






Clustered Federated Learning via Inference Similarity for Non-IID Data Distribution 基于推理相似性的非iid数据分布聚类联邦学习
Abstract
当局部数据集的分布与全局数据集的分布差异过大,客户端局部目标与全局目标不一致,导致局部更新漂移。
本文提出:
算法FLIS,利用客户端模型的推理相似性,将客户端分组为具有联合可训练数据分布的聚类。
不同的客户端有自己的学习任务,将他们的数据与同一集群中的其他用户(相同学习任务)聚合,可以更有效与个性化的联邦学习。
1.INTRODUCTION
通过聚类实现数据异构下的个性化FL。
基于FL损失面的几何属性或基于模型的权重或服务器端的模型更新比较,CFL通过将客户端分组到单独的集群来解决该问题。
当前研究的不足:
当每个参与者拥有不同分布不同数量的数据,且数据对其他人来说是黑盒的情况下,如何从FL中收益最大化。
本文贡献:
目标:
将具有相似数据分布的客户端分组在一个集群中,不访问私有数据,为每个集群训练模型。
主要思想:估计聚类标识和最大化服务器端推理相似性之间交替的策略。
- 推理相似性的想法:服务器识别具有相似数据分布的客户端集群ID的方法
- 可以构成联合和不联合的聚类,并且不需要先验地知道聚类的数量。对非IID和IID制度都有效
2.FEDERATED LEARNING WITH CLUSTERING
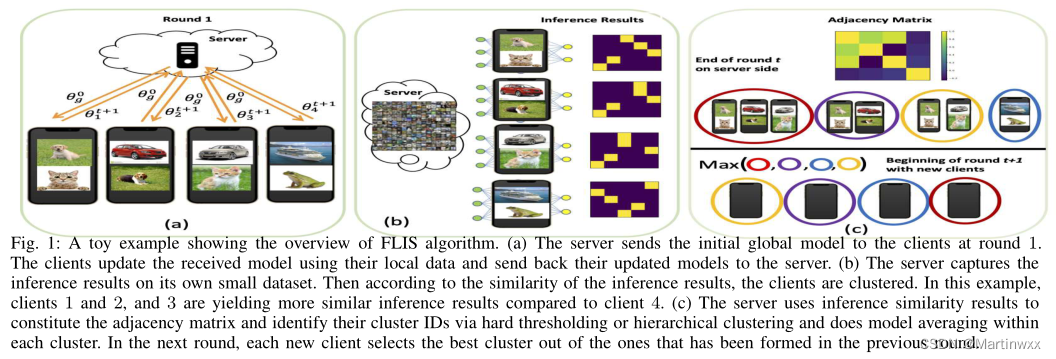
A. Overview of FLIS Algorithm
FLIS既能形成具有软成员ID的联合动态集群(DC),也能形成具有硬成员ID的不联合层次结构集群(HC)。


局部目标
L
k
L_k
Lk 由局部数据的经验损失定义。每个客户端再起测试数据上产生最小损失的模型参数来估计其集群身份。
然后客户端执行 SGD 更新 T T T 步,将更新后的模型参数发送给服务器。
服务器接收所有参数后,利用推理相似性作为形成动态的一种方式形成 具有相似数据分布 的客户端集群。从同一集群中的客户端收集所有参数,对每个集群模型参数求平均。
B. Clustering Clients
算法3中 介绍了 硬ID 形成不相交簇的概述。
目标是在不需要任何关于数据分布的先验知识的情况下,找到具有相似数据分布的客户端
假设服务器本身有一些真实或合成的数据,服务器对每个客户端模型进行推理,并获取一个
M
~
×
N
~
\tilde M\times \tilde N
M~×N~ 矩阵。
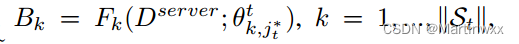
M
~
\tilde M
M~为最后一个全连接层(分类层)的最后一个神经元数,
N
~
\tilde N
N~ 服务器上的数据数
B
k
B_k
Bk 是one-hot标签或者软标签
服务器使用
B
k
B_k
Bk 构造邻接矩阵
A
i
,
j
A_{i,j}
Ai,j
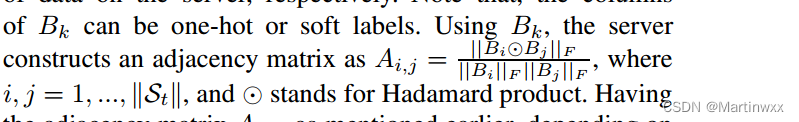
邻接矩阵
A
i
,
j
A_{i,j}
Ai,j 取决于形成联合聚类是 interset 还是 disjoint 的聚类。
两种不同聚类方法:
- interest聚类 FLIS(DC):定义一个硬阈值算子
Γ
\Gamma
Γ 应用于
A
i
,
j
A_{i,j}
Ai,j ,
A ~ i , j = Γ ( A i , j ) = S i g n ( A i , j − β ) \tilde A_{i,j} = \Gamma( A_{i,j}) = Sign( A_{i,j}-\beta) A~i,j=Γ(Ai,j)=Sign(Ai,j−β) , β \beta β 是阈值。
通过在 A ~ i , j \tilde A_{i,j} A~i,j 的每一行放入积极条目的索引,来进行interest簇的聚类。
FLIS(DC) 每一轮形成10个集群,等于每一轮参与的客户端数量。
- FLIS(HC):通过算法3 中所示的分层聚类对客户端进行分组。
FLIS(HC)形成的簇是固定的,依赖于HC的距离阈值,这个距离阈值是一个超参数。

3.EXPERIMENTS
A. Experimental Settings
Datasets and Models.
CIFAR10、SVHN和Fashion MNIST (FMNIST):使用Lenet-5 架构
CIFAR-100:使用Res-Net-9 架构
三种联邦异构设置:
非IID 标签倾斜:20%
非IID 标签倾斜:30%
非IID Dir :0.1
对比实验:
SOTA个性化FL:
LG-FedAvg 、 Per-FedAvg 、 IFCA 、 CFL
针对学习单个全局模型的方法:
FedAvg、 FedProx、FedNova、SCAFFOLD
Performance Comparison.
FLIS的两种聚类方案 DC HC 都表现优异
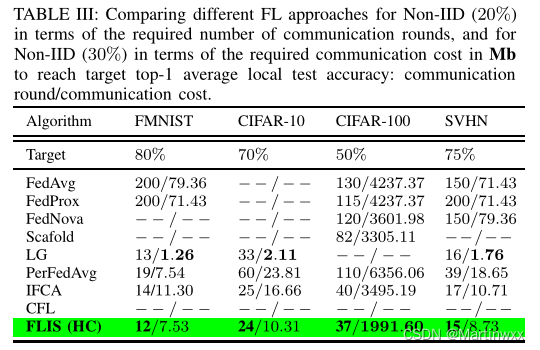
B. Communication Efficiency
-
- What is the Required Communication Cost/Round to Reach a Target Test Accuracy?:
FLIS 达到预定准确率所需的通信轮数最少 。
- What is the Required Communication Cost/Round to Reach a Target Test Accuracy?:
通过将具有相似数据分布的客户端分组在相同的集群中,设置倾向于模拟IID设置,这意味着在更少的通信周期中更快地收敛。
C. Impact of Hyper-parameter Changes
-
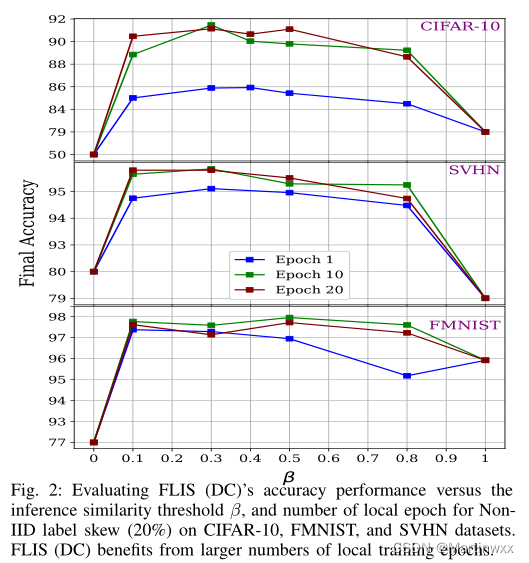
The influence of the inference similarity threshold β
CIFAR-10、SVHN和FMNIST的最佳性能分别在β = 0.3、β = 0.3和β = 0.5时实现。
-
Benefit of more local updates.
FLIS可以通过增加局部epoch进一步优化
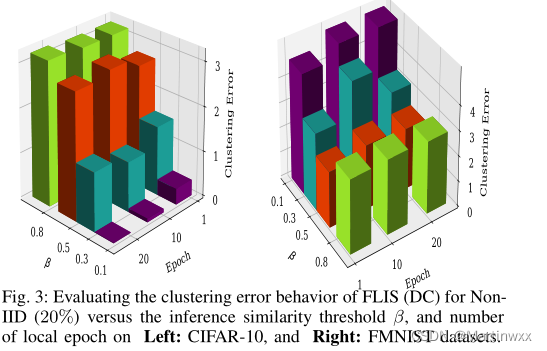
D. The influence of β on clustering error
对于CIFAR-10和FMNIST上的非iid(20%),最小的聚类误差出现在β = 0.1, β = 0.3和β = 0.5,这反映在较短的误差条上。
FLIS根据推理相似性/响应对客户端进行分组。这意味着FLIS从一组相似的客户机中选择一个最相似的客户机子集。这样一来,FLIS通过接受更多的FN(假阴性)来消除一些聚类误差,从而提高了聚类精度。
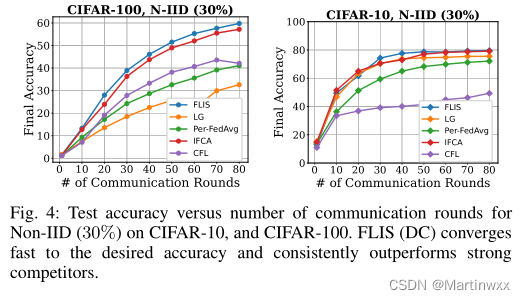
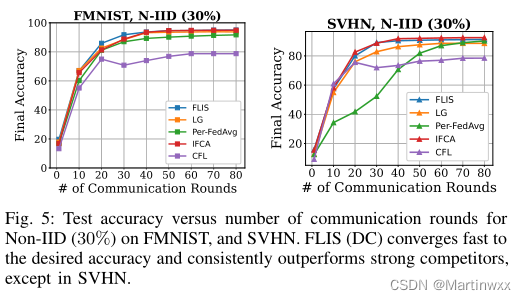
E. Learning with Limited Communication
为所有个性化基线分配有限的通信轮预算为80,并报告了图4和图5中所有客户端与非iid标签倾斜通信轮数(30%)的平均最终测试精度
FLIS只需要30个通信轮就可以在CIFAR-10、SVHN和FMNIST数据集中收敛。
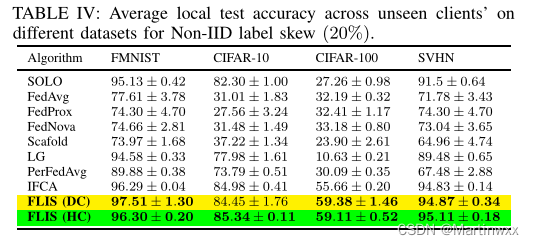
F . Generalization to Unseen Clients
目前还不清楚在联邦期间如何扩展其他个性化FL算法来处理不可见的客户端。
为了评估新客户个性化模型的性能,我们进行了一个实验,只有80%的客户参加了培训。余下20% 在最后加入,从服务器接受模型,并进行五次个性化处理。
新客户端的平均局部测试准确率如表IV所示。
表明FLIS允许训练过程中未见过的客户学习他们的个性化模型,并且具有较高的测试精度。















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









