







github地址:https://github.com/wty-ustc/HairCLIP

文章目录
1. 介绍
StyleCLIP缺点
- 对于每一个特定的毛发编辑描述,都需要训练一个单独的映射器,这在实际应用中是不灵活的
- 由于缺乏量身定做的网络结构和损耗设计,使得该方法对发型、发色等无关属性的解密效果较差
- 在实际应用中,一些发型或颜色难以用文字描述。此时,用户可能更喜欢使用参考图像,但StyleCLIP不支持基于参考图像的头发编辑。
HairCLIP新设计
- 共享条件嵌入。 为了将文本和图像条件统一到同一个域中,我们利用 CLIP 的文本编码器和图像编码器来分别提取它们的嵌入作为映射器网络的条件。
- 解耦信息注入。 我们明确地分离发型和头发颜色信息,并将它们输入到与其语义级别相对应的不同子头发映射器中。 这有助于我们的方法实现解开的头发编辑。
- 调制模块。 我们设计了一个条件调制模块来完成对潜在代码输入条件的直接控制,从而提高了我们方法的操作能力。
三种损失类型
- 使用文本操作损失来保证编辑结果与给定文本描述之间的相似性。
- 图像操作丢失用于引导发型或发色从参考图像转移到目标图像。
- 属性保存丢失用于在编辑前后保持不相关属性(如身份、背景等)不变。
贡献
- 我们推动了交互式头发编辑的前沿,即在一个框架内统一文本和参考图像条件。它在一个模型中支持广泛的文本和图像条件,而无需训练许多独立的模型,这是以前从未实现过的。
- 为了以一种解开的方式执行各种发型和头发颜色操作,我们提出了一些新的网络结构设计和为我们的任务量身定制的损失函数。
- 进行了广泛的实验和分析,以显示我们的方法更好的操作质量和每个新设计的必要性。
2. 相关工作
- GAN
- 基于图像的头发处理
- 基于文本的头发操控
与现有作品不同,本文提出了第一个同时实现文本和图像条件的统一框架。这提供了一种更直观,更方便的交互模式,并在单个模型中实现了多种文本和图像条件。此外,受益于为此任务量身定制的新设计,我们的方法还显示出更好的头发处理质量
3. 具体方法
3.1 回顾基础
- StyleGAN
- CLIP
3.2 HairCLIP
首先使用 StyleGAN 反演方法“e4e” 得到其在 W+ 空间中的潜在代码 w,然后使用映射器网络根据 w 预测潜在代码变化 Δw 和编辑条件(包括发型条件es和头发颜色条件ec)。 最后,将修改后的潜码 w = w + Δw 反馈到预训练的 StyleGAN 中,得到目标编辑结果。

共享条件嵌入。为了在一个框架下统一文本和图像域的条件,我们自然选择通过将它们嵌入到 CLIP 的联合潜在空间中来表示它们。对于用户提供的文本发型提示和文本头发颜色提示,我们使用 CLIP 的文本编码器将它们编码为 512 维条件嵌入,分别表示为 et s 和 et c。类似地,发型参考图像和头发颜色参考图像由 CLIP 的图像编码器编码,分别表示为 eIr s 和 eIr c。由于 CLIP 在大规模图像-文本对上训练有素,et s, et c, eIrs , eIr c 都驻留在共享的潜在空间中,因此可以馈送到一个映射器网络并灵活切换。
解耦信息注入。正如许多作品 [23, 48] 所展示的,StyleGAN 的不同层对应于生成图像中不同语义级别的信息,而前面的层越多对应于更高语义级别的信息。遵循 StyleCLIP [31],我们采用三个具有相同网络结构的子头发映射器 Mc、Mm、Mf,它们负责预测潜在代码 w 的不同部分(粗、中、细)对应的头发编辑的 Δw = (wc, wm, wf)。更具体地说,wc、wm、wf分别对应于高语义层次、中等语义层次和低语义层次。
注意到 StyleGAN 中的这种语义分层现象,我们提出了解耦信息注入,旨在提高网络对发型和头发颜色编辑的解耦能力。 具体来说,我们使用来自 CLIP 的风格信息 es ∈ {et s, eIr s } 作为 Mc 和 Mm 的条件输入,并使用来自 CLIP 的头发颜色信息 ec ∈ {et c, eIr c } 作为 Mf 的条件输入 . 这是基于经验观察,发型通常对应于 StyleGAN 中的中高级语义信息,而头发颜色对应于低级语义信息。 因此,头发映射器 M 可以表示为:
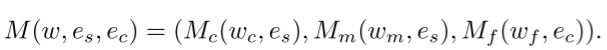
如图2所示,每个sub hair mapper网络遵循简单的设计,由5个block组成,每个block由一个全连接(fc)层、一个新设计的调制模块和一个非线性激活层(leakly relu )。 调制模块不是简单地将条件嵌入与输入潜在代码连接起来,而是使用条件嵌入 e 来调制前面 fc 层的中间输出 x。 在数学上,它遵循以下公式:
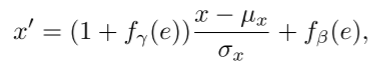
3.3 损失函数
基于条件输入以解耦的方式处理头发,同时需要保留其他不相关的属性(例如,背景、身份)。因此,我们专门设计了三种类型的损失函数来训练映射器网络:文本操作损失、图像操作损失和属性保存损失。
为了根据发型或颜色的文字提示进行相应的头发操作,我们在CLIP的帮助下设计了文字操作损失Lt如下:
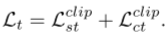
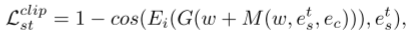
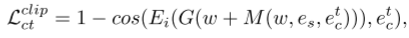
图像处理损失。 给定参考图像,我们希望处理后的图像具有与参考图像相同的发型。 然而,表征两种发型之间的相似性是一项具有挑战性的任务。 再次利用 CLIP 的强大潜力,我们使用 CLIP 的图像编码器分别对它们进行编码,以测量它们在 CLIP 潜在空间中的相似性:
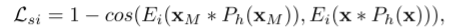
P表示预训练的面部解析网络,Ph(xM)表示xM的头发区域的掩码,x表示给定的参考图像。
属性保留损失。 为了确保头发编辑前后的身份一致性,身份损失应用如下:
R 是用于人脸识别的预训练 ArcFace网络,G(w) 表示重建的真实图像。
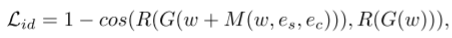
















 2836
2836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











