






FedSeq: A Hybrid Federated Learning Framework Based on Sequential In-Cluster Training 一种基于序列簇内训练的混合联邦学习框架
Abstract
本文提出:一种基于用户聚类和序列簇内训练的混合FL框架FedSeq,以提高通信效率和测试精度,特别是对非iid数据的测试。
FedSeq: 将用户划分为多个集群,每个集群上选择一个簇头 CH,将模型更新上传到PS,降低上行通信开销。每个聚类中,设计了一个序列训练方法,使CHs模型在每个训练周期中经历很多的训练数类别和元更新,从而提高测试的准确性。
将 FedSeq 与 FedSGD, FedA VG, FedProx, FedCluster和HierFAVG 进行比较,模型精度和训练效率都更好。
1.INTRODUCTION
FL的通信开销问题:
- 减小模型更新: ① 结构化更新和草图更新;② 压缩模拟分布随机梯度下降(CA-DSGD)的模型通信方案将梯度压缩为有限位数;③ 基于核心集的FL探索内在冗余模型参数,动态的从模型中砂很难出最不重要的连接; ④ FedKD在服务器和客户端之间共享一个小型mentee模型,而不是通过相互知识蒸馏方法直接通信大型模型。
- 降低通信频率: ① 客户端-边缘服务器-云FL
当前研究的不足:
非独立同分布数据: 数据增强;多任务学习;迁移学习;
根据全局数据分布增加训练数据来解决类不平衡问题;
在服务器收集愿意共享的用户数据,将这些数据生成的模型更新与 non-iid数据的模型更新聚合;
MOCHA: 基于MTL方法允许每个用户学习一个单独的模型,进行聚合;
联邦迁移学习(FTL):从源域数据的模型高精度的应用于另一个不同但相关的目标域数据。
基于差异加权的联邦平均FTL框架。
不足: 数据增强需要收集训练样本来构建辅助数据集,违反隐私保护;MTL计算量大。
本文贡献:
一个基于用户聚类和序列簇内训练方法的混合FL框架,称为FedSeq,以减少上行通信开销,提高模型的精度,特别是在非iid数据上。
两个主要阶段:簇内训练和模型聚合
每个集群内的客户端在训练过程中与相邻客户端交换模型,在簇头上生成的模型见证了更多类别的训练数据,并在每个训练周期内经历更多元更新,提高准确性。
集群内训练完毕后选择一个CH的更新上传到PS。降低开销
采用随机聚类策略提供FedSeq对IID数据的收敛性分析。
使用随机和低能量自适应聚类层次策略(LEACH)测试FedSeq,展示对不同聚类策略的鲁棒性。

2.RELATED WORK
用户聚类:
-
联邦多任务学习(FMTL)框架:聚类CFL
根据FL损失的余弦相似度,将用户分为多个具有联合可训练数据分布的组。 -
统计模型:
带 l 2 l_2 l2距离的Lloyd算法对用户数据进行分组 -
层次聚类根据用户本地更新与全局模型的相似性对用户进行分组。
-
通信感知CFL:
基于多源自适应方法,服务器在为每个集群学习更准确的模型和加强其将这些模型聚合为全局模型的能力之间进行平衡 -
ClusterFL:
减小学习模型的经验损失,捕捉不同用户数据间的聚类结构,剔除收敛慢,与其他用户相关性小的用户。 高精度 低开销 -
**IFCA:基于CFL的高效迭代联邦聚类算法:**该框架交替估计用户的聚类身份,并通过梯度下降优化用户聚类的模型参数。属于同一聚类的客户端为其聚类训练单个模型。
本文前期工作 (Semi-FL) 主张将用户划分为多个簇以达到模型精度。
- 采用更多聚类方法,包括 Random和LEACH策略。
- 对IID数据随机用户 聚类的解决方案进行分析
- 和 有用户聚类FedSGD, FedAVG和FedProx ;没有用户聚类FedCluster和HierFAVG的方案进行比较。
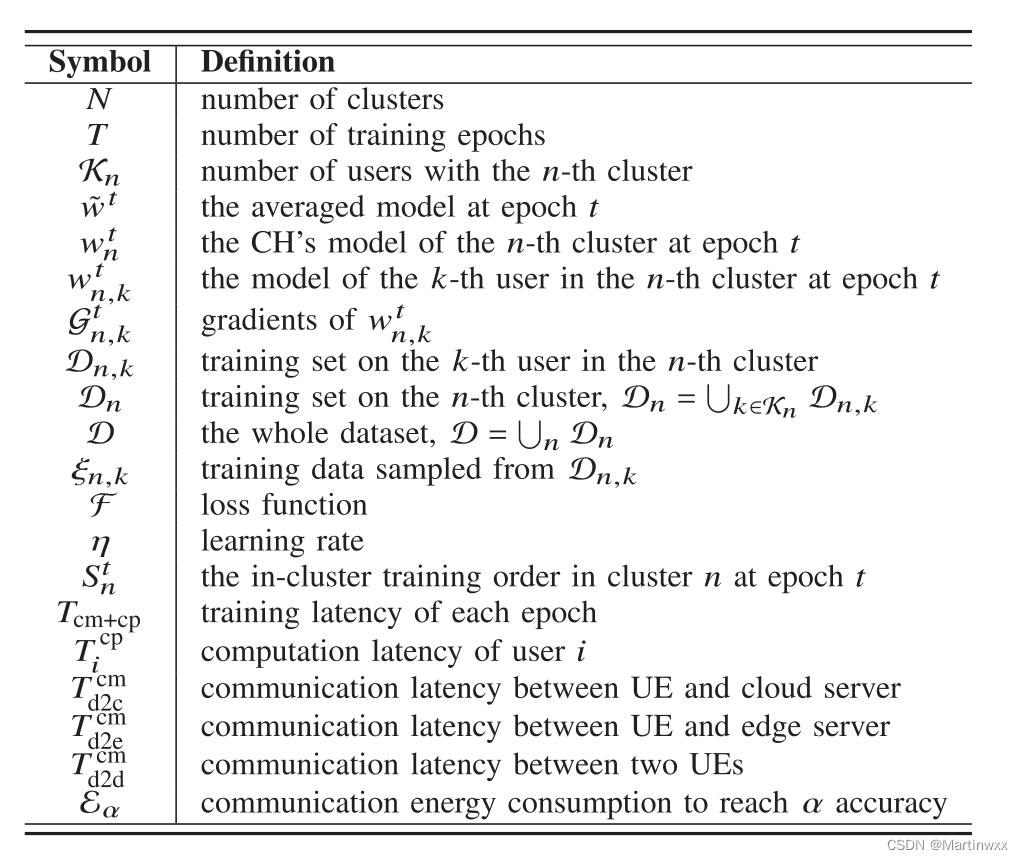
2.METHODS















 1312
1312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









