






算法模型调优
接上一篇RFM大致的代码我们都已经实现了,跑也能跑出来,模型也没啥问题,或许有人就很奇怪,为什么还需要对模型进行调优?
原因诸多,其中就包含了:可能的过拟合,可能的欠拟合,或者运气好一些,数据很不错得到了还不错的模型,但是换了一组数据会发现这个模型无法适应新数据等等问题……模型就像小孩子一样,需要不断接收新事物,对旧事物的比较、推翻、重新推导的过程,只有这样才能成长的更强大。
主要原因
而进行算法调优的原因主要有以下几个方面:
①提高模型性能:算法调优的主要目的是提高模型的预测准确性、召回率、精确度等性能指标。通过调整模型的参数和结构,我们可以使模型更好地适应特定的数据集和任务,从而提升其性能。
②适应不同数据分布:不同的数据集具有不同的数据分布和特性。通过算法调优,我们可以找到最适合当前数据集的模型配置,使模型能够更好地捕捉数据的内在规律和模式。
③降低过拟合和欠拟合风险:过拟合(模型在训练数据上表现良好,但在新数据上性能较差)和欠拟合(模型无法充分学习数据的内在规律)是机器学习中的常见问题。通过算法调优,我们可以调整模型的复杂度、正则化项等参数,以降低过拟合和欠拟合的风险。
④优化计算资源:某些算法可能需要大量的计算资源来训练模型。通过算法调优,我们可以找到一种在计算资源消耗和模型性能之间取得平衡的解决方案,从而降低计算成本。
⑤满足业务需求:在实际应用中,业务需求可能不仅限于模型性能。例如,某些场景可能要求模型具有较快的推理速度或较低的内存占用。通过算法调优,我们可以调整模型的结构和参数以满足这些特定的业务需求。
⑥提升模型泛化能力:泛化能力是指模型对新数据的适应能力。通过算法调优,我们可以提高模型的泛化能力,使其能够在不同数据集和场景下都表现出良好的性能。
⑦探索和学习:算法调优本身也是一个探索和学习的过程。通过不断尝试和调整,我们可以更深入地理解模型的工作原理和性能特点,从而为自己的研究或工作积累更多的经验和知识。
如何进行算法模型调优
机器学习中算法模型调优,主要向两个方面考虑:特征数据(Features)和算法超参数(Hyper Parameters)
特征数据
特征值选择、个数
特征值转换:正则化、标准化以及归一化
算法超参数
每个算法都有不同的超参数,每个超参数的不同值都会影响最终训练的模型
注意
注意模型的过拟合(overfitting)以及欠拟合(underfitting)
(过拟合:模型在训练数据表现优异,但是在实际数据表现很差)
(欠拟合:模型在训练数据表现就很差强人意)
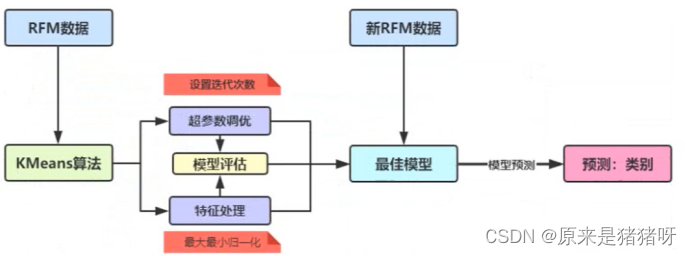
流程图
针对RFM模型中KMeans模型,应用特征处理和超参数调优,如何获取最佳模型,流程图如下:
特征数据处理
在实际项目中,尤其是线性回归算法相关模型,需要对特征数据进行归一化、标准化处理
对特征数据进行归一化或标准化处理是非常重要的。这主要是因为不同的特征可能有不同的尺度(即不同的数值范围)和单位,这可能会影响到模型的训练效率和预测性能。下面我会用通俗的方式解释这两种处理方法。
归一化(Normalization)
归一化是将特征数据的范围缩放到一个特定的范围,通常是[0, 1]。这个过程是通过将每个特征值减去该特征的最小值,然后除以该特征的取值范围(最大值减去最小值)来实现的。
例子
假设你有一个特征“年龄”,其取值范围是[18, 90]。对于某个样本,其年龄为25。经过归一化处理后,该样本的年龄值会变为 (25 - 18) / (90 - 18) = 0.097。
为什么需要归一化?
模型训练效率:很多机器学习算法在处理数据时,如果特征的尺度差异很大,可能会导致模型在训练时收敛速度变慢,因为优化器需要花费更多的时间在那些数值较大的特征上。
避免数值问题:在某些算法中,如果特征的尺度差异很大,可能会导致数值不稳定或溢出。
特征权重:归一化后,所有特征的尺度都相同,这使得模型在训练时可以更加公平地考虑每个特征的影响。
标准化(Standardization)
标准化是将特征数据转换为均值为0,标准差为1的分布。这是通过将每个特征值减去该特征的均值,然后除以该特征的标准差来实现的。
例子
假设你有一个特征“收入”,其均值为50000,标准差为10000。对于某个样本,其收入为55000。经过标准化处理后,该样本的收入值会变为 (55000 - 50000) / 10000 = 0.5。
为什么需要标准化?
算法需求:一些机器学习算法,特别是那些基于距离的算法(如KNN、SVM等),在标准化后能更好地工作,因为标准化可以消除特征之间的尺度差异,使得算法能够更准确地计算样本之间的距离。
特征权重:与归一化类似,标准化也可以使模型在训练时更加公平地考虑每个特征的影响。
正态性:标准化后,数据的分布更接近于正态分布,这对于一些基于正态分布的算法(如线性回归、逻辑回归等)是有益的。
总结
归一化和标准化都是对特征数据进行预处理的方法,它们的主要目的是消除特征之间的尺度差异,使模型在训练时更加高效和准确。在实际应用中,应该根据具体的算法和数据特点来选择合适的预处理方法。
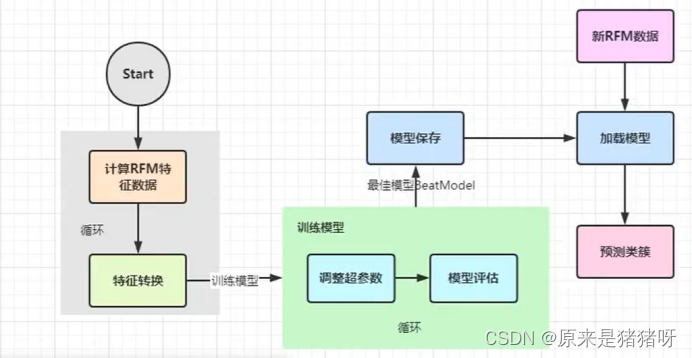
最后
当获取最佳模型以后,需要将算法模型保存(比如HDFS文件系统),当需要预测时,先判断是否存在模型,如果存在->加载模型,再使用模型进行预测;否则先训练模型,保存模型,最后在进行预测。
① 训练模型
② 加载模型
针对【客户价值模型RFM标签模型开发】整个流程图如下:
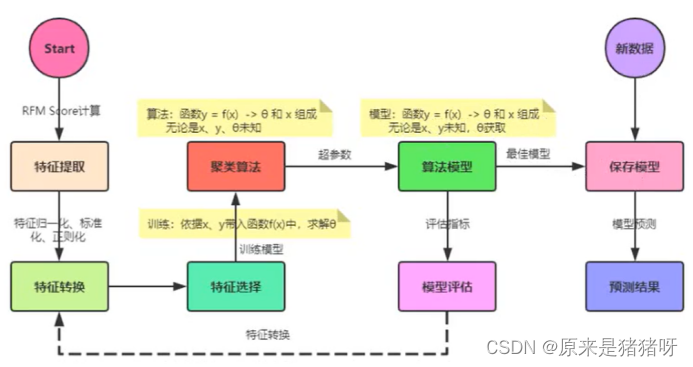
加上更详细的数值就变成这样:
代码实现
import cn.itcast.tags.config.ModelConfig
import cn.itcast.tags.models.{AbstractModel, ModelType}
import cn.itcast.tags.tools.TagTools
import cn.itcast.tags.utils.HdfsUtils
import org.apache.spark.ml.clustering.{KMeans, KMeansModel}
import org.apache.spark.ml.feature.{MinMaxScaler, MinMaxScalerModel, VectorAssembler}
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.DataTypes
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.storage.StorageLevel
/**
* 挖掘类型标签模型开发:客户价值模型RFM
*/
class RfmTagModel extends AbstractModel("客户价值RFM", ModelType.ML){
/*
361 客户价值
362 高价值 0
363 中上价值 1
364 中价值 2
365 中下价值 3
366 超低价值 4
*/
override def doTag(businessDF: DataFrame, tagDF: DataFrame): DataFrame = {
val session: SparkSession = businessDF.sparkSession
import session.implicits._
/*
root
|-- memberid: string (nullable = true)
|-- ordersn: string (nullable = true)
|-- orderamount: string (nullable = true)
|-- finishtime: string (nullable = true)
*/
//businessDF.printSchema()
//businessDF.show(10, truncate = false)
/*
root
|-- id: long (nullable = false)
|-- name: string (nullable = true)
|-- rule: string (nullable = true)
|-- level: integer (nullable = true)
*/
//tagDF.printSchema()
/*
|id |name|rule|level|
+---+----+----+-----+
|362|高价值 |0 |5 |
|363|中上价值|1 |5 |
|364|中价值 |2 |5 |
|365|中下价值|3 |5 |
|366|超低价值|4 |5 |
+---+----+----+-----+
*/
//tagDF.filter($"level" === 5).show(10, truncate = false)
/*
TODO: 1、计算每个用户RFM值
按照用户memberid分组,然后进行聚合函数聚合统计
R:消费周期,finishtime
日期时间函数:current_timestamp、from_unixtimestamp、datediff
F: 消费次数 ordersn
count
M:消费金额 orderamount
sum
*/
val rfmDF: DataFrame = businessDF
// a. 按照memberid分组,对每个用户的订单数据句话操作
.groupBy($"memberid")
.agg(
max($"finishtime").as("max_finishtime"), //
count($"ordersn").as("frequency"), //
sum(
$"orderamount".cast(DataTypes.createDecimalType(10, 2))
).as("monetary") //
)
// 计算R值
.select(
$"memberid".as("userId"), //
// 计算R值:消费周期
datediff(
current_timestamp(), from_unixtime($"max_finishtime")
).as("recency"), //
$"frequency", //
$"monetary"
)
//rfmDF.printSchema()
//rfmDF.show(10, truncate = false)
/*
TODO: 2、按照规则给RFM进行打分(RFM_SCORE)
R: 1-3天=5分,4-6天=4分,7-9天=3分,10-15天=2分,大于16天=1分
F: ≥200=5分,150-199=4分,100-149=3分,50-99=2分,1-49=1分
M: ≥20w=5分,10-19w=4分,5-9w=3分,1-4w=2分,<1w=1分
使用CASE WHEN .. WHEN... ELSE .... END
*/
// R 打分条件表达式
val rWhen = when(col("recency").between(1, 3), 5.0) //
.when(col("recency").between(4, 6), 4.0) //
.when(col("recency").between(7, 9), 3.0) //
.when(col("recency").between(10, 15), 2.0) //
.when(col("recency").geq(16), 1.0) //
// F 打分条件表达式
val fWhen = when(col("frequency").between(1, 49), 1.0) //
.when(col("frequency").between(50, 99), 2.0) //
.when(col("frequency").between(100, 149), 3.0) //
.when(col("frequency").between(150, 199), 4.0) //
.when(col("frequency").geq(200), 5.0) //
// M 打分条件表达式
val mWhen = when(col("monetary").lt(10000), 1.0) //
.when(col("monetary").between(10000, 49999), 2.0) //
.when(col("monetary").between(50000, 99999), 3.0) //
.when(col("monetary").between(100000, 199999), 4.0) //
.when(col("monetary").geq(200000), 5.0) //
val rfmScoreDF: DataFrame = rfmDF.select(
$"userId", //
rWhen.as("r_score"), //
fWhen.as("f_score"), //
mWhen.as("m_score") //
)
//rfmScoreDF.printSchema()
//rfmScoreDF.show(50, truncate = false)
/*
TODO: 3、使用RFM_SCORE进行聚类,对用户进行分组
KMeans算法,其中K=5
*/
// 3.1 组合R\F\M列为特征值features
val assembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("r_score", "f_score", "m_score"))
.setOutputCol("raw_features")
val rawFeaturesDF: DataFrame = assembler.transform(rfmScoreDF)
// 将训练数据缓存
rawFeaturesDF.persist(StorageLevel.MEMORY_AND_DISK)
// TODO: =============== 对特征数据进行处理:最大最小归一化 ================
val scalerModel: MinMaxScalerModel = new MinMaxScaler()
.setInputCol("raw_features")
.setOutputCol("features")
.fit(rawFeaturesDF)
val featuresDF: DataFrame = scalerModel.transform(rawFeaturesDF)
//featuresDF.printSchema()
//featuresDF.show(10, truncate = false)
// 3.2 使用KMeans算法聚类,训练模型
/*
val kMeansModel: KMeansModel = new KMeans()
.setFeaturesCol("features")
.setPredictionCol("prediction") // 由于K=5,所以预测值prediction范围:0,1,2,3,4
// K值设置,类簇个数
.setK(5)
.setMaxIter(20)
.setInitMode("k-means||")
// 训练模型
.fit(featuresDF)
// WSSSE = 0.9977375565642177
println(s"WSSSE = ${kMeansModel.computeCost(featuresDF)}")
*/
//val kMeansModel: KMeansModel = trainModel(featuresDF)
// 调整超参数,获取最佳模型
//val kMeansModel: KMeansModel = trainBestModel(featuresDF)
// 加载模型
val kMeansModel: KMeansModel = loadModel(featuresDF)
// 3.3. 使用模型预测
val predictionDF: DataFrame = kMeansModel.transform(featuresDF)
/*
root
|-- userId: string (nullable = true)
|-- r_score: double (nullable = true)
|-- f_score: double (nullable = true)
|-- m_score: double (nullable = true)
|-- features: vector (nullable = true)
|-- prediction: integer (nullable = true)
*/
//predictionDF.printSchema()
//predictionDF.show(50, truncate = false)
// 3.4 获取类簇中心点
val centerIndexArray: Array[((Int, Double), Int)] = kMeansModel
.clusterCenters
// 返回值类型:: Array[(linalg.Vector, Int)]
.zipWithIndex // (vector1, 0), (vector2, 1), ....
// TODO: 对每个类簇向量进行累加和:R + F + M
.map{case(clusterVector, clusterIndex) =>
// rfm表示将R + F + M之和,越大表示客户价值越高
val rfm: Double = clusterVector.toArray.sum
clusterIndex -> rfm
}
// 按照rfm值进行降序排序
.sortBy(tuple => - tuple._2)
// 再次进行拉链操作
.zipWithIndex
//centerIndexArray.foreach(println)
// TODO: 4. 打标签
// 4.1 获取属性标签规则rule和名称tagName,放在Map集合中
val rulesMap: Map[String, String] = TagTools.convertMap(tagDF)
//rulesMap.foreach(println)
// 4.2 聚类类簇关联属性标签数据rule,对应聚类类簇与标签tagName
val indexTagMap: Map[Int, String] = centerIndexArray
.map{case((centerIndex, _), index) =>
val tagName = rulesMap(index.toString)
(centerIndex, tagName)
}
.toMap
//indexTagMap.foreach(println)
// 4.3 使用KMeansModel预测值prediction打标签
// a. 将索引标签Map集合 广播变量广播出去
val indexTagMapBroadcast = session.sparkContext.broadcast(indexTagMap)
// b. 自定义UDF函数,传递预测值prediction,返回标签名称tagName
val index_to_tag: UserDefinedFunction = udf(
(clusterIndex: Int) => indexTagMapBroadcast.value(clusterIndex)
)
// c. 打标签
val modelDF: DataFrame = predictionDF.select(
$"userId", // 用户ID
index_to_tag($"prediction").as("rfm")
)
//modelDF.printSchema()
//modelDF.show(100, truncate = false)
// 返回画像标签数据
modelDF
}
/**
* 使用KMeans算法训练模型
* @param dataframe 数据集
* @return KMeansModel模型
*/
def trainModel(dataframe: DataFrame): KMeansModel = {
// 使用KMeans聚类算法模型训练
val kMeansModel: KMeansModel = new KMeans()
.setFeaturesCol("features")
.setPredictionCol("prediction")
.setK(5) // 设置列簇个数:5
.setMaxIter(20) // 设置最大迭代次数
.fit(dataframe)
println(s"WSSSE = ${kMeansModel.computeCost(dataframe)}")
// 返回
kMeansModel
}
/**
* TODO:调整KMeans算法超参数,获取最佳模型
* @param dataframe 数据集
* @return 最佳模型
*/
def trainBestModel(dataframe: DataFrame): KMeansModel = {
/*
针对KMeans聚类算法来说,超参数有哪些呢??
1. K值,采用肘部法则确定
但是对于RFM模型来说,K值确定,等于5
2. 最大迭代次数MaxIters
迭代训练模型最大次数,可以调整
*/
// TODO:模型调优方式二:调整算法超参数 -> MaxIter 最大迭代次数, 使用训练验证模式完成
// 1.设置超参数的值
val maxIters: Array[Int] = Array(10, 20, 50)
// 2.不同超参数的值,训练模型
val models: Array[(Double, KMeansModel, Int)] = maxIters.map{ maxIter =>
// a. 使用KMeans算法应用数据训练模式
val kMeans: KMeans = new KMeans()
.setFeaturesCol("features")
.setPredictionCol("prediction")
.setK(5) // 设置聚类的类簇个数
.setMaxIter(maxIter)
// b. 训练模式
val model: KMeansModel = kMeans.fit(dataframe)
// c. 模型评估指标WSSSE
val ssse = model.computeCost(dataframe)
// d. 返回三元组(评估指标, 模型, 超参数的值)
(ssse, model, maxIter)
}
models.foreach(println)
// 3.获取最佳模型
val (_, bestModel, _) = models.minBy(tuple => tuple._1)
// 4.返回最佳模型
bestModel
}
/**
* 从HDFS文件系统加载模型,当模型存在时,直接从路径加载;如果不存在,训练模型,并保存
* @param dataframe 数据集,包含字段features,类型为向量vector
* @return KMeansModel模型实例对象
*/
def loadModel(dataframe: DataFrame): KMeansModel = {
val modelPath: String = s"${ModelConfig.MODEL_BASE_PATH}/${this.getClass.getSimpleName.stripSuffix("$")}"
// 1. 判断模型是否存在:路径是否存在,如果存在,直接加载
val modelExists: Boolean = HdfsUtils.exists(
dataframe.sparkSession.sparkContext.hadoopConfiguration, //
modelPath
)
if(modelExists){
logWarning(s"================== 正在从<${modelPath}>加载模型 ==================")
// 直接加载,返回结款
KMeansModel.load(modelPath)
} else{
// 2. 如果模型不存在,首先训练模型,获取最佳模型,并保存,最后返回模型
// 2.1 训练获取最佳模型
logWarning(s"================== 正在从训练获取最佳模型 ==================")
val model: KMeansModel = trainBestModel(dataframe)
// 2.2 模型保存
logWarning(s"================== 正在保存模型至<${modelPath}> ==================")
model.save(modelPath)
// 2.3 返回最佳模型
model
}
}
}
object RfmTagModel{
def main(args: Array[String]): Unit = {
val tagModel = new RfmTagModel()
tagModel.executeModel(361L)
}
}(叠甲:大部分资料来源于黑马程序员,这里只是做一些自己的认识、思路和理解,主要是为了分享经验,如果大家有不理解的部分可以私信我,也可以移步【黑马程序员_大数据实战之用户画像企业级项目】https://www.bilibili.com/video/BV1Mp4y1x7y7?p=201&vd_source=07930632bf702f026b5f12259522cb42,以上,大佬勿喷)

















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









