






克隆自己的声音并令其唱歌
准备工作
- 浏览器
- 声音文件,建议5分钟左右的清晰说话声音
- autodl 网站(https://www.autodl.com/console/instance/list)上充个两块钱
正式开始
-
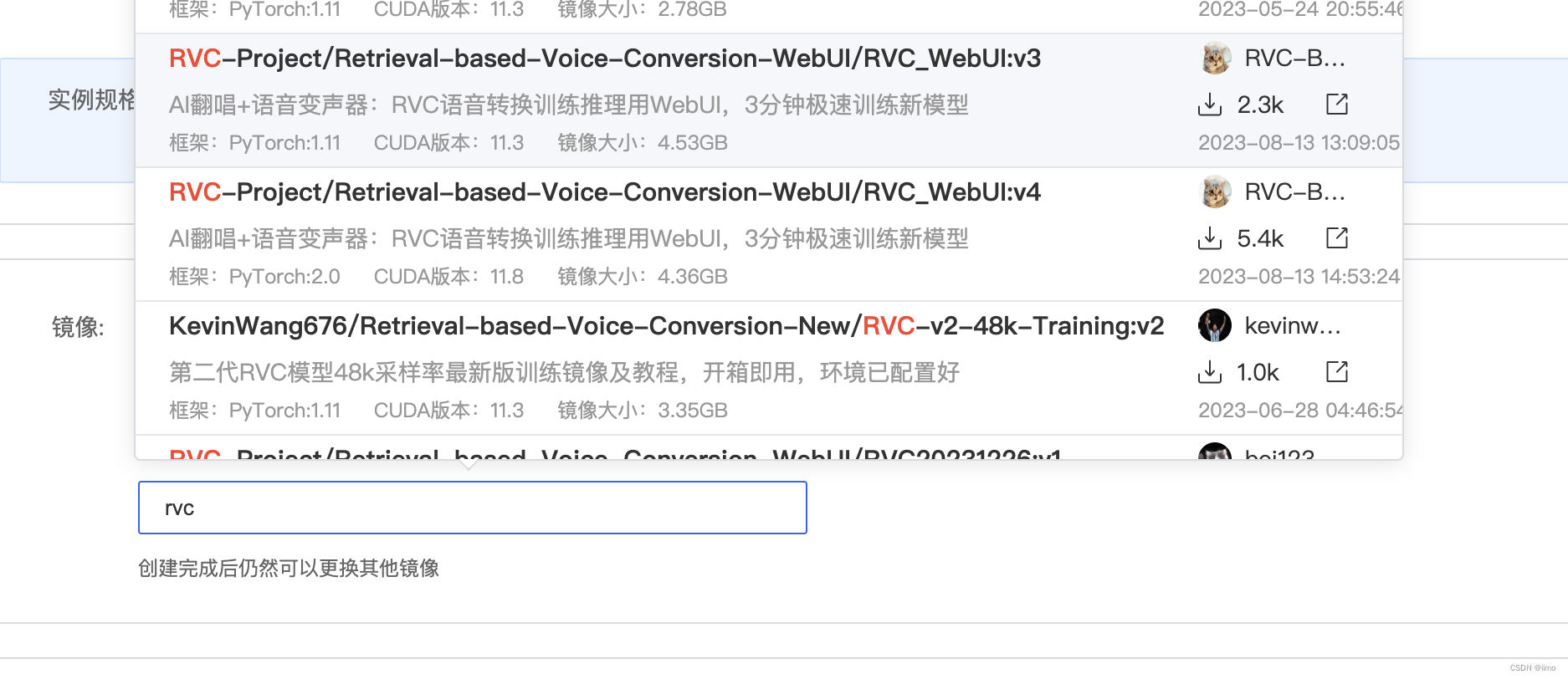
在autodl上租用实例,这里以3080ti为例,镜像在社区镜像中搜索rvc,选择v3版本即可
-
将镜像的详情页也打开,等会要用,也可以看看其介绍(https://www.codewithgpu.com/i/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/RVC_WebUI)
-
机器创建完成后可以看见实例列表,点autopanel上方的jupyterlab
-
再打开刚才的镜像详情页拷贝启动代码,看到端口号就是启动成功了
cd /root/Retrieval-based-Voice-Conversion-WebUI && python infer-web.py --port 6006
-
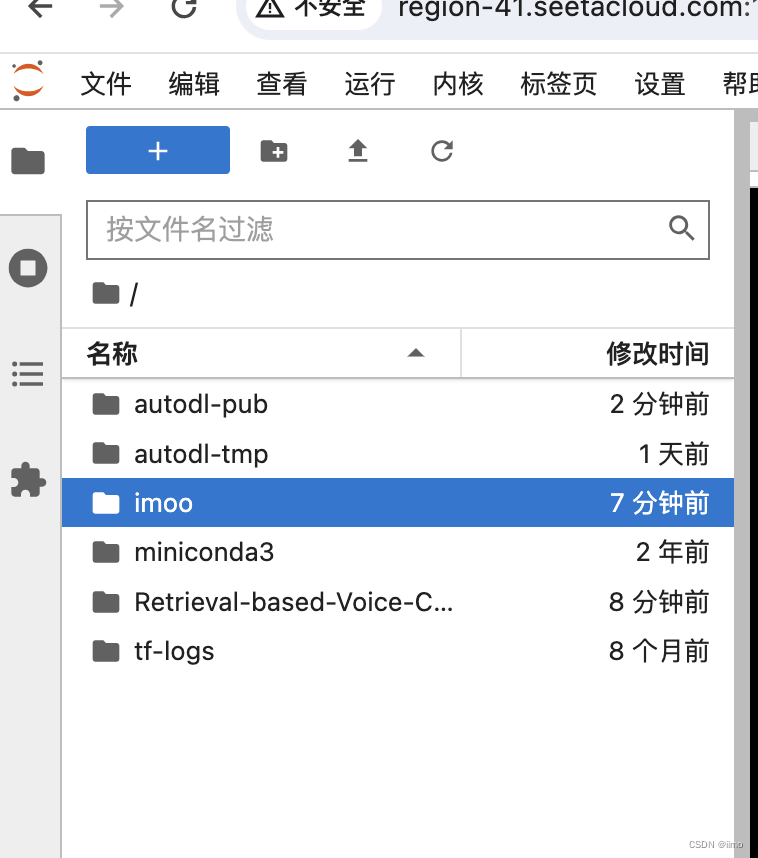
在左侧菜单树里新建一个文件夹,这里以新建/imoo文件夹为例,接着将你的声音文件放到这个文件夹下
-
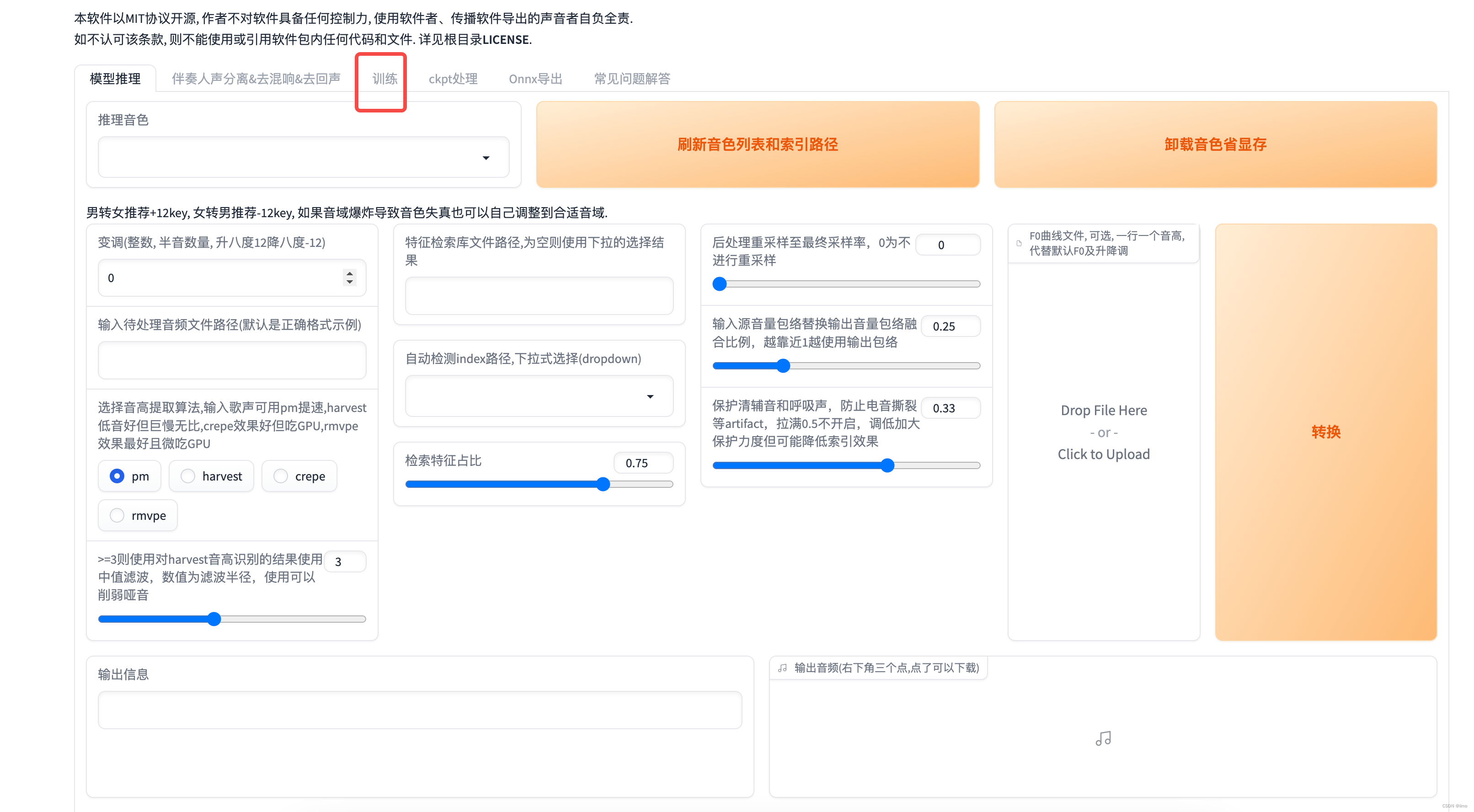
回到实例列表,点击jupyterlab的自定义服务
-
进入训练页面,填写必要信息
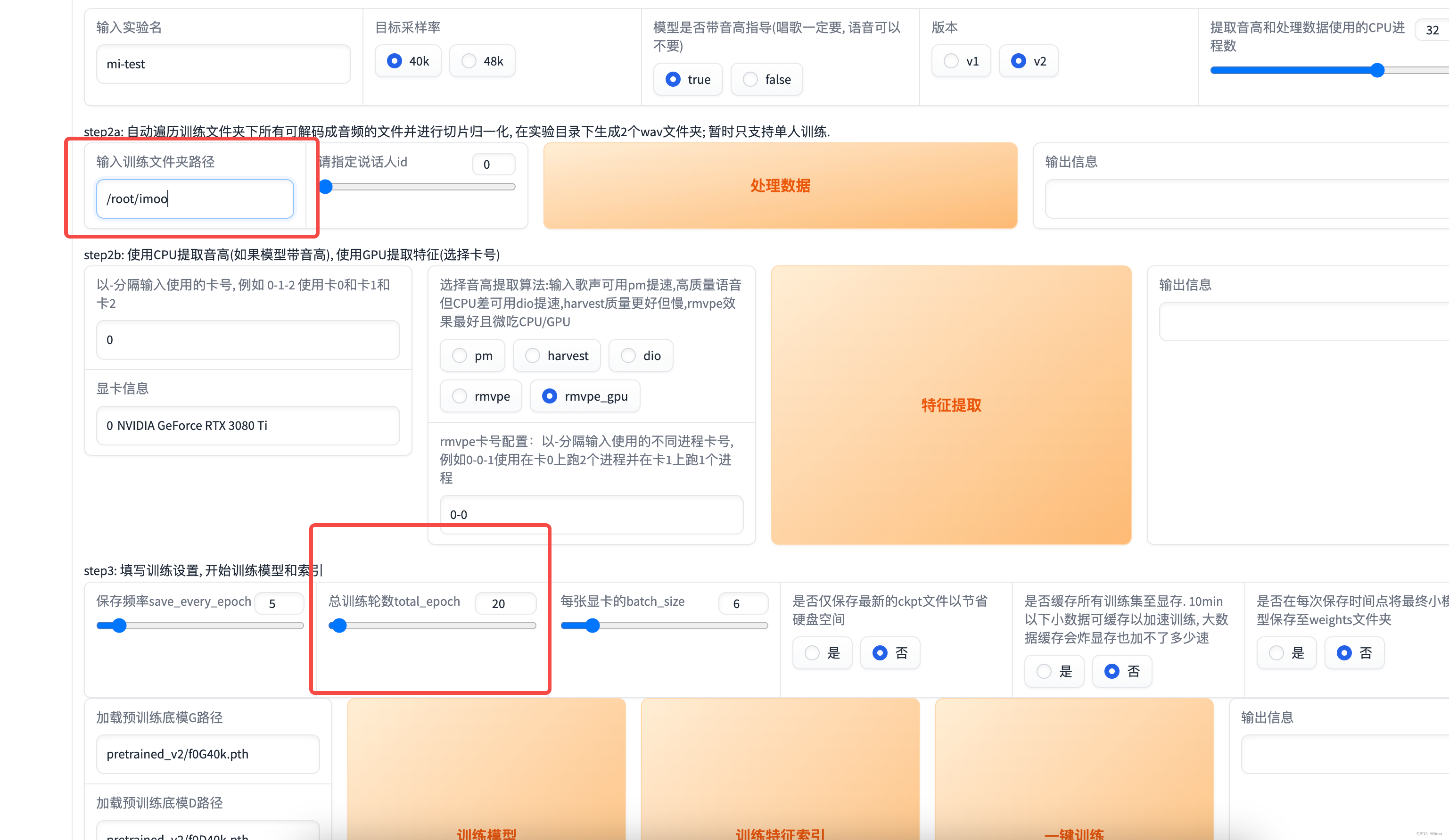
- 实验名:一会你生成的声音文件的名字
- 文件夹路径:/root/你刚才下载文件的地方,默认是 /root/auto-tmp
- 训练轮数:20够用,追求更好效果就开大点
-
点击开始训练,就会开始跑了,可以回到刚才的jupyterlab查看具体日志
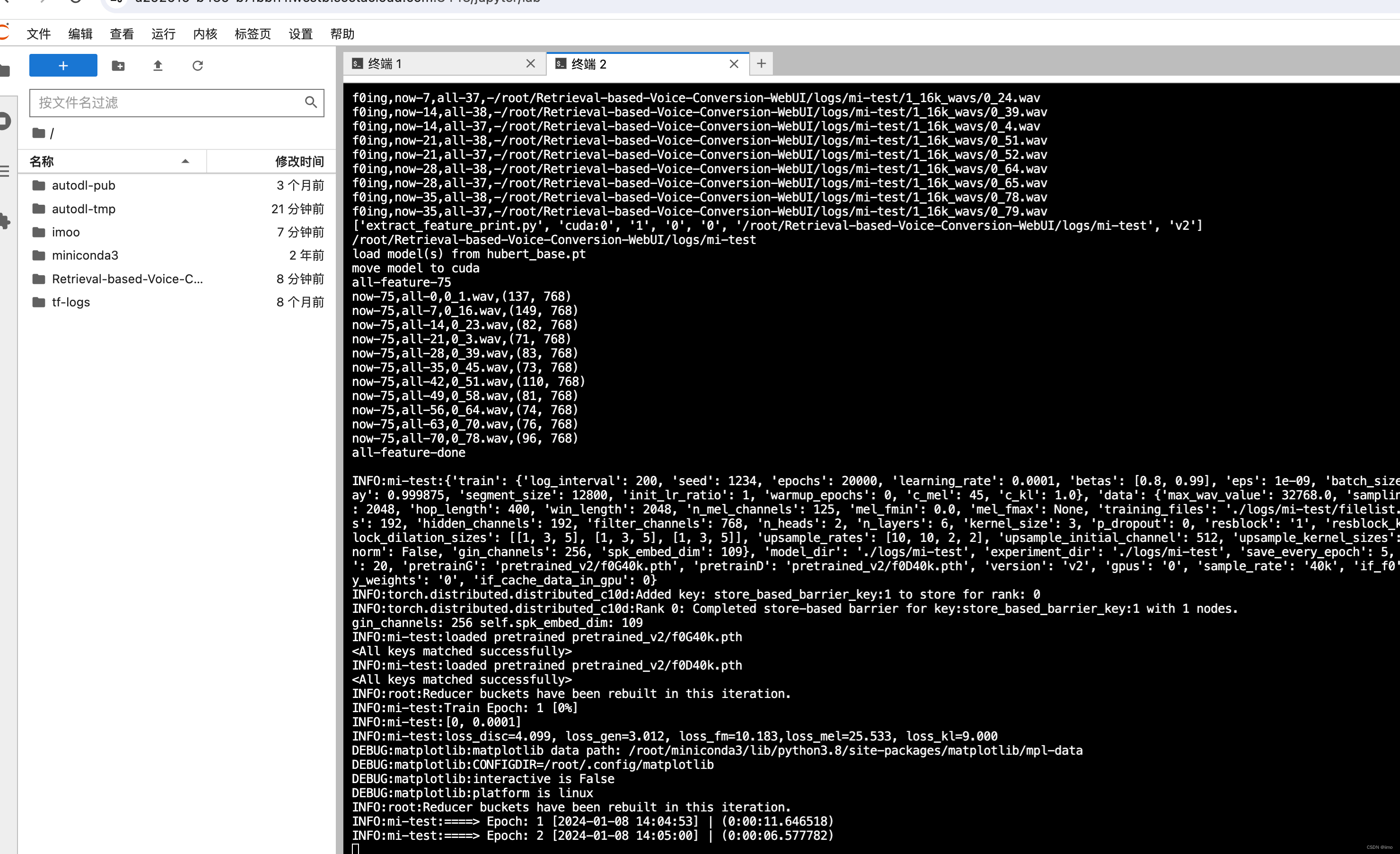
-
训练完成后,你可以在jupyterlab的/Retrieval-based-Voice-Conversion-WebUI/weights/找到训练结果,尾缀为.pth,这就是你的声音文件,将其下载到本地
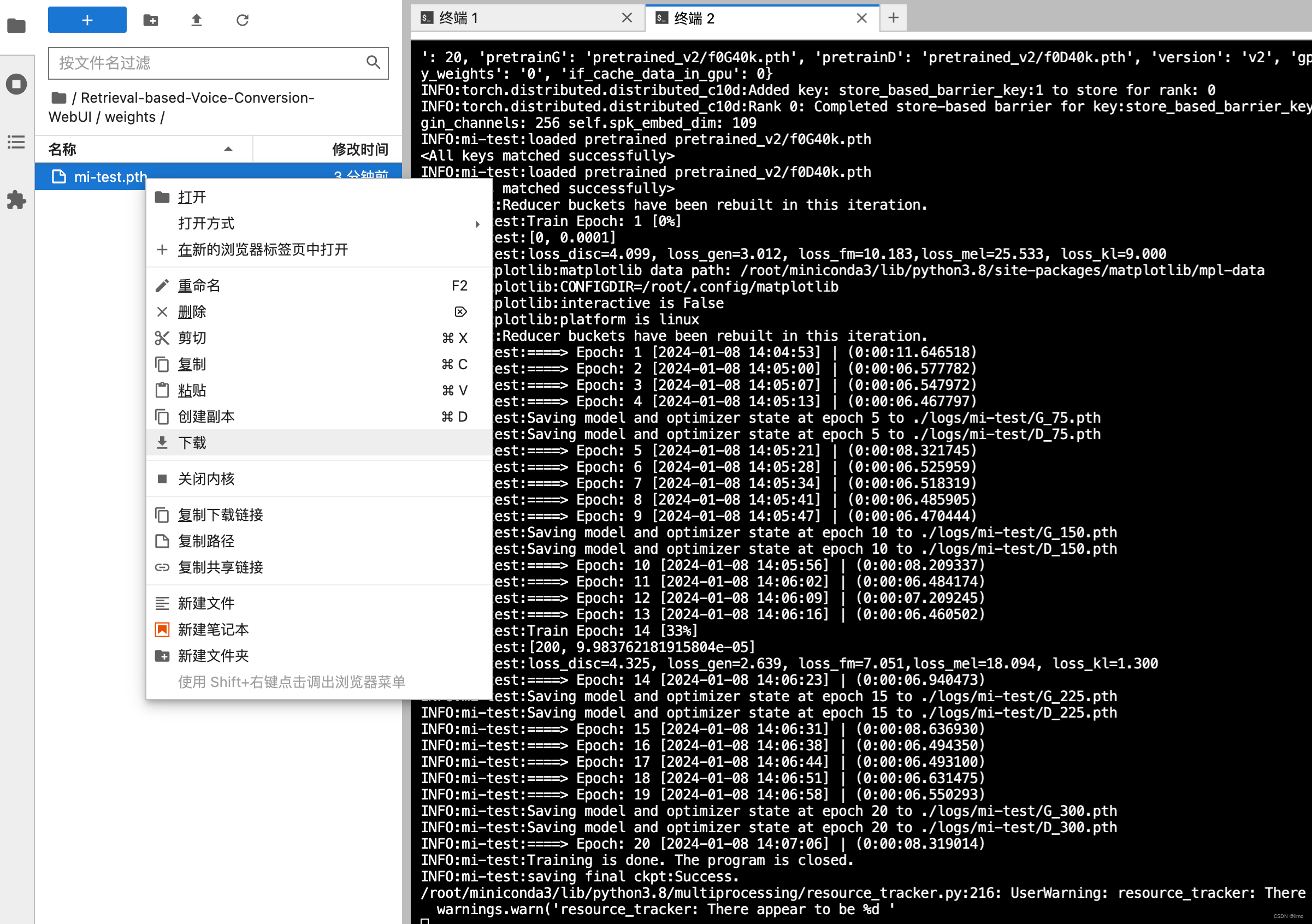
-
在 https://www.weights.gg/zh/create 上传自己的声音文件后,即可使用声音文件唱歌或说话,如果不想排队可以下载专门的软件Replay,网址是 https://www.tryreplay.io/,不过它内部下载很慢

















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









