能扩展。(2)不同颜色之间的相似度都为0,即我们无法知道“红色”和“中 国红”的相似度要比“红色”和“黑色”的相似度要高。
《2.局部表示》不同颜色对应到R、G、B三维空间中一个点,这种表示方式叫做分布式表示。
4)嵌入:通常指将一个度量空间中的一些对象映射到另一个低维的度量空间中,并尽可能保持不同对象之间的拓扑关系。比如自然语言中词的分布式表示,也经常叫做词嵌入。(PS:线性相关即其他向量可表示此向量,有一个多余向量。线性无关即三个三维向量可组合为整个三维空间,称此三个向量线性无关)
1.5 深度学习
1)深度学习是机器学习的一个子问题,其主要目的是从数据中自动学习到有效的特征表示;通过多层的特征转换(非线性变换???),把原始数据变成为更高层次、更抽象的表示。
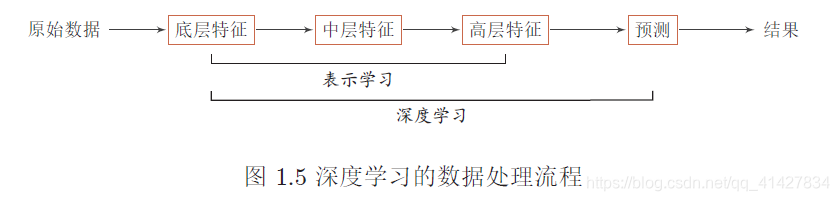
2)深度学习需要解决的关键问题是贡献度分配问题(类似神经网络中,权重分配问题)。主要采用的模型是神经网络模型,其可以使用误差反向传播算法,比较好地解决贡献度分配问题。只要是超过一层神经网络都会存在贡献度分配问题,因此超过一层的神经网络都可以看作是深度学习模型。随着模型深度的不断增加,其特征表示的能力也越来越强,从而使后续的预测更加容易。
3)目前,大部分采用神经网络模型的深度学习也可以看作是一种端到端的学习。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









