







哈夫曼(Huffman)编码
假设给定 n 个权值{w1,w2,...,wn}作为二叉树的 n 个叶子结点,若二叉树的带权路径长度达到最小, 则称这样的二叉树为最优二叉树,也称为 Huffinan 树。构造一棵 Huffman 树算法如下:
1.1:构造一棵 Huffman 树
-
将{ w1,w2,...,wn}看成是有 n 棵树的森林(每棵树仅有一个结点)。
-
在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和。
-
从森林中删除选取的两棵树,并将新树加入森林。
-
重复2,3步,直到森林中只利一棵树为止,该树即为所求的Huffman树。
例子:
假设在 2022 年北京冬奥会前夕,从新华社抓取了若干条与冬奥会相关的文章,经统计,“我”、
“期待”、“观看”、“北京”、“冬奥”、“运动会”这六个词出现的次数分别为 15,8,6,5,3,1,请以这 6 个 词为叶子结点,以相应词频当权值,构造一棵 Huffman 树。
分析:词频越大的词离根结点 越近。在实际应用中,各个字符的出现频度或使用次数是不相同的,让使用频率高的用短码,使用频率低的用长码, 以优化整个报文编码。利用 Huffman 树设计的二进制前缀编码,称为 Huffman 编码。如图建构:
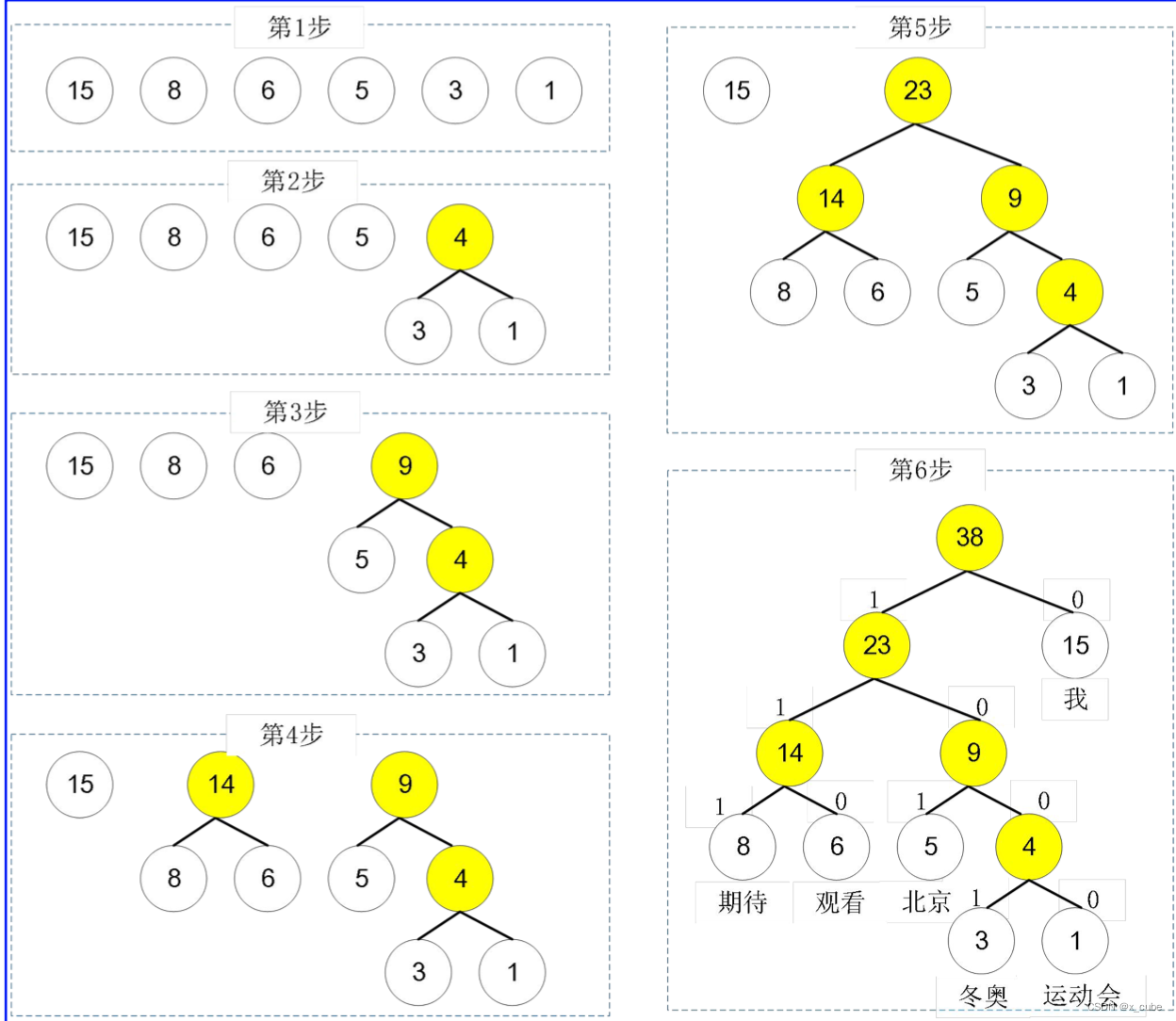
六个词的 Huffman 编码,其中约定(词频较大的)左孩子结点编码为 1, (词频较小的)右孩子编码为0。因此,“我”、“期待”、“观看”、“北京”、“冬奥”、“运动会”这六个词的 Huffman 编码分别为 0, 111, 110, 101, 1001 和 1000。
在word2vec的CBOW的输出层的应用



















 1064
1064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









