









数据结构:单向链表Part1:https://blog.csdn.net/qq_41605114/article/details/104396149
数据结构:单向链表Part2:https://blog.csdn.net/qq_41605114/article/details/104590140
数据结构:循环链表:https://blog.csdn.net/qq_41605114/article/details/104541315
数据结构:双向链表:https://blog.csdn.net/qq_41605114/article/details/104575516
链表的衍生:
数据结构(受限线性表-栈):https://blog.csdn.net/qq_41605114/article/details/104377381
数据结构:队列:https://blog.csdn.net/qq_41605114/article/details/104432924
目录
链表是由一个个结点构成的,链表有几个关键的技术:
- 头结点
- 结点之间的链接
头结点是链表的起点,是链表的一切。
链表之间的链接,将全部结点从零散的数据变成了一条有逻辑的线。
头指针
头指针均大同小异,主要是保存结点的各类属性,比如链表的结点个数,尾指针等内容

头结点内容,第一个成员,均是头结点本身,因为只是为了好管理链表,所以头结点不放数据,不保存任何内容,只是作为占用内存的一段标记,将后驱指向第一个结点即可,为了更好的管理链表,才诞生了头结点和头结点内容结构体。
链表之间的链接——后驱(有时候也有前驱)指针
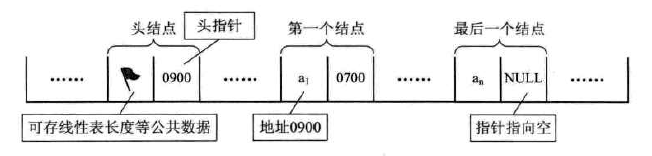
介绍头结点之前,首先要介绍一般的结点类型:

第一种:最普通的链表结构,包含要存储的数据,包含后驱指针。
但是,有一个很明显的问题,如果,要保存的数据不是int类型?是double或者用户自定义类型,那该怎么办呢?
可以对以上数据结构进行改进,将int变成void *指针类型
在“数据结构:单向链表Part1”:https://blog.csdn.net/qq_41605114/article/details/104396149
中有介绍
但是还是不够灵活,因为在插入操作中,因为插入环节是接口去执行的,必须给void *申请空间去储存要保存的数据的地址。
这增加了代码量,而且造成了new/malloc的频繁使用,增加出错风险,现在讲提出第二种和第三种结点
第二种和第三种:结点中没有保存数据的位置,只要后驱(在第三种中,有前驱) 第三种为双向链表的结点
第一种,是将数据的地址保存在结点中
第二种和第三种,是将结点放在数据里
下面对比一下三种情况插入的数据均如何:

第一种结点对应的插入元素类型,是很普通的结构体,变量将地址直接给结点
第二种和第三种,在插入元素结构体类型中,第一个成员,均是对应的结点类型,将结点包含在了数据中,这也就是这两者的区别了
- 将要插入的数据变成指针类型,放在结点中
- 将在要插入的数据中,包含结点
第一种,将数据放置于结点中,很好理解,结点之间的链接,之间用next后驱指针指向下一个结点的地址即可,有多少个数据就有多少个结点。
那么对于第二种和第三种,将结点放置于数据中,是怎么将结点链接在一起的呢?有两点
1:结构体的地址就是第一个成员变量的地址
typedef struct Test
{
int age;
QString name;
}T; T test1 = {1,"123"};
qDebug()<<"&test1"<<&test1;
qDebug()<<"&(test1.age)"<<&(test1.age);![]()
从上述代码就能看出,和指针一样,结构体的首地址就是结构体首成员的地址。
2:让数据中的结点的next后驱指针,指向下一个数据的地址
我们看一段插入操作,以第二种结点为例
void Insert_LL(LLHeader LL,int place,void * data);
接口三个输入,链表头结点内容的地址,插入位置,插入数据的地址
linklistProperty * mylist = (linklistProperty *)LL;
linklistnode * pCurrent = &(mylist->header);//从第一个结点开始
linklistnode * InsertData = (linklistnode *)data;进入函数的第一件事,就是强制类型转换
- 头结点内容类型的强制转换
- 结点指针,指向头结点
- 要插入的数据,将其首地址强制转换为结点类型,也就是在访问这个要插入内容的第一个成员,即结点本身
结点之间的连接,靠的就是后驱指针next的指向
现在将继续操作
for(int i = 0;i<place-1;++i)
{
pCurrent = pCurrent->next;
}
InsertData->next = pCurrent->next;
pCurrent->next = InsertData;
找到要插入位置,然后更新后驱即可。
整个过程,因为用户自定义结构体的第一个成员是结点类型,所以在接口中,不需要知道其他的内容,直接强转
结构体指针为结点类型,就直接访问结点中的next后驱指针,即可以在插入操作中更新后驱了,如下图所示:

下面举一个例子:
.h
//链表节点数据类型
struct LinkContent
{
struct LinkContent * next;
};
//链表数据类型
struct LinkProperty
{
struct LinkContent Content;
int size;
};
typedef void * LinkListTwo;//为了更好的让用户理解函数
typedef struct Test
{
LinkContent node;
QString name;
int age;
}T;数据结构和上述的第二种/第三种相同(只是部分变量名称进行了替换)
.cpp 具体操作如下:
T t1 = {nullptr,"1",10};
T t2 = {nullptr,"2",20};
T t3 = {nullptr,"3",30};
T t4 = {nullptr,"4",40};
T t5 = {nullptr,"5",50};
qDebug()<<"初始化结果:"<<t1.node.next;
qDebug()<<"初始化结果:"<<t2.node.next;
qDebug()<<"初始化结果:"<<t3.node.next;
qDebug()<<"初始化结果:"<<t4.node.next;
qDebug()<<"初始化结果:"<<t5.node.next;
首先是初始化,我们可以看见,链表中的next指针目前全部都被初始化为空了
qDebug()<<"t1首地址:"<<&t1;
qDebug()<<"t2首地址:"<<&t2;
qDebug()<<"t3首地址:"<<&t3;
qDebug()<<"t4首地址:"<<&t4;
qDebug()<<"t5首地址:"<<&t5;
LinkContent *myContent1 = (LinkContent*)(&t1);
LinkContent *myContent2 = (LinkContent*)(&t2);
LinkContent *myContent3 = (LinkContent*)(&t3);
LinkContent *myContent4 = (LinkContent*)(&t4);
LinkContent *myContent5 = (LinkContent*)(&t5);
myContent1->next = myContent2;
myContent2->next = myContent3;
myContent3->next = myContent4;
myContent4->next = myContent5;
myContent5->next = nullptr;之后我们取出插入元素的首地址
并将其强制转换类型,转换为结构体第一个元素的类型
t1是T类型,取地址(&t1),变成了指针,指向结构体的第一个元素,也就是LinkContent类型的指针
这也就是为什么一定要强调把 链表结点类型结构体变量 定义在用户自定义结构体中第一位的原因
强转后,就可以访问到每个要插入数据的next指针了,然后直接进行赋值操作
之后进行输出,并对比输出内容
qDebug()<<"强转类型后t1.node.next:"<<t1.node.next;
qDebug()<<"强转类型后t2.node.next:"<<t2.node.next;
qDebug()<<"强转类型后t3.node.next:"<<t3.node.next;
qDebug()<<"强转类型后t4.node.next:"<<t4.node.next;
qDebug()<<"强转类型后t5.node.next:"<<t5.node.next;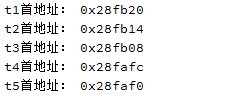

可见,要插入元素之间的连接已经完成,那么以上只是演示
言外之意是,在开发者眼里,不管用户自定义类型有多少个成员变量,只要第一个成员变量是链表结点类型结构体变量,在开发者写各类接口的时候,直接将传入接口的参数强制转换成链表结点类型结构体变量即可,然后就可以完成链表元素之间的连接。
到时候只需要给用户提供:
- 链表结点类型结构体名称
- 头结点结构体名称(初始化和调用接口的时候用)
- 各个接口名称和输入要求
即可
做到了面向对象编程的基本要求
初始化和销毁
初始化和销毁
初始化过程中,需要先堆上要一部分内存空间
在new和malloc之间,选择原则很简单,需要扩容,用malloc,就像动态数组,及线性表的顺序存储,用malloc显然更好操作:
数据结构:线性表-动态数组:https://blog.csdn.net/qq_41605114/article/details/104315027
C/C++:细说new与malloc的10点区别 :https://blog.csdn.net/qq_41605114/article/details/104342587
插入与删除
链表的插入和删除,关键问题,就是找到要操作的结点(插入或删除)的前一个结点,这是插入和删除的关键操作
















 1878
1878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









