









1、骨干和头部的不同学习率
在语义分割中,有些方法使头部的LR大于主干,以获得更好的性能或更快的收敛速度。
在MMSegme中,你可以添加以下行来配置,使头部的LR是骨干的10倍。
optimizer=dict(
paramwise_cfg = dict(
custom_keys={
'head': dict(lr_mult=10.)}))
通过此修改,任何名称中有“head”的参数组的LR将被乘以10。你可以参考MMCV文档了解更多细节。参考MMCV
MMCV优化器的默认构造函数。
mmcv.runner.DefaultOptimizerConstructor(optimizer_cfg: Dict, paramwise_cfg: Optional[Dict] = None)
默认情况下,每个参数共享相同的优化器设置,我们提供一个参数paramwise_cfg来指定参数设置。它是一个字典,可以包含以下字段:
1、custom_keys (dict):通过键指定参数相关的设置。如果custom_keys中的一个键是一个参数名称的子字符串,那么参数的设置将由custom_keys [key]指定,其他设置如bias_lr_mult等将被忽略。需要注意的是,前面提到的键是参数名称的子字符串中最长的键。如果有多个长度相同的匹配键,则选择字母顺序较低的键。Custom_keys [key]应该是一个字典,可以包含字段lr_mult和decay_mult。参见下面的示例2。
2、bias_lr_mult (float):乘以所有偏置参数的学习率(除了DCN的归一化层和偏移层)。
3、bias_decay_mult (float):它将乘以所有偏置参数的权重衰减(除了那些在归一化层,深度conv层,偏移层的DCN)。
4、dwconv_decay_mult (float):它将乘到深度conv层的所有权值和偏差参数的权值衰减。
5、dcn_offset_lr_mult (float):它将乘到模型可变形卷积中偏移层参数的学习率。
6、bypass_duplicate (bool):如果为真值,重复参数将不会添加到优化器中。默认值:False。
如果使用了dcn_offset_lr_mult选项,构造函数将覆盖偏移层中bias_lr_mult的影响。所以当同时使用bias_lr_mult和dcn_offset_lr_mult时要小心。如果你想在可变形的convs中同时应用它们到偏移层,设置dcn_offset_lr_mult为原来的dcn_offset_lr_mult * bias_lr_mult。如果使用了dcn_offset_lr_mult选项,构造函数将把它应用到模型中的所有DCN层。因此,当模型在骨干之外的地方包含多个DCN层时要小心。
Parameters
model (nn.Module) – The model with parameters to be optimized.
optimizer_cfg (dict) –
The config dict of the optimizer. Positional fields are
type: class name of the optimizer.
Optional fields are
any arguments of the corresponding optimizer type, e.g., lr, weight_decay, momentum, etc.
paramwise_cfg (dict, optional) – Parameter-wise options.
Example 1:
>>> model = torch.nn.modules.Conv1d(1, 1, 1)
>>> optimizer_cfg = dict(type='SGD', lr=0.01, momentum=0.9,
>>> weight_decay=0.0001)
>>> paramwise_cfg = dict(norm_decay_mult=0.)
>>> optim_builder = DefaultOptimizerConstructor(
>>> optimizer_cfg, paramwise_cfg)
>>> optimizer = optim_builder(model)
Example 2:
>>> # assume model have attribute model.backbone and model.cls_head
>>> optimizer_cfg = dict(type='SGD', lr=0.01, weight_decay=0.95)
>>> paramwise_cfg = dict(custom_keys={
'backbone': dict(lr_mult=0.1, decay_mult=0.9)})
>>> optim_builder = DefaultOptimizerConstructor(
>>> optimizer_cfg, paramwise_cfg)
>>> optimizer = optim_builder(model)
>>> # Then the `lr` and `weight_decay` for model.backbone is
>>> # (0.01 * 0.1, 0.95 * 0.9). `lr` and `weight_decay` for
>>> # model.cls_head is (0.01, 0.95).
2、Online Hard Example Mining (OHEM)在线难例挖掘
1、语义分割
我们在这里HERE实现了一个像素采样器,用于训练采样。
下面是启用OHEM的训练PSPNet的配置示例。
_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
model=dict(
decode_head=dict(
sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=100000)) )
这样,只使用置信度小于0.7的像素进行训练。在训练过程中我们至少保持100000像素。如果没有指定thresh,将选择最高min_keep损失的像素。
OHEM(Online Hard negative Example Mining,在线难例挖掘)见于[5]。两阶段检测模型中,提出的RoI Proposal在输入R-CNN子网络前,我们有机会对正负样本(背景类和前景类)的比例进行调整。通常,背景类的RoI Proposal个数要远远多于前景类,Fast R-CNN的处理方式是随机对两种样本进行上采样和下采样,以使每一batch的正负样本比例保持在1:3,这一做法缓解了类别比例不均衡的问题,是两阶段方法相比单阶段方法具有优势的地方,也被后来的大多数工作沿用。
论文中把OHEM应用在Fast R-CNN,是因为Fast R-CNN相当于目标检测各大框架的母体,很多框架都是它的变形,所以作者在Fast R-CNN上应用很有说明性。
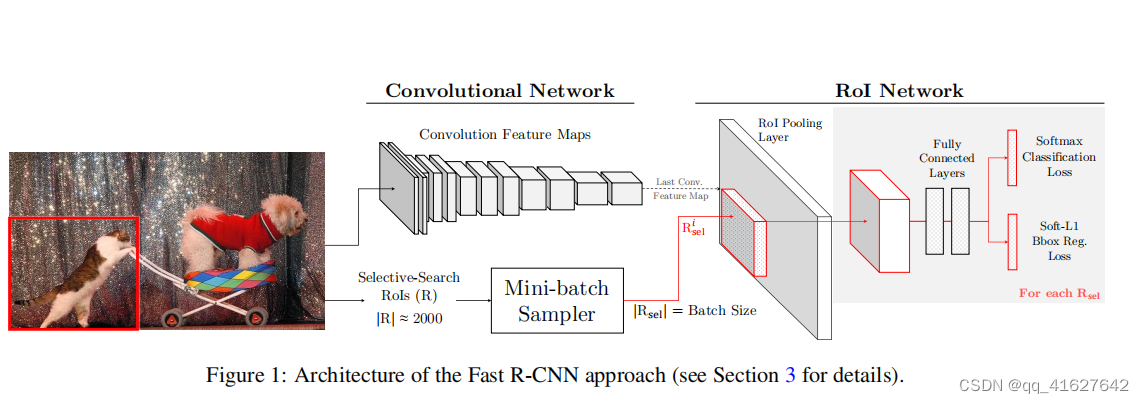
上图是Fast R-CNN框架,简单的说,Fast R-CNN框架是将224×224的图片当作输入,经过conv,pooling等操作输出feature map,通过selective search 创建2000个region proposal,将其一起输入ROI pooling层,接上全连接层与两个损失层。
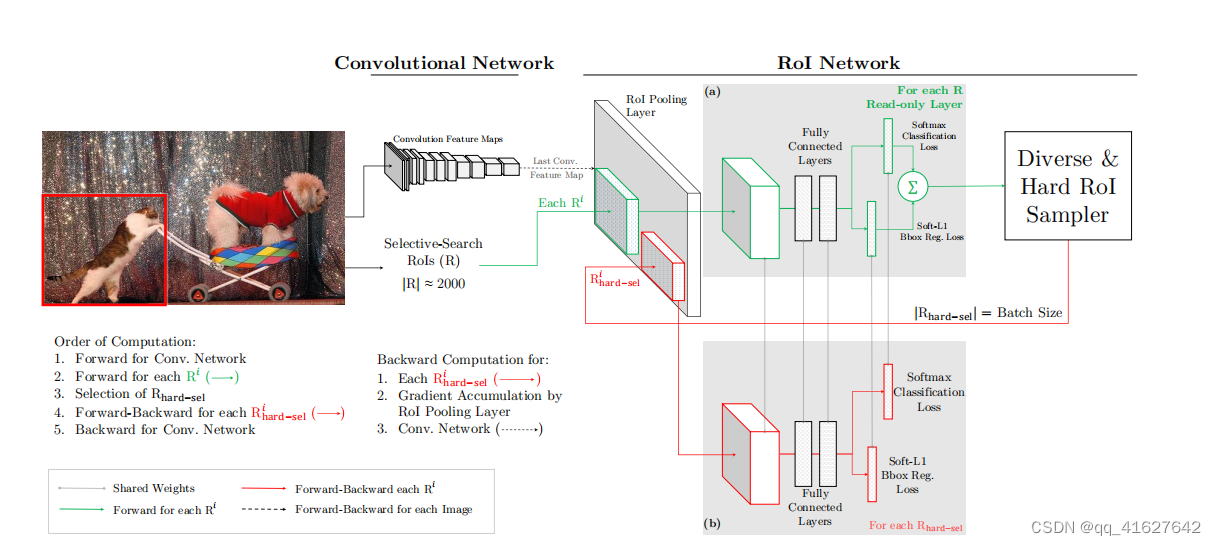
作者将OHEM应用在Fast R-CNN的网络结构,如上图,这里包含两个RoI network,上面一个RoI network是只读的,为所有的RoI 在前向传递的时候分配空间,下面一个RoI network则同时为前向和后向分配空间。在OHEM的工作中,作者提出用R-CNN子网络对RoI Proposal预测的分数来决定每个batch选用的样本。这样,输入R-CNN子网络的RoI Proposal总为其表现不好的样本,提高了监督学习的效率。
首先,RoI 经过RoI plooling层生成feature map,然后进入只读的RoI network得到所有RoI 的loss;然后是hard RoI sampler结构根据损失排序选出hard example,并把这些hard example作为下面那个RoI network的输入。
实际训练的时候,每个mini-batch包含N个图像,共|R|个RoI ,也就是每张图像包含|R|/N个RoI 。经过hard RoI sampler筛选后得到B个hard example。作者在文中采用N=2,|R|=4000,B=128。 另外关于正负样本的选择:当一个RoI 和一个ground truth的IoU大于0.5,则为正样本;当一个RoI 和所有ground truth的IoU的最大值小于0.5时为负样本。
总结来说,对于给定图像,经过selective search RoIs,同样计算出卷积特征图。但是在绿色部分的(a)中,一个只读的RoI网络对特征图和所有RoI进行前向传播,然后Hard RoI module利用这些RoI的loss选择B个样本。在红色部分(b)中,这些选择出的样本(hard examples)进入RoI网络,进一步进行前向和后向传播。
2、MMDetection中,OHEM(online hard example mining):(源码解析)
rcnn=[
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.4, # 更换
neg_iou_thr=0.4,
min_pos_iou=0.4,
ignore_iof_thr=-1),
sampler=dict(
type='OHEMSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False),
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
ignore_iof_thr=-1),
sampler=dict(
type='OHEMSampler', # 解决难易样本,也解决了正负样本比例问题。
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False),
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.6,
neg_iou_thr=0.6,
min_pos_iou=0.6,
ignore_iof_thr=-1),
sampler=dict(
type='OHEMSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False)
],
stage_loss_weights=[1, 0.5, 0.25])
3、Class Balanced Loss(解决类别不均衡)
对于类分布不均衡的数据集,可以更改每个类的减重。这里有一个城市景观数据集的例子。
1、crossEntropyLoss
_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
model=dict(
decode_head=dict(
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0,
# DeepLab used this class weight for cityscapes
class_weight=[0.8373, 0.9180, 0.8660, 1.0345, 1.0166, 0.9969, 0.9754,
1.0489, 0.8786, 1.0023, 0.9539, 0.9843, 1.1116, 0.9037,
1.0865, 1.0955, 1.0865, 1.1529, 1.0507])))
class_weight将作为权重参数传递给crossEntropyLoss。请参阅PyTorch文档了解详细信息。
2、loss_cls修改为focalloss(目标检测)
# model settings
model = dict(
type='FasterRCNN',
pretrained=None,
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
style='pytorch',
dcn=dict( #在最后三个block加入可变形卷积
modulated=False, deformable_groups=1, fallback_on_stride=False),
stage_with_dcn=(False, True, True, True)),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_scales=[8],
anchor_ratios=[0.5, 1.0, 2.0],
anchor_strides=[4, 8, 16, 32, 64],#可根据样本瑕疵尺寸分布,修改anchor的长宽比
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0],
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=True, loss_weight=1.0),#此处可替换成focalloss
loss_bbox=dict(
type='SmoothL1Loss',
beta=1.0 / 9.0,
loss_weight=1.0)),
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(
type='RoIAlign',
out_size=7,
sample_num=2),
out_channels=256,
featmap_strides=[4, 8, 16, 32])
bbox_head=dict(
type='SharedFCBBoxHead',
num_fcs=2,
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=11,#类别数+1(背景类)
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2],
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(
type='SmoothL1Loss',
beta=1.0,
loss_weight=1.0)))
# model training and testing settings
4、Multiple Losses
对于损失计算,我们支持同时进行多个损失培训。下面是DRIVE数据集上训练unet的配置示例,其损失函数是CrossEntropyLoss和DiceLoss的1:3加权和:
_base_ = './fcn_unet_s5-d16_64x64_40k_drive.py'
model = dict(
decode_head=dict(loss_decode=[dict(type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)]),
auxiliary_head=dict(loss_decode=[dict(type='CrossEntropyLoss', loss_name='loss_ce',loss_weight=1.0),
dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)]),
)
这样,loss_weight和loss_name分别为相应损失的训练日志中的权重和名称。注意:如果您希望将这个丢失项包含到反向图中,那么loss_必须是名称的前缀。
5、Ignore specified label index in loss calculation
在默认设置中,avg_non_ignore=False,这意味着每个像素都计算损失,尽管其中一些像素属于忽略索引标签。
对于损失计算,我们支持通过avg_non_ignore和ignore_index忽略某个标签的索引。这样,平均损耗只计算在不可忽略的标签上,这样可以达到更好的性能,这里是参考。下面是Cityscapes数据集上训练unet的配置示例:在损失计算中,它将忽略标签0,这是背景,损失平均只计算在非忽略标签上:
_base_ = './fcn_unet_s5-d16_4x4_512x1024_160k_cityscapes.py'
model = dict(
decode_head=dict(
ignore_index=0,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0, avg_non_ignore=True),
auxiliary_head=dict(
ignore_index=0,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0, avg_non_ignore=True)),
))
6、Multi-scale Training/Testing 多尺度训练/测试(目标检测)
输入图片的尺寸对检测模型的性能影响相当明显,事实上,多尺度是提升精度最明显的技巧之一。在基础网络部分常常会生成比原图小数十倍的特征图,导致小物体的特征描述不容易被检测网络捕捉。通过输入更大、更多尺寸的图片进行训练,能够在一定程度上提高检测模型对物体大小的鲁棒性,仅在测试阶段引入多尺度,也可享受大尺寸和多尺寸带来的增益。
multi-scale training/testing最早见于[1],训练时,预先定义几个固定的尺度,每个epoch随机选择一个尺度进行训练。测试时,生成几个不同尺度的feature map,对每个Region Proposal,在不同的feature map上也有不同的尺度,我们选择最接近某一固定尺寸(即检测头部的输入尺寸)的Region Proposal作为后续的输入。在[2]中,选择单一尺度的方式被Maxout(element-wise max,逐元素取最大)取代:随机选两个相邻尺度,经过Pooling后使用Maxout进行合并,如下图所示。
问题:多尺度的选择有什么规则和技巧吗?
答:如果模型不考虑时间开销,尺寸往大的开。一般来说尺度越大效果越好,主要是因为检测的小目标越多效果越差。如果是新手那就按照默认参数的比例扩大就行了,然后测试的时候取训练集的中间值。比如cascade50默认尺度是(1333,800),多尺度可以按照默认尺度的倍数扩大比如扩大两倍(2666,1600),多尺度训练可以写成[(1333, 800), (2666, 1600)],单尺度测试可以选择(2000, 1200),多尺度测试可以选择为多尺度训练的尺度加上他们的中间值[(1333, 800), (2000, 1200),(2666, 1600)]。keep_ratio=True,一般不考虑长边。
MMDetection中,多尺度训练/测试:(源码解析)
只需要修改train_pipeline 和test_pipeline中的img_scale部分即可(换成[(), ()]或者[(), (), ()…])。带来的影响是:train达到拟合的时间增加、test的时间增加,一旦test的时间增加一定会影响比赛的分数,因为比赛都会将测试的时间作为评分标准之一:
train_pipeline中dict(type=‘Resize’, img_scale=(1333, 800),
keep_ratio=True)的keep_ratio解析。假设原始图像大小为(1500, 1000),ratio=长边/短边 = 1.5。
当keep_ratio=True时,img_scale的多尺度最多为两个。假设多尺度为[(2000, 1200), (1333,
800)],则代表的含义为:首先将图像的短边固定到800到1200范围中的某一个数值假设为1100,那么对应的长边应该是短边的ratio=1.5倍为
[公式] ,且长边的取值在1333到2000的范围之内。如果大于2000按照2000计算,小于1300按照1300计算。
当keep_ratio=False时,img_scale的多尺度可以为任意多个。假设多尺度为[(2000, 1200), (1666,
1000),(1333, 800)],则代表的含义为:随机从三个尺度中选取一个作为图像的尺寸进行训练。test_pipeline 中img_scale的尺度可以为任意多个,含义为对测试集进行多尺度测试(可以理解为TTA)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True), #这里可以更换多尺度[(),()]
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800), #这里可以更换多尺度[(),()]
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
比如我简短涉及到的soft_nms,多尺度训练,TTA,这些tricks可以一定程度上提高成绩,但我认为相比较聚焦于tricks,一个highlevel的视角更重要。以下是我认为完成一个任务需要具备的几个条件:
- 对于数据的深入了解。包括但不限于:w、h的分布,分辨率的分布,目标物体的w/h比(用来确定anchor shape)
- 整体的思路要清晰:选用不同的baseline model测试,加tricks,怎么对数据集做处理,以及实验记录。
- 有时候算力确实是决定一个队伍能走多远的瓶颈。
7、Box Refinement/Voting 预测框微调/投票法/模型融合
微调法和投票法由工作[4]提出,前者也被称为Iterative Localization。
微调法最初是在SS算法得到的Region Proposal基础上用检测头部进行多次迭代得到一系列box,在ResNet的工作中,作者将输入R-CNN子网络的Region Proposal和R-CNN子网络得到的预测框共同进行NMS(见下面小节)后处理,最后,把跟NMS筛选所得预测框的IoU超过一定阈值的预测框进行按其分数加权的平均,得到最后的预测结果。
投票法可以理解为以顶尖筛选出一流,再用一流的结果进行加权投票决策。
不同的训练策略,不同的 epoch 预测的结果,使用 NMS 来融合,或者soft_nms
需要调整的参数:
box voting 的阈值。
不同的输入中这个框至少出现了几次来允许它输出。
得分的阈值,一个目标框的得分低于这个阈值的时候,就删掉这个目标框。
模型融合主要分为两种情况:
单个模型的不同epoch进行融合
这里主要是在nms之前,对于不同模型预测出来的结果,根据score来排序再做nms操作。
- 多个模型的融合
这里是指不同的方法,比如说faster rcnn与retinanet的融合,可以有两种情况:
a) 取并集,防止漏检。
b) 取交集,防止误检,提高精度。
8、随机权值平均(Stochastic Weight Averaging,SWA
随机权值平均只需快速集合集成的一小部分算力,就可以接近其表现。SWA 可以用在任意架构和数据集上,都会有不错的表现。根据论文中的实验,SWA 可以得到我之前提到过的更宽的极小值。在经典认知下,SWA 不算集成,因为在训练的最终阶段你只得到一个模型,但它的表现超过了快照集成,接近 FGE(多个模型取平均)。
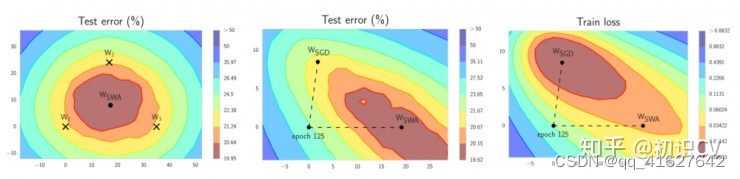
结合 WSWA 在测试集上优于 SGD 的表现,这意味着尽管 WSWA 训练时的损失较高,它的泛化性更好。
SWA 的直觉来自以下由经验得到的观察:每个学习率周期得到的局部极小值倾向于堆积在损失平面的低损失值区域的边缘(上图左侧的图形中,褐色区域误差较低,点W1、W2、3分别表示3个独立训练的网络,位于褐色区域的边缘)。对这些点取平均值,可能得到一个宽阔的泛化解,其损失更低(上图左侧图形中的 WSWA)。
下面是 SWA 的工作原理。它只保存两个模型,而不是许多模型的集成:
第一个模型保存模型权值的平均值(WSWA)。在训练结束后,它将是用于预测的最终模型。
第二个模型(W)将穿过权值空间,基于周期性学习率规划探索权重空间。

pytorch实现
此外,基于 fast.ai 库的 SWA 可见 :添加链接描述














 1429
1429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









