






Towards Byzantine-resilient Learning in Decentralized Systems
去中心化系统中的拜占庭弹性学习
Abstract
消除 集中式参数服务器(PS)可以有效解决隐私、性能瓶颈和单点故障等问题。
本文:基于拜占庭容错的去中心化学习算法UBAR为良性节点提供一个统一的拜占庭弹性聚合规则,用于在每次训练迭代中选择有用的参数更新并过滤掉恶意的参数更新。
一、INTRODUCTION
联邦学习缺陷:
- 单点故障,中心服务器崩溃造成整个系统崩溃。
- 集中式参数服务器成为性能瓶颈。
去中心化可以展现DL应用的巨大潜力。
分布式学习场景中拜占庭将军问题原因:
- 不可靠边缘设备发送到参数影响全局模型。
- 物联网设备和网络复杂且易受攻击。
- 袭击后果严重,拜占庭攻击改变训练过程影响最终模型。
基于PS的系统拜占庭弹性方法用于分散式学习有难度:
- 易受到精心设计的拜占庭攻击,计算开销大,不切实际的需求的可伸缩性问题(额外要求验证数据集)
- 联邦学习的每个节点都是一个PS,结构有差异,无法直接应用。
UBAR两个阶段
1. 列出一组候选节点:
每个良性节点根据其参数与自身参数的距离选择一些潜在良性节点。
2. 用于选择最终参数
每个良性节点使用其训练样本从第一阶段开始测试参数的性能,选择训练质量最好的参数。
UBAR用分布式学习特点解决局限性
每个节点既是 worker 又是PS,在基于PS的系统中,使用自己的参数作为baseline (阶段一),而不是邻居节点的平均值或中值,有效保证 baseline 不被操控,每个节点还可以评估其训练样本质量(阶段二)。
UBAR还提升了 8-30X性能
二、BACKGROUND AND RELATED WORK
A. Byzantine-resilient Centralized Learning
- 对上传的梯度进行聚类,
基于矢量距离检测异常值。比如:Krum,中值,Bulyan。
-
在额外的验证数据集上评估每个上传的梯度。
比如:Zeno(同步学习)、Zeno++(异步学习)。 要求PS有验证数据集,这种要求不切实际,评估梯度性能的计算开销很大。 -
根据历史记录选择良性梯度和节点。
比如:隐藏马尔可夫模型(学习分布式训练中参数更新的质量)、利用与worker历史交互作为经验,通过强化学习识别拜占庭攻击
脆弱性:攻击者最开始假装良性,最后几次迭代上传恶意参数,学习到的文件就无法预测未来迭代中的恶意行为。
B. Byzantine-resilient Decentralized Learning
去中心化的分布式学习,每次迭代中:
- 每个worker向相邻节点广播参数向量,接收邻居节点的估计值
- 利用本地数据训练模型
- 与邻居节点的估计进行聚合,更新模型
拜占庭弹性分布式学习研究处于初级阶段。
拜占庭弹性去中心化:
- ByRDie:将修剪中值算法应用于坐标下降优化算法
- BRIDGE :将修剪中值算法应用于带有SGD的分布式学习
- RD-SVM:比较邻居节点的损失识别过滤拜占庭节点。使用铰损法,每次迭代所有数据都要检测,适用于线性分类器
本文主要研究主流SGD算法和批量训练特征的DL模型。
三、 SYSTEM MODEL OF DECENTRALIZED LEARNING
略
四、BYZANTINE ATTACK IN DECENTRALIZED LEARNING
从理论上论证了分散学习系统中拜占庭攻击的可行性和严重性
五、BYZANTINE-RESILIENT SOLUTION
A. Byzantine-resilient Aggregation Rule
该规则应保证所有良性节点收敛到没有拜占庭节点学习的最优估计
B. UBAR
三个问题:
- 集中式系统的拜占庭问题解决方案套用到分布式系统中仍然有缺陷。
- 分布式系统对收敛要求更高,服务器收敛不代表所有良性节点收敛。
- 分布式系统中的拜占庭节点数量不定,而集中式系统假定攻击者数量固定。
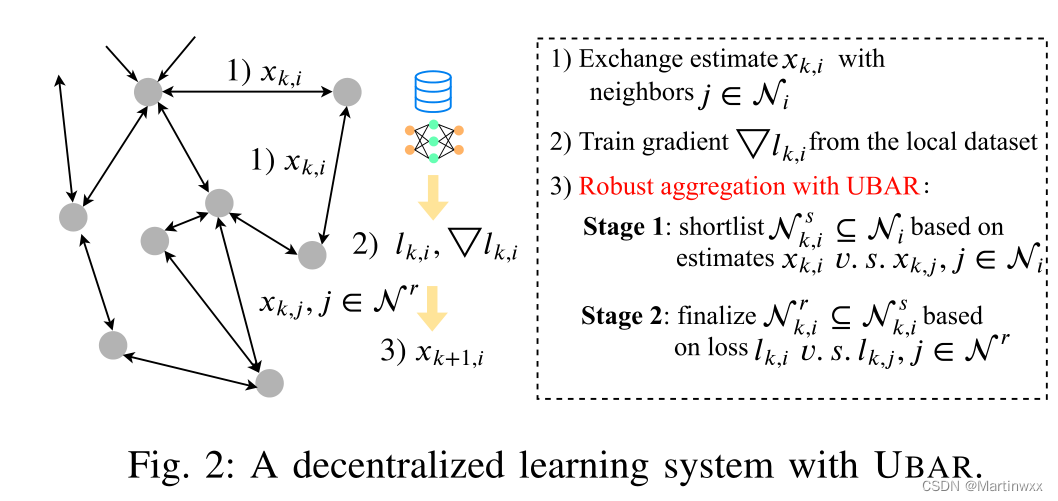
如图,UBAR两个阶段:
1. 第一阶段
每个良性节点从他的邻居中选择一个潜在良性节点的候选池。
比较每个相邻节点与自身估计值之间的欧氏距离,进行选择。
2. 第二阶段
每个良性节点进一步从候选池中选择最终节点进行估计更新。
重用训练样本作为验证集,评估邻居节点的性能 (损失函数) ,选择损失值小于其自身估计的估计值,取平均值作为最终更新值。
x
k
,
i
x_{k,i}
xk,i 是节点
i
i
i 在第
k
k
k 次迭代处的估计,
l
k
,
i
l_{k,i}
lk,i 是随机选择的数据样本上的估计值的损失,
ρ
i
\rho_i
ρi 是节点
i
i
i 的良性邻居的比率,
l
k
,
i
=
l
(
x
k
,
i
,
ξ
k
,
i
)
l_{k,i} = l(x_{k,i},\xi_{k,i})
lk,i=l(xk,i,ξk,i)
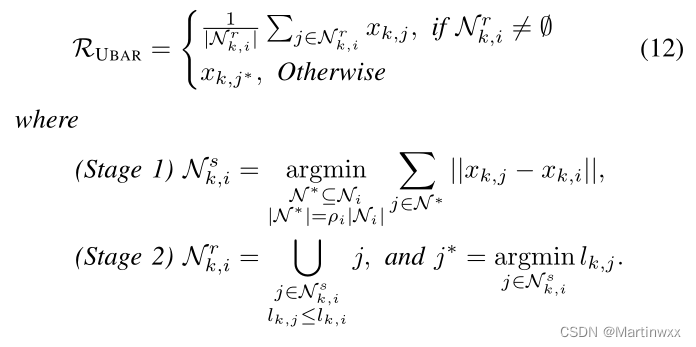
估计值从
x
0
,
i
=
x
0
x_{0,i} = x_0
x0,i=x0 开始,在第
k
k
k 次迭代中,节点
i
i
i 向其邻居广播估计值,邻居接受,随机选择训练数据样本
ξ
k
,
i
\xi_{k,i}
ξk,i 并计算损失和梯度(3-4行),而后进行两个阶段的估计值选择。
- 首先计算 x k , i x_{k,i} xk,i 和邻居 估计值 之间的欧几里得距离,并选择距离最小的 ρ i ∣ N i ∣ \rho_i| \mathcal{N}_i| ρi∣Ni∣ 邻居(5-7行)
- 对每个估计值 x k , j , j ∈ N k , i s x_{k,j},j \in \mathcal{N}_{k,i}^s xk,j,j∈Nk,is 节点 i i i 计算 x k , j x_{k,j} xk,j 在 ξ k , i \xi_{k,i} ξk,i 上的损失,选择与 x k , i x_{k,i} xk,i 性能相似或者更好的的估计值(8-14行)
- 计算选定节点的平均值,使用GUF更新最终估计值(15-16行)

C. Complexity Analysis
与现有聚合规则比,复杂度低,效率高
六、EXPERIMENTS
A. Experimental Setup and Configurations
-
Datasets.
MNIST 、CIFAR10
训练卷积神经网络CNN,两个最大池化层,三个完全连接层。
batch size 256
衰减学习率 λ ( k ) = λ 0 20 20 + k \lambda(k) = \lambda_0 \frac{20} {20+k} λ(k)=λ020+k20
epochs: k k k
初始学习率: λ 0 = 0.05 \lambda_0 = 0.05 λ0=0.05 -
Implementation of decentralized systems.
节点 i i i 的拜占庭节点比小于 1 − ρ i 1-\rho_i 1−ρi
良性节点的 ρ i = 0.4 \rho_i = 0.4 ρi=0.4 -
Baselines
考虑了三种拜占庭弹性解决方案,Krum、边际中值、Bulyan
中心化分布式系统中通常假设最大拜占庭攻击数量,在去中心化分布式系统中不成立,因为每个良性节点的拜占庭节点数量是变化的。
n ^ i \hat{n}_i n^i 是节点 i i i 的拜占庭节点数
ρ c e n t r a l \rho_{central} ρcentral 是集中分布式防御中允许的最大拜占庭节点比
⌈ ⋅ ⌉ \lceil \cdot \rceil ⌈⋅⌉ 是ceil函数
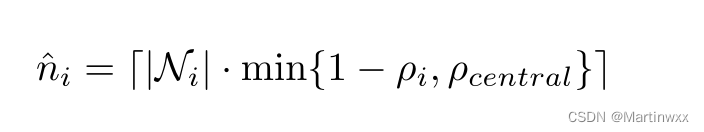
-
DKrum.
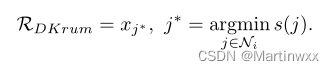
-
Dmedian.
用接收到的估计值替换梯度。
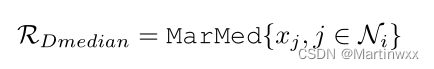
-
DBulyan.
迭代使用DKrum.
还实现BRIDEGE进行比,令GUF中的 α = 0.5 \alpha = 0.5 α=0.5,考虑没有拜占庭节点的分散式系统,使用平均聚合规则。视为最优模型 -
Performance Metric.
测量训练好的模型在每个良性节点上的进度,报告所有节点中最差的精度代表防御有效性。
B. Convergence
作为聚合规则,基本功能是实现一致收敛,每个良性节点中的模型必须收敛到正确的节点。
-
Network size.
节点设置为30 40 50
DBulyan和UBAR在MNIST和CIFAR10上具有与baseline相同的收敛性。
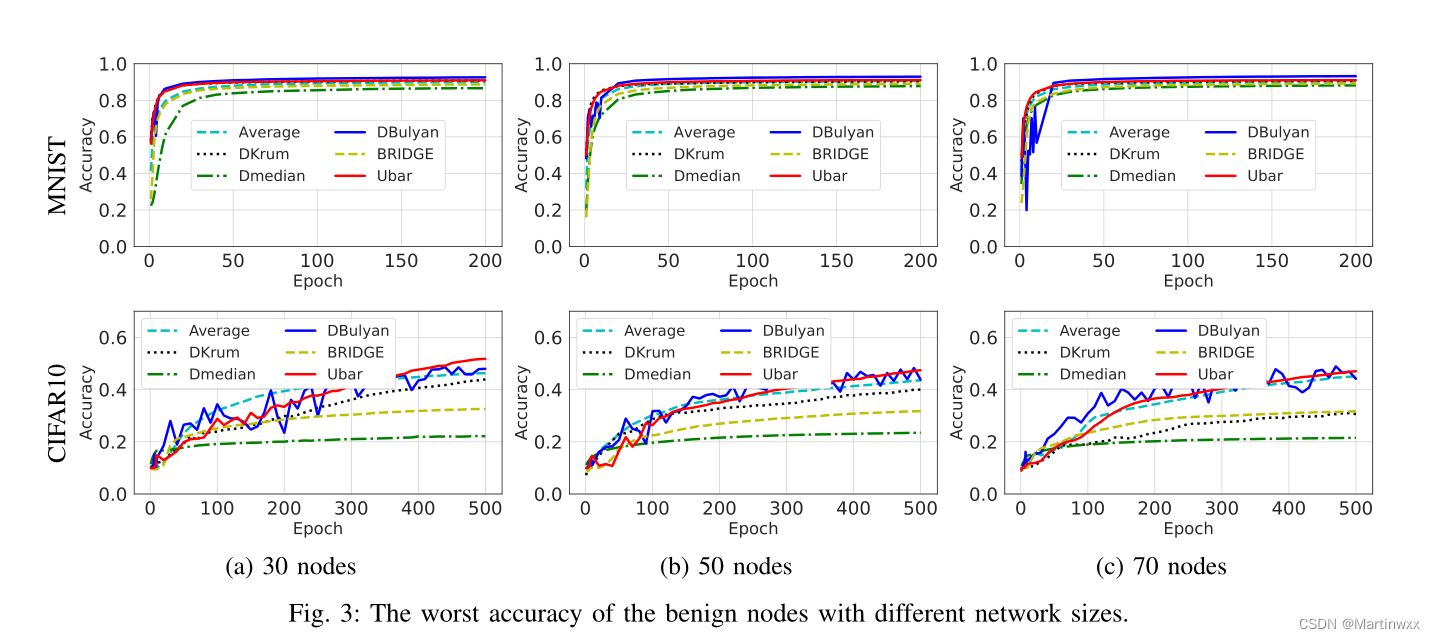
-
Network connection ratio.
节点数30
连接比 0.2 0.4 0.6
连接较重时,需要花费更多的开销以达成共识。
连接比0.6,UBAR有更好的收敛性能。
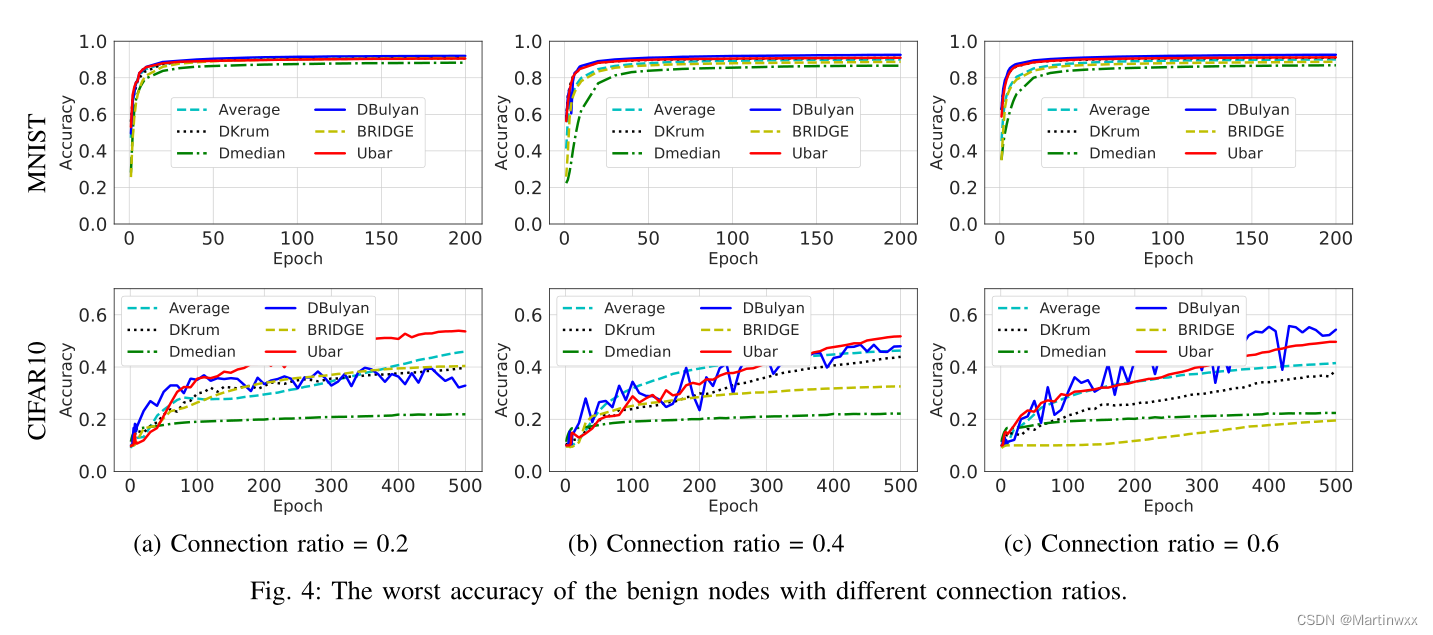
C. Byzantine Fault Tolerance
不同防御策略在各种拜占庭攻击下的性能。
良性节点数30 ,连接比0.4
不同拜占庭比率:0.1,0.3,0.5
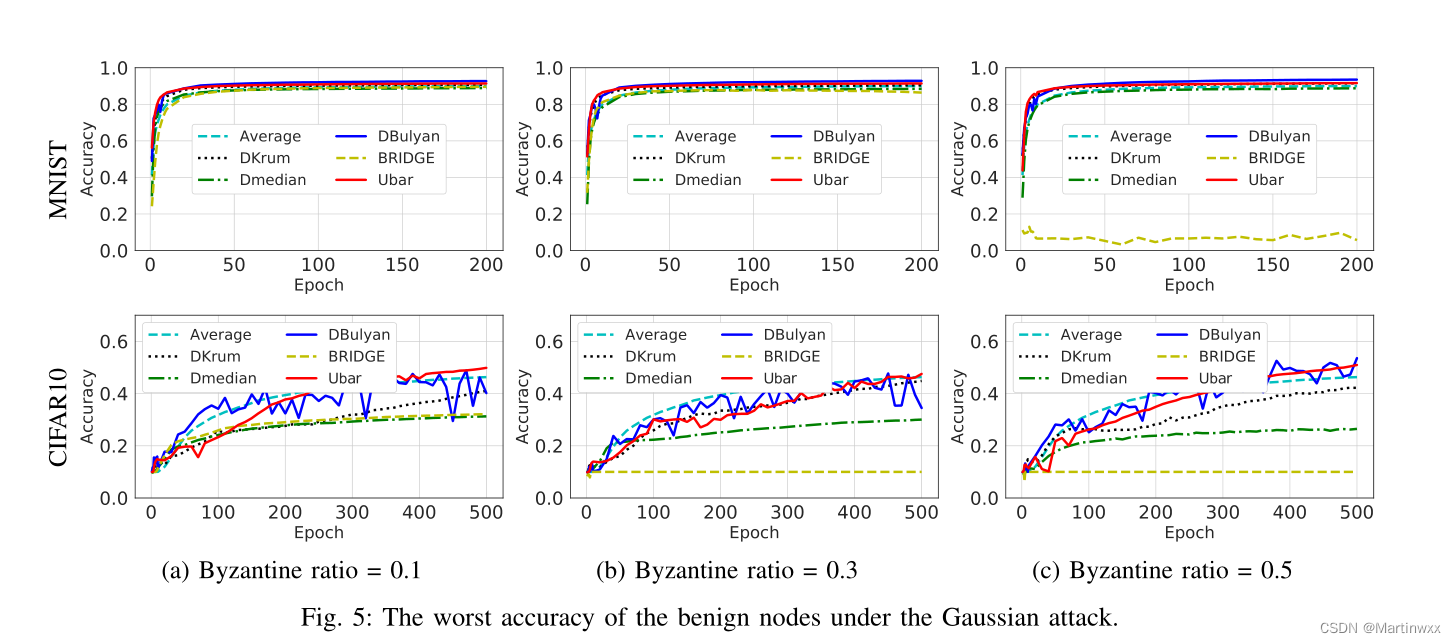
- Guassian attack.
每次迭代恶意节点向邻居广播遵循高斯分布的随机估计向量。
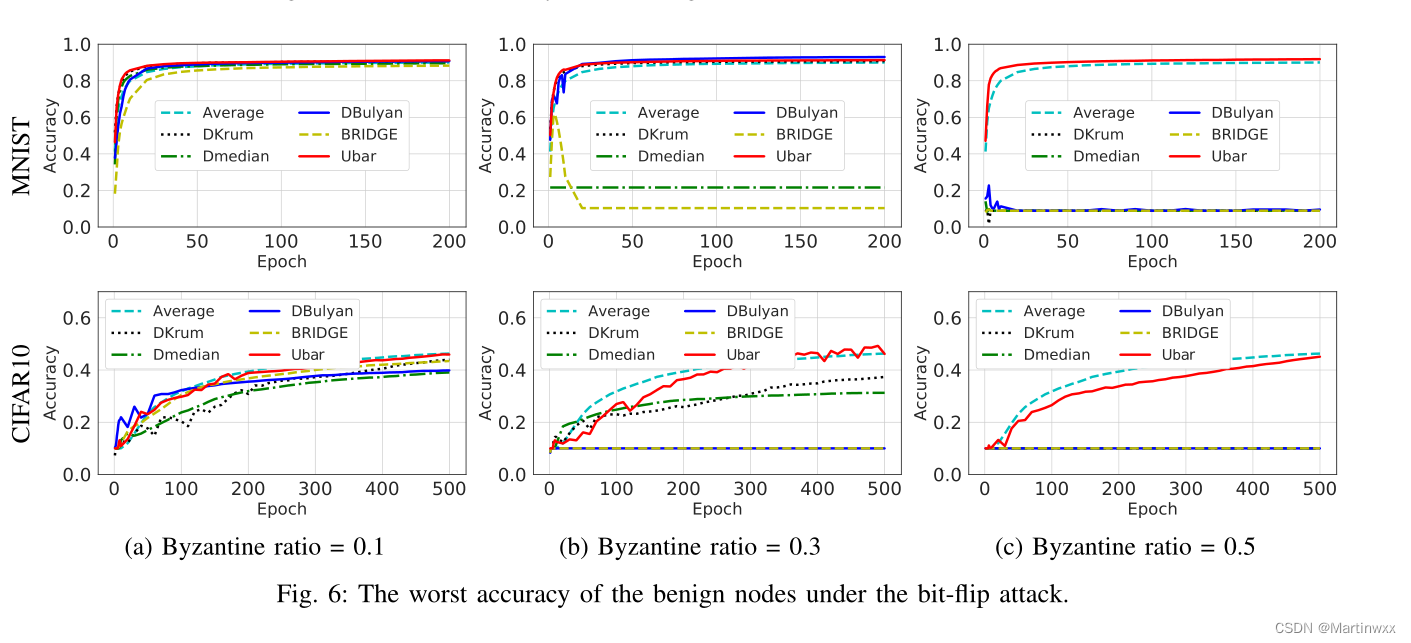
- Bit-flip attack.
恶意节点向邻居广播翻转符号的向量
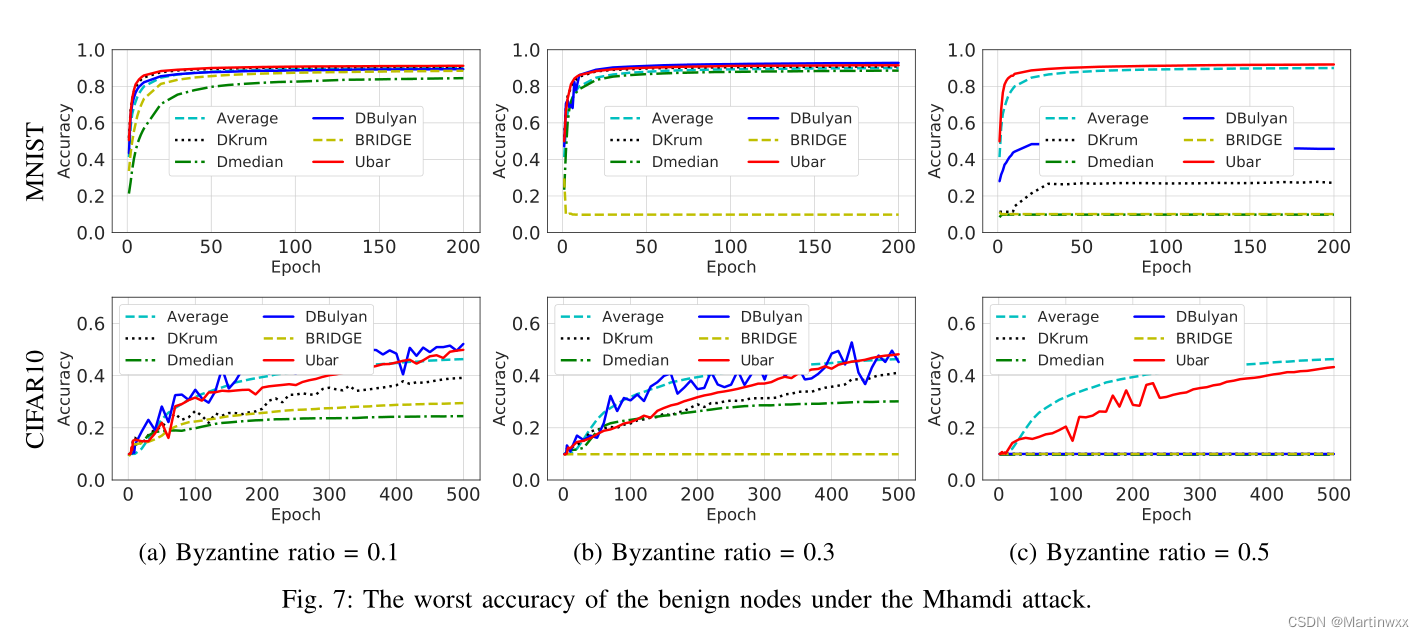
- Sophisticated attack.
对手有能力从其他邻居节点收集所有上传的估计。然后,它可以仔细设计自己的估计,使其不被良性的估计检测到,同时仍然影响训练过程。
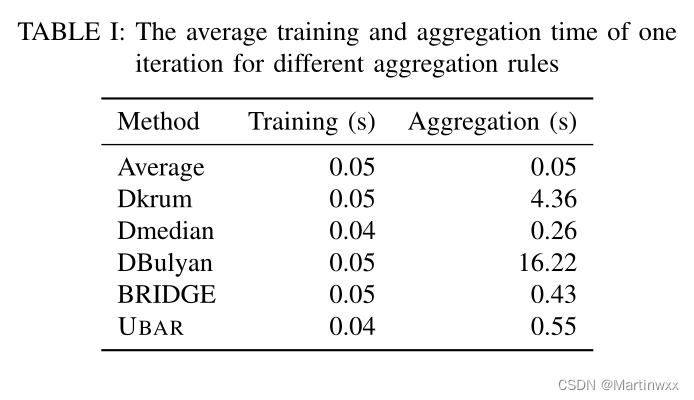
D. Computation Cost
UBAR比DKrum快8倍,比DBulyan快30倍
收敛性比Dmedian和BRIDGE强。
故,UBAR是拜占庭弹性最强,计算开销可接受的最优解。
七、DISCUSSION
- Ratio of Benign Neighbors.
每个良性节点需要预设邻居良性节点比例。 - Non-IID Scenario.
非同构场景是以后研究方向。
八、CONCLUSION
在不同的系统配置下,UBAR能够以较低的计算开销抵抗简单和复杂的拜占庭攻击















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









