






创建SparkSession实例对象
创建SparkSession对象的时候需要根据不同情景进行不同的配置设置(例如是否是本地模式、是否是Hive以及Spark应用优化参数)。造成该问题的原因终究还是模板都要面临的难点——代码不能写死。
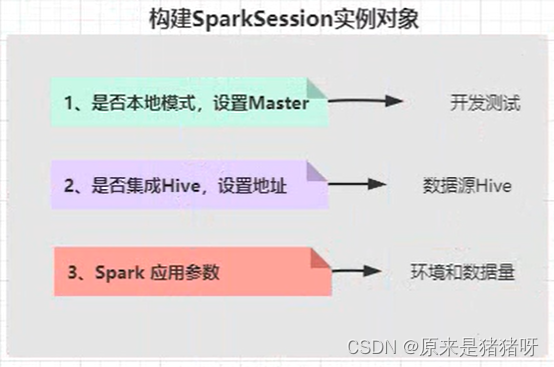
创建原因
我们需要根据不同的开发环境对配置参数进行修改,就比如说是否是Hive,如果判断是Hive的情况下,则需要对Hive进行集成并设置Hive的地址,而如果不是Hive不需要进行集成,尽管只有两种可能:是或否。
但在此基础上又会面临另一个问题:配置信息直接暴露在代码上,这对于日后的运行来说是十分致命的。所以结合以上的问题,我们需要在构建SparkSession实例对象的时候将配置抽象出来,只要将这些配置信息都放在配置文件中,动态加载配置,便能将这些问题迎刃而解。
其中,第一第二点作为常规的开发环境配置,内容并不是很多而且统一性比较强,所以可以将其参数放置到同一个配置文件下,并且通过一个自定义配置类(如:ModelConfig类)将配置信息读取出来,将参数对用户不可见,同时便于管理:
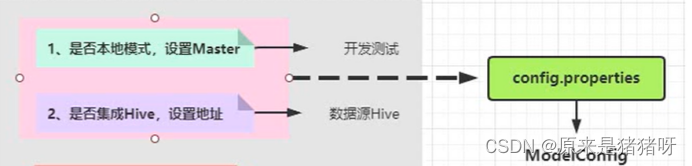
而Spark应用优化参数在实际的生产环境中需要的参数设置数量巨大,为了方便以后的维护和调试,不应与其他配置参数混合在一起,故应单独将其设置一个文件,同样要自定义一个类单独加载配置文件内容(如:使用SparkConf#set方法设置参数属性,使用的时候我们可以直接调用:sparkConf.set(“spark.serializer”,”org.apache.spark.serializer.KryoSerializer”)),总的思路就是,先通过自定义类读取配置文件,然后通过set方法设置配置属性即可:
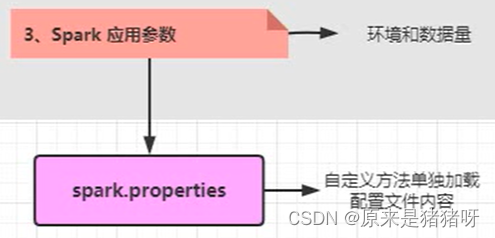
所以整个SparkSessoin实例对象的构建图应该分为两部分:
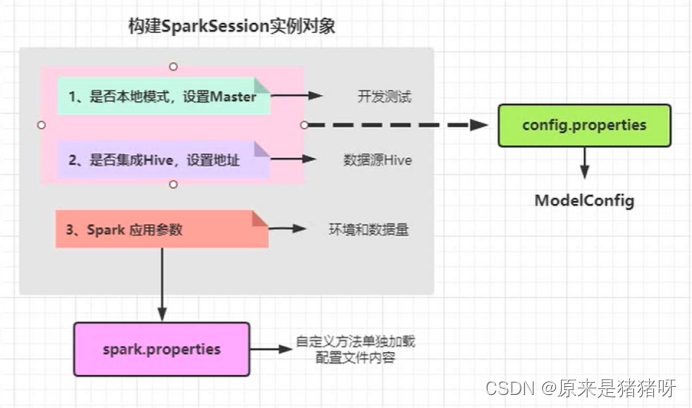
代码测试
就比如,现在我创建好了一个conf文件(正式代码还是用的properties,这里写conf文件是为了方便测试),将参数配置好了(spark使用的是.conf文件,而上边环境参数使用的是.properties文件,都是键值对的形式,但properties文件的值不需要加双引号标注,conf文件需要加双引号)

测试代码如下:
import java.util
import java.util.Map
import com.typesafe.config.{Config, ConfigFactory, ConfigValue}
object SparkConfigTest {
def main(args: Array[String]): Unit = {
// a、使用ConfigFactory加载spark.conf
val config: Config = ConfigFactory.load("spark.conf")
// 获取加载配置信息
val entrySet: util.Set[Map.Entry[String, ConfigValue]] = config.entrySet()
// 遍历
import scala.collection.JavaConverters._
for (entry <- entrySet.asScala) {
// 获取属性来源的文件名称
val resource = entry.getValue.origin().resource()
if ("spark.conf".equals(resource)) {
println(entry.getKey + ": " + entry.getValue.unwrapped().toString)
}
}
}
}注意点
需要注意的是,val entrySet: util.Set[Map.Entry[String, ConfigValue]] = config.entrySet() 获取到的是java的Set类,我们这是Scala,需要将其转换为Scala的Set类:entry <- entrySet.asScala;
再一个,读取到的这个Set集合,并不只是spark.conf的配置,而是所 有 的 配 置 !
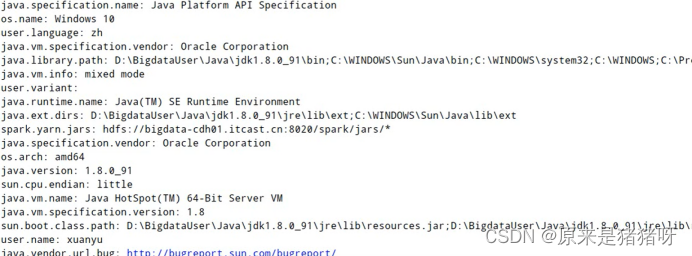
包括了系统的配置,所以我们要从这一堆配置里挑选来源于spark.conf的参数,也就是if ("spark.conf".equals(resource)) 的作用,相信大家也看得懂,很简单但很关键!
解决,筛选出了配置文件中的属性配置:

代码实现
OK,思路已经有了,测试代码也运行成功了,接下来就将这个工具类搞定,先奉上具体代码:
Spark.properties配置文件(仅供参考,应该根据实际进行修改):
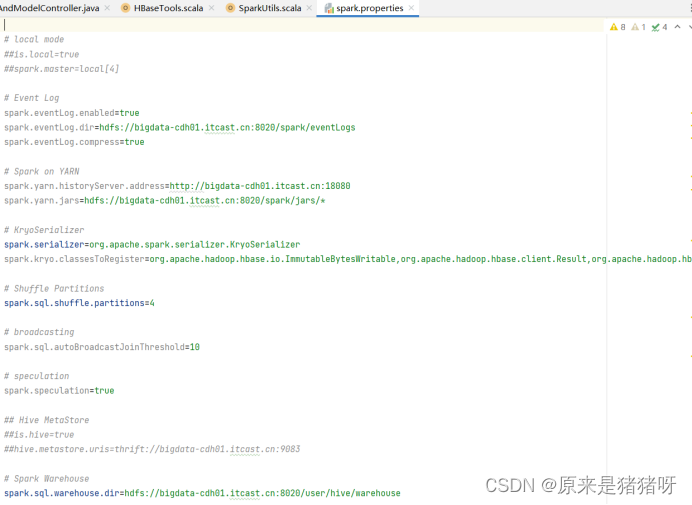
SparkUntil工具类:
import java.util
import java.util.Map
import cn.itcast.tags.config.ModelConfig
import com.typesafe.config.{Config, ConfigFactory, ConfigValue}
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* 创建SparkSession对象工具类
*/
object SparkUtils {
/**
* 加载Spark Application默认配置文件,设置到SparkConf中
*
* @param resource 资源配置文件名称
* @return SparkConf对象
*/
def loadConf(resource: String): SparkConf = {
// 1. 创建SparkConf 对象
val sparkConf = new SparkConf()
// 2. 使用ConfigFactory加载配置文件
val config: Config = ConfigFactory.load(resource)
// 3. 获取加载配置信息
val entrySet: util.Set[Map.Entry[String, ConfigValue]] = config.entrySet()
// 4. 循环遍历设置属性值到SparkConf中
import scala.collection.JavaConverters._
entrySet.asScala.foreach { entry =>
// 获取属性来源的文件名称
val resourceName = entry.getValue.origin().resource()
if (resource.equals(resourceName)) {
sparkConf.set(entry.getKey, entry.getValue.unwrapped().toString)
}
}
// 5. 返回SparkConf对象
sparkConf
}
/**
* 构建SparkSession实例对象,如果是本地模式,设置master
*/
def createSparkSession(clazz: Class[_], isHive: Boolean = false): SparkSession = {
// 1. 构建SparkConf对象
val sparkConf: SparkConf = loadConf(resource = "spark.properties")
// 2. 判断应用是否是本地模式运行,如果是设置
if (ModelConfig.APP_IS_LOCAL) {
sparkConf.setMaster(ModelConfig.APP_SPARK_MASTER)
}
// 3. 创建SparkSession.Builder对象
var builder: SparkSession.Builder = SparkSession.builder()
.appName(clazz.getSimpleName.stripSuffix("$"))
.config(sparkConf)
// 4. 判断应用是否集成Hive,如果集成,设置Hive MetaStore地址
// 如果在config.properties中设置集成Hive,表示所有SparkApplication都集成Hive;否则判断isHive,表示针对某个具体应用是否集成Hive
if (ModelConfig.APP_IS_HIVE || isHive) {
builder = builder
.enableHiveSupport()
.config("hive.metastore.uris", ModelConfig.APP_HIVE_META_STORE_URL)
}
// 5. 采用建造者设计模式构建SparkSession实例对象
val session: SparkSession = builder.getOrCreate()
// 6. 返回构建实例对象
session
}
}运行结果
完美解决,看一下代码行数的对比知道优化程度:
(优化前:)
(优化后:)

结论
可以看到简直是赏心悦目的行数优化,对日后的日常维护也是极其重要,需要增加什么参数直接在properties配置文件中添加即可,需要逻辑添加也不再需要在一堆代码里寻找配置文件设置究竟在哪,更不需要担心配置文件信息泄露的问题,一石多鸟。
标签基类的优化
优化原因
我们可以留意到,每一个标签类他都有一个公共属性:标签名称以及标签类型,所以我们大可定义一个抽象类Abstract Model,使得所有标签类都去继承此类,每次需要新增新的标签我们就只需要传递标签名称和标签类型,然后实现标签计算方法doTag就可以快速构建一个标签类了。
首先第一步:我们需要定义一个类,以区别标签类型,我们的标签类型一共就三种——1.规则匹配类型标签(将业务数据中业务字段field与属性标签中规则rule进行匹配关联,给用户打上标签的值) 2.数据挖掘类型标签 3.统计类型标签 这三类,目前数量已经固定死了,所以我们第一个就能想到的,就是使用一个枚举类去表示标签类型。
public enum ModelType {
MATCH // 规则匹配
,
ML // 挖掘
,
STATISTICS // 统计
}再将标签模板作为一个抽象类,加入标签类型,完整的标签模型类就完成了,奉上源码:
import cn.itcast.tags.config.ModelConfig
import cn.itcast.tags.meta.{HBaseMeta, MetaParse}
import cn.itcast.tags.utils.SparkUtils
import org.apache.spark.internal.Logging
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.storage.StorageLevel
/**
* 标签基类,各个标签模型继承此类,实现其中打标签方法doTag即可
*/
abstract class AbstractTagModel(modelName: String, modelType: ModelType) extends Logging{
// 设置Spark应用程序运行的用户:root, 默认情况下为当前系统用户
System.setProperty("user.name", ModelConfig.FS_USER)
System.setProperty("HADOOP_USER_NAME", ModelConfig.FS_USER)
// 变量声明
var spark: SparkSession = _
// 1. 初始化:构建SparkSession实例对象
def init(isHive: Boolean = false): Unit = {
spark = SparkUtils.createSparkSession(this.getClass, isHive)
}
// 2. 准备标签数据:依据标签ID从MySQL数据库表tbl_basic_tag获取标签数据
def getTagData(tagId: Long): DataFrame = {
spark.read
.format("jdbc")
.option("driver", ModelConfig.MYSQL_JDBC_DRIVER)
.option("url", ModelConfig.MYSQL_JDBC_URL)
.option("dbtable", ModelConfig.tagTable(tagId))
.option("user", ModelConfig.MYSQL_JDBC_USERNAME)
.option("password", ModelConfig.MYSQL_JDBC_PASSWORD)
.load()
}
// 3. 业务数据:依据业务标签规则rule,从数据源获取业务数据
def getBusinessData(tagDF: DataFrame): DataFrame = {
// a. 获取业务标签规则rule,并解析封装值Map集合
val rulesMap = MetaParse.parseRuleToParams(tagDF)
// b. 依据inType判断数据源,加载业务数据
val businessDF: DataFrame = MetaParse.parseMetaToData(spark, rulesMap)
// c. 返回加载业务数据
businessDF
}
// 4. 构建标签:依据业务数据和属性标签数据建立标签
def doTag(businessDF: DataFrame, tagDF: DataFrame): DataFrame
// 5. 保存画像标签数据至HBase表
def saveTag(modelDF: DataFrame): Unit = {
/*
HBaseTools.write(
modelDF, //
ModelConfig.PROFILE_TABLE_ZK_HOSTS, //
ModelConfig.PROFILE_TABLE_ZK_PORT, //
ModelConfig.PROFILE_TABLE_NAME, //
ModelConfig.PROFILE_TABLE_FAMILY_USER, //
ModelConfig.PROFILE_TABLE_ROWKEY_COL //
)
*/
modelDF.write
.mode(SaveMode.Overwrite)
.format("hbase")
.option("zkHosts", ModelConfig.PROFILE_TABLE_ZK_HOSTS)
.option("zkPort", ModelConfig.PROFILE_TABLE_ZK_PORT)
.option("hbaseTable", ModelConfig.PROFILE_TABLE_NAME)
.option("family", ModelConfig.PROFILE_TABLE_FAMILY_USER)
.option("rowKeyColumn", ModelConfig.PROFILE_TABLE_ROWKEY_COL)
.save()
}
// 6. 关闭资源:应用结束,关闭会话实例对象
def close(): Unit = {
// 应用结束,关闭资源
if(null != spark) spark.stop()
}
// 规定标签模型执行流程顺序
def executeModel(tagId: Long, isHive: Boolean = false): Unit ={
// a. 初始化
init(isHive)
try{
// b. 获取标签数据
val tagDF: DataFrame = getTagData(tagId)
//basicTagDF.show()
tagDF.persist(StorageLevel.MEMORY_AND_DISK)
tagDF.count()
// c. 获取业务数据
val businessDF: DataFrame = getBusinessData(tagDF)
//businessDF.show()
// d. 计算标签
val modelDF: DataFrame = doTag(businessDF, tagDF)
//modelDF.show()
// e. 保存标签
if(null != modelDF) saveTag(modelDF)
tagDF.unpersist()
}catch {
case e: Exception => e.printStackTrace()
}finally {
// f. 关闭资源
close()
}
}
}测试运行
进行测试一下,将之前写好的添加job标签的类转换成实现模板标签抽象类的写法,看看有多方便:
(优化前:)
import cn.itcast.tags.meta.HBaseMeta
import cn.itcast.tags.tools.HBaseTools
import org.apache.hadoop.hbase.client.{Put, Result}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.spark.SparkConf
import org.apache.spark.internal.Logging
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 标签模型应用开发:用户职业标签
*/
object JobModel extends Logging{
/*
321 职业
322 学生 1
323 公务员 2
324 军人 3
325 警察 4
326 教师 5
327 白领 6
*/
def main(args: Array[String]): Unit = {
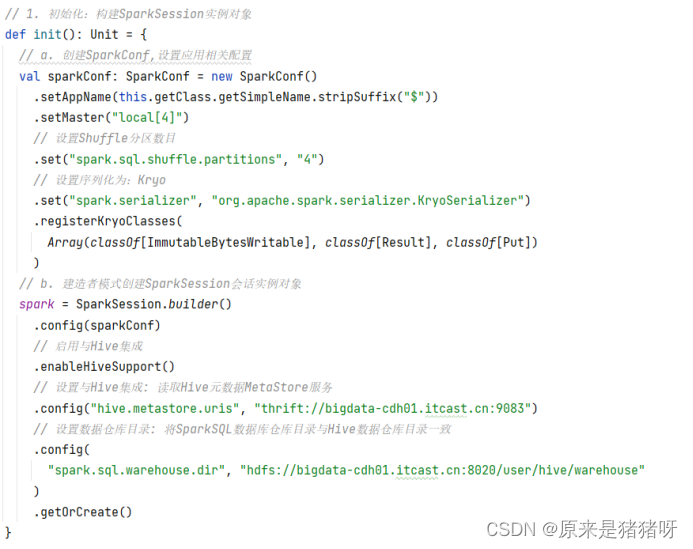
// 创建SparkSession实例对象
val spark: SparkSession = {
// a. 创建SparkConf,设置应用相关配置
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[4]")
// 设置Shuffle分区数目
.set("spark.sql.shuffle.partitions", "4")
// 设置序列化为:Kryo
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(
Array(classOf[ImmutableBytesWritable], classOf[Result], classOf[Put])
)
// b. 建造者模式创建SparkSession会话实例对象
val session = SparkSession.builder()
.config(sparkConf)
// 启用与Hive集成
.enableHiveSupport()
// 设置与Hive集成: 读取Hive元数据MetaStore服务
.config("hive.metastore.uris", "thrift://bigdata-cdh01.itcast.cn:9083")
// 设置数据仓库目录: 将SparkSQL数据库仓库目录与Hive数据仓库目录一致
.config(
"spark.sql.warehouse.dir", "hdfs://bigdata-cdh01.itcast.cn:8020/user/hive/warehouse"
)
.getOrCreate()
// c. 返回会话对象
session
}
import org.apache.spark.sql.functions._
import spark.implicits._
// 1. 依据TagId,从MySQL读取标签数据(4级业务标签和5级属性标签)
val tagTable: String =
"""
|(
|SELECT id, name, rule, level FROM profile_tags.tbl_basic_tag WHERE id = 321
|UNION
|SELECT id, name, rule, level FROM profile_tags.tbl_basic_tag WHERE pid = 321
|) AS tag_table
|""".stripMargin
val basicTagDF: DataFrame = spark.read
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url",
"jdbc:mysql://bigdata-cdh01.itcast.cn:3306/?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC")
.option("dbtable", tagTable)
.option("user", "root")
.option("password", "123456")
.load()
//basicTagDF.printSchema()
//basicTagDF.show(10, truncate = false)
// 2. 解析标签rule,从HBase读取业务数据
// 2.1 获取业务标签规则
val tagRule: String = basicTagDF
.filter($"level" === 4) // 业务标签属于4级标签
.head() // 返回Row对象
.getAs[String]("rule")
//logWarning(s"==================< $tagRule >=====================")
// 2.2 解析标签规则rule,封装值Map集合
val tagRuleMap: Map[String, String] = tagRule
// 按照换行符分割
.split("\\n")
// 再按照等号分割
.map{line =>
val Array(attrKey, attrValue) = line.trim.split("=")
(attrKey, attrValue)
}
.toMap // 转换为Map集合
logWarning(s"================= { ${tagRuleMap.mkString(", ")} } ================")
// 2.3 判断数据源inType,读取业务数据
var businessDF: DataFrame = null
if("hbase".equals(tagRuleMap("inType").toLowerCase)){
// 封装标签规则中数据源信息至HBaseMeta对象中
val hbaseMeta: HBaseMeta = HBaseMeta.getHBaseMeta(tagRuleMap)
// 从HBase表加载数据
businessDF = HBaseTools.read(
spark, hbaseMeta.zkHosts, hbaseMeta.zkPort, //
hbaseMeta.hbaseTable, hbaseMeta.family, //
hbaseMeta.selectFieldNames.split(",") //
)
}else{
// 如果未获取到数据,直接抛出异常
new RuntimeException("业务标签未提供数据源信息,获取不到业务数据,无法计算标签")
}
//businessDF.printSchema()
//businessDF.show(100, truncate = false)
// 3. 业务数据结合标属性签数据,构建标签
// 3.1 获取属性标签规则,转换为Map集合
val attrTagRuleMap: Map[String, String] = basicTagDF
.filter($"level" === 5) // 属性标签为5级标签
.select($"rule", $"name")
// 将DataFrame转换为Dataset,由于DataFrame中只有2个元素,封装值二元组(元组就是CaseClass)中
.as[(String, String)]
.rdd
.collectAsMap().toMap
val attrTagRuleMapBroadcast = spark.sparkContext.broadcast(attrTagRuleMap)
// 3.2 自定义UDF函数
val job_udf: UserDefinedFunction = udf(
(job: String) => {
attrTagRuleMapBroadcast.value(job)
}
)
// 3.3 使用UDF函数,打标签
val modelDF: DataFrame = businessDF.select(
$"id".as("userId"), //
job_udf($"job").as("job") //
)
// 4. 画像标签数据存储HBase表
HBaseTools.write(
modelDF, "bigdata-cdh01.itcast.cn", "2181", //
"tbl_profile", "user", "userId"
)
// 应用结束,关闭资源
spark.stop()
}
}(优化后:)
import cn.itcast.tags.models.{AbstractModel, ModelType}
import cn.itcast.tags.tools.TagTools
import org.apache.spark.sql.DataFrame
class JobTagModel extends AbstractModel("职业标签", ModelType.MATCH) {
/*
321 职业
322 学生 1
323 公务员 2
324 军人 3
325 警察 4
326 教师 5
327 白领 6
*/
override def doTag(businessDF: DataFrame, tagDF: DataFrame): DataFrame = {
val modelDF: DataFrame = TagTools.ruleMatchTag(
businessDF, "job", tagDF
)
modelDF.printSchema()
modelDF.show(100, truncate = false)
// 返回画像标签数据
modelDF
}
}
object JobTagModel {
def main(args: Array[String]): Unit = {
val tagModel = new JobTagModel()
tagModel.executeModel(321L, isHive = true) // 321L 标识是4级标签的tagId:321
}
}运行结果
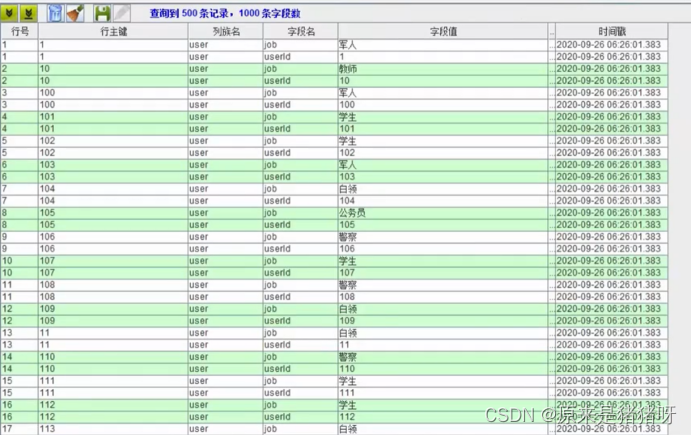
可以看到数据中已经添加入了job属性字段,说明代码没有问题,极大便利了添加标签的过程。
开发标签的小结
每个标签模型任务执行流程:
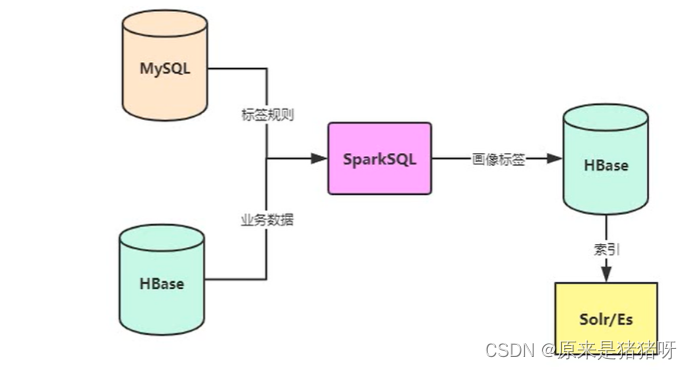
用户画像标签系统中每个标签(业务标签,4级标签)的模型开发,涉及到三种数据类型:
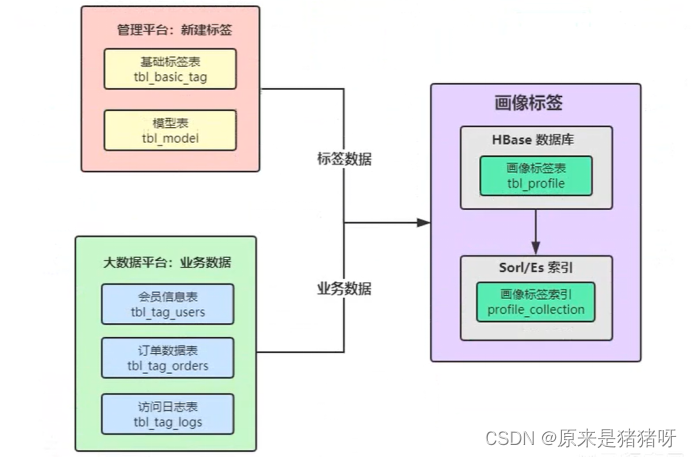
具体的数据说明:
①标签数据:
每个标签模型的开发(也就是给每个用户or每个商品打的每个标签),都必须在标签管理平台进行注册[新建标签]
业务标签(4级标签)、属性标签(5级标签)
注册完成以后,每个标签(业务标签)对应的属性值(属性标签)都会有对应的标签标识符(tagName)
属性标签ID表示具体的某个标签,标签会打在每一个用户or商品上,以标识此用户or商品
每个业务标签对应一个模型,就是一个Spark Application程序
在模型表中记录标签对应的模型关系,以及模型运行时参数信息
标签表数据(以[用户性别标签]为例,核心字段):

模型表数据(同样以[用户性别标签]为例,核心字段):

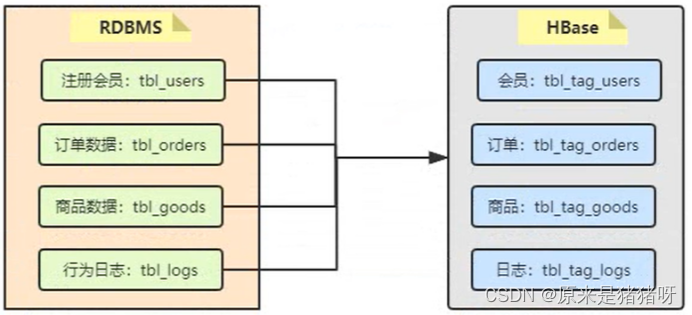
②业务数据
每个标签(业务标签,4级标签)开发,需要读取对应的业务数据,比如用户性别标签,需要读取[注册用户表]数据(获取用户的ID: id和用户性别: gender),进行打标签。
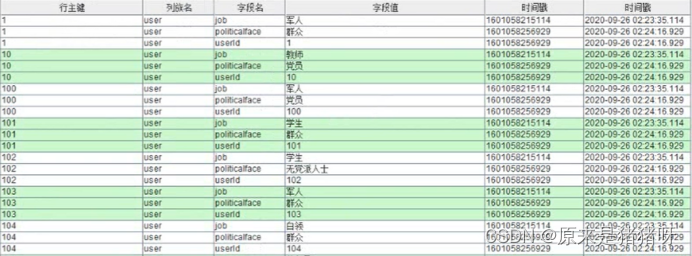
③用户标签数据
给每个用户or每个商品打上标签后,存储到HBase表中及Elasticsearch索引中,便于查询使用用户表情表名称:
自定义实现SparkSQL外部数据源HBase和统计类型标签模型开发
自定义实现SparkSQL外部数据源HBase
·在SparkSQL中提供一套完整外部数据源的接口,方便存储外部存储引擎和保存数据
·SparkSQL只提供了对MYSQL和JSON的外部数据源接口,没提供对HBase的接口,需要自己完成

会从以下8个方面进行,该内容属于Spark SQL中的高级功能:
·External DataSource
·Base Relation
·Relation Provider
·自定义HBase Relation
·自定义Default Source
·测试功能代码
·注册数据源
·修改标签基类
理论支持:
自从Spark 1.3发布,SPark SQL开始正式支持外部数据源,spark SQL开放了一系列介入外部数据源的接口:org.apache.spark.sql.sources包下的interfaces.scala
主要两个类:BaseRelation和RelationProvider
如果要实现一个外部数据源,比如HBase数据源,支持Spark SQL操作HBase数据库,那么必须定义BaseRelation和RelationProvider,同时也要定义DefaultSource实现一个RelationProvider
BaseRelation:
一个抽象的数据源
该数据源原一行行有着已知schema的数据源组成的(关系表)
展示从DataFrame中产生的底层数据源的关系或者表
定义如何产生schema信息
RelationProvider:
根据用户提供的参数返回一个数据源(就是上面的BaseRelation)
一个Relation的提供者,用以创建BaseRelation
BaseRelation:
·是一个外部数据源的抽象,里面主要存放了schema的映射

·从外部数据源加载(读取)数据和保存(写入)数据时,提供了不同的接口实现:
加载数据接口
·提供了4种Scan策略进行数据加载
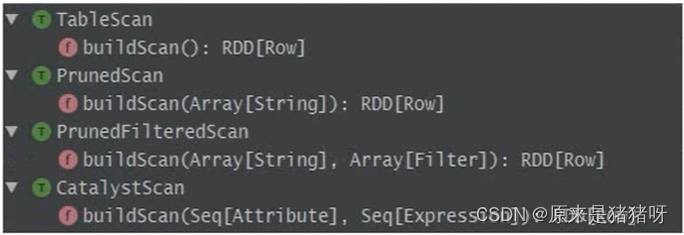
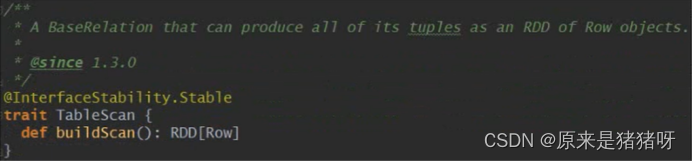
·默认的Scan为TableScan,其中方法buildScan定义了如何查询外部数据源
其他加载数据Trait的Scan说明:
PrunedScan:列裁剪,可以传入指定的列,不需要的列不会从外部数据源加载
PrunedFilteredScan:列裁剪+过滤,在列裁剪的基础上加入Filter机制,在加载数据的时候进行过滤,而不是在客户端请求返回式才做Filter
CatalystScan:Catalyst支持传入expressions来进行Scan,支持列裁剪和Filter
保存数据接口:
·InsertableRelation:保存数据的Relation

RelationProvider
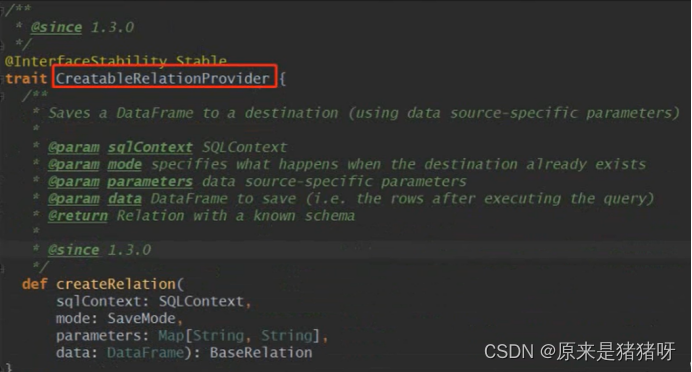
RelationProvider:获取参数列表,返回一个BaseRelation对象,要实现这个接口,需要接受传入的参数来生成对应的ExternalRelation,即一个反射生产外部数据源Relation的接口,接口Trait定义:

上述表示-加载数据时构建Relation对象的Provider为RelationProvider,同样保存数据时构建Relation对象的Provider为CreatableRelationProvider:
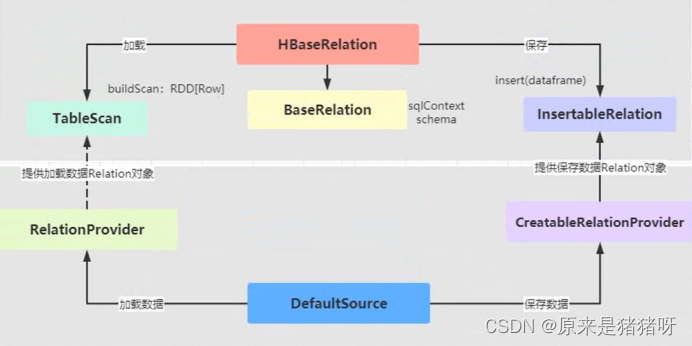
类的继承结构图:
理论基础
那么接下来,我们就按照上述接口的说明,实现自定义外部数据源从HBase表读写数据:
·定义一个类HBaseRelation,继承BaseRelation(基础数据源)、TableScan(读)、InsertableRelation(写)和Serializable(序列化)
·再定义一个类DefaultSource(默认数据源提供Relation对象,分别为加载数据和保存数据提供Relation对象),继承RelationProvider(从数据源读取数据时创建Relation对象,该Relation实现BaseRelation和TableScan)和CreatableRelationProvider(将数据集保存至数据源时,创建Relation对象,该Relation对象实现BaseRelation和InsertableRelation)
代码实现:
我们创建两个类:
·DefaultSource-默认数据源提供Relation对象,分别为加载数据和保存提供Relation对象
·HBaseRelation-自定义外部数据源:从HBase表加载数据和保存数据至HBase表的Relation实现
当有程序调用spark.read的时候,则会直接根据.format里的路径找到默认路径DefaultSource,自动执行里面的createRelation方法创建一个Relation对象
缩写(简化调用时的文件名属性):

然后执行创建函数的时候将参数进行读取以及设置,最后能返回一个relation对象,达成效果。
为方便解读,先奉上测试代码,便于理解:
测试类:
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
/**
* 测试自定义外部数据源实现从HBase表读写数据接口
*/
object HBaseSQLTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[4]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
// 读取数据
val usersDF: DataFrame = spark.read
.format("hbase") // 这里便是缩写的作用,不使用缩写则需要写完整的包名
.option("zkHosts", "bigdata-cdh01.itcast.cn")
.option("zkPort", "2181")
.option("hbaseTable", "tbl_tag_users")
.option("family", "detail")
.option("selectFields", "id,gender")
.load()
//usersDF.printSchema()
//usersDF.show(100, truncate = false)
// 保存数据
usersDF.write
.mode(SaveMode.Overwrite)
.format("hbase")
.option("zkHosts", "bigdata-cdh01.itcast.cn")
.option("zkPort", "2181")
.option("hbaseTable", "tbl_users")
.option("family", "info")
.option("rowKeyColumn", "id")
.save()
spark.stop()
}
}DefaultSource类:
import org.apache.spark.sql.{DataFrame, SQLContext, SaveMode}
import org.apache.spark.sql.sources._
import org.apache.spark.sql.types.{StringType, StructField, StructType}
/**
* 默认数据源提供Relation对象,分别为加载数据和保存提供Relation对象
*/
class DefaultSource extends RelationProvider
with CreatableRelationProvider
with DataSourceRegister{
val HBASE_TABLE_SELECT_FIELDS: String = "selectFields"
val SPERATOR: String = ","
/**
* 从数据源加载数据时,使用简称:hbase,不需要在写包名称
*/
override def shortName(): String = "hbase"
/**
* 从数据源加载读取数据时,创建Relation对象,此Relation实现BaseRelation和TableScan
* @param sqlContext SparkSession实例对象
* @param parameters 表示连接数据源时参数,通过option设置
*/
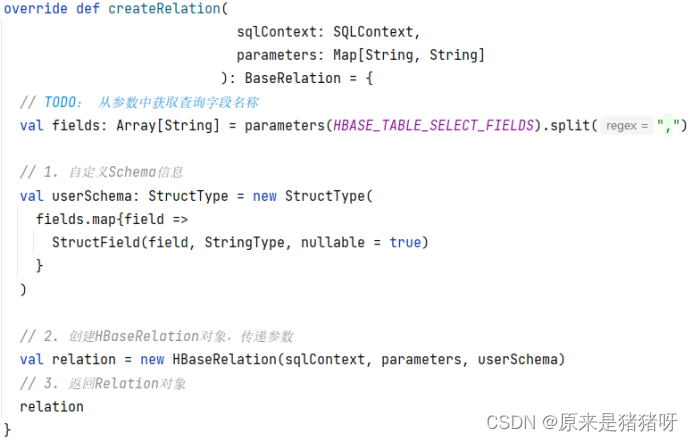
override def createRelation(
sqlContext: SQLContext,
parameters: Map[String, String]
): BaseRelation = {
//从参数的MAP中获取selectFields字符串,通过解析获取具体参数集合
val fields: Array[String] = parameters(HBASE_TABLE_SELECT_FIELDS).split(",")
// 1. 自定义Schema信息,将参数中的fields参数设置到schema中
val userSchema: StructType = new StructType(
fields.map{field =>
StructField(field, StringType, nullable = true)
}
)
// 2. 创建HBaseRelation对象,传递参数
val relation = new HBaseRelation(sqlContext, parameters, userSchema)
// 3. 返回Relation对象
relation
}
/**
* 将数据集保存至数据源时,创建Relation对象,此Relation对象实现BaseRelation和InsertableRelation
* @param sqlContext SparkSession实例对象
* @param mode 保存模式
* @param parameters 表示连接数据源时参数,通过option设置
* @param data 保存数据数据集
* @return
*/
override def createRelation(
sqlContext: SQLContext,
mode: SaveMode,
parameters: Map[String, String],
data: DataFrame
): BaseRelation = {
// 1. 创建HBaseRelation对象
val relation = new HBaseRelation(sqlContext, parameters, data.schema)
// 2. 保存数据
relation.insert(data, true)
// 3. 返回Relation对象
relation
}
}HBaseRelation类:
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{Put, Result, Scan}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat}
import org.apache.hadoop.hbase.protobuf.ProtobufUtil
import org.apache.hadoop.hbase.util.{Base64, Bytes}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.sources.{BaseRelation, InsertableRelation, TableScan}
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
/**
* 自定义外部数据源:从HBase表加载数据和保存数据至HBase表的Relation实现
*/
class HBaseRelation(
context: SQLContext,
params: Map[String, String],
userSchema: StructType
) extends BaseRelation
with TableScan with InsertableRelation with Serializable {
// 连接HBase数据库的属性名称
val HBASE_ZK_QUORUM_KEY: String = "hbase.zookeeper.quorum"
val HBASE_ZK_QUORUM_VALUE: String = "zkHosts"
val HBASE_ZK_PORT_KEY: String = "hbase.zookeeper.property.clientPort"
val HBASE_ZK_PORT_VALUE: String = "zkPort"
val HBASE_TABLE: String = "hbaseTable"
val HBASE_TABLE_FAMILY: String = "family"
val SPERATOR: String = ","
val HBASE_TABLE_SELECT_FIELDS: String = "selectFields"
val HBASE_TABLE_ROWKEY_NAME: String = "rowKeyColumn"
/**
* 表示SparkSQL加载数据和保存程序入口,相当于SparkSession
*/
override def sqlContext: SQLContext = context
/**
* 在SparkSQL中数据封装在DataFrame或者Dataset中Schema信息
*/
override def schema: StructType = userSchema
/**
* 从数据源加载数据,封装至RDD中,每条数据在Row中,结合schema信息,转换为DataFrame
*/
override def buildScan(): RDD[Row] = {
// 1. 读取配置信息,加载HBaseClient配置(主要ZK地址和端口号)
val conf: Configuration = HBaseConfiguration.create()
conf.set(HBASE_ZK_QUORUM_KEY, params(HBASE_ZK_QUORUM_VALUE))
conf.set(HBASE_ZK_PORT_KEY, params(HBASE_ZK_PORT_VALUE))
// 2. 设置表的名称
conf.set(TableInputFormat.INPUT_TABLE, params(HBASE_TABLE))
// TODO: 设置读取列簇和列名称
val scan: Scan = new Scan()
// 设置列簇
val cfBytes: Array[Byte] = Bytes.toBytes(params(HBASE_TABLE_FAMILY))
scan.addFamily(cfBytes)
// 设置列
val fields: Array[String] = params(HBASE_TABLE_SELECT_FIELDS).split(",")
fields.foreach { field =>
scan.addColumn(cfBytes, Bytes.toBytes(field))
}
// 设置Scan过滤数据: 将Scan对象转换为String
conf.set(
TableInputFormat.SCAN, //
Base64.encodeBytes(ProtobufUtil.toScan(scan).toByteArray) //
)
// 3. 从HBase表加载数据
val datasRDD: RDD[(ImmutableBytesWritable, Result)] = sqlContext.sparkContext
.newAPIHadoopRDD(
conf, //
classOf[TableInputFormat], //
classOf[ImmutableBytesWritable], //
classOf[Result]
)
// 4. 解析获取HBase表每行数据Result,封装至Row对象中
val rowsRDD: RDD[Row] = datasRDD.map { case (_, result) =>
// 基于列名称获取对应的值
val values: Seq[String] = fields.map { field =>
// 传递列名称和列簇获取value值
val value: Array[Byte] = result.getValue(cfBytes, Bytes.toBytes(field))
// 转换为字符串
Bytes.toString(value)
}
// 将Seq序列转换为Row对象
Row.fromSeq(values)
}
// 5. 返回RDD[Row]
rowsRDD
}
/**
* 将DataFrame数据保存至数据源
*
* @param data 数据集
* @param overwrite 是否覆写
*/
override def insert(data: DataFrame, overwrite: Boolean): Unit = {
// 1. 设置HBase依赖Zookeeper相关配置信息
val conf: Configuration = HBaseConfiguration.create()
conf.set(HBASE_ZK_QUORUM_KEY, params(HBASE_ZK_QUORUM_VALUE))
conf.set(HBASE_ZK_PORT_KEY, params(HBASE_ZK_PORT_VALUE))
// 2. 数据写入表的名称
conf.set(TableOutputFormat.OUTPUT_TABLE, params(HBASE_TABLE))
// 3. 将DataFrame中数据转换为RDD[(RowKey, Put)]
val cfBytes: Array[Byte] = Bytes.toBytes(params(HBASE_TABLE_FAMILY))
val columns: Array[String] = data.columns // 从DataFrame中获取列名称
val datasRDD: RDD[(ImmutableBytesWritable, Put)] = data.rdd.map { row =>
// TODO: row 每行数据 转换为 二元组(RowKey, Put)
// a. 获取RowKey值
val rowKey: String = row.getAs[String](params(HBASE_TABLE_ROWKEY_NAME))
val rkBytes: Array[Byte] = Bytes.toBytes(rowKey)
// b. 构建Put对象
val put: Put = new Put(rkBytes)
// c. 设置列值
columns.foreach { column =>
val value = row.getAs[String](column)
put.addColumn(cfBytes, Bytes.toBytes(column), Bytes.toBytes(value))
}
// d. 返回二元组
(new ImmutableBytesWritable(rkBytes), put)
}
// 4. 保存RDD数据至HBase表中
datasRDD.saveAsNewAPIHadoopFile(
s"datas/hbase/output-${System.nanoTime()}", //
classOf[ImmutableBytesWritable], //
classOf[Put], //
classOf[TableOutputFormat[ImmutableBytesWritable]], //
conf
)
}
}统计类型标签模型开发
·在实际用户表情开发中,更多标签类型属于:规则匹配类型和统计类型标签(占比约70%)
具体步骤:
·先使用业务相关字段进行统计聚合计算,这里相对简单,可以使用自带的函数完成,如:group by、avg、max、date日期函数、窗口分析函数……
·再结合属性标签规则rule进行打标签
(这部分补充再后边,待更新……)
(叠甲:该文章中大部分图以及代码源于黑马程序员,侵联删;这篇文章用于记录学习大数据的知识点,有用的就自己拿吧,没用的也别喷,自用)















 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









