






简简单单一个介绍
KMeans算法是一种无监督学习的聚类算法,它试图将数据点划分为K个集群(或称为簇),使得每个数据点都属于离其最近的均值(即聚类中心或质心)所对应的集群。KMeans算法通过迭代的方式寻找最优的聚类中心,使得每个数据点到其所属集群的聚类中心的距离之和最小。
注意:
- KMeans算法对初始聚类中心的选择很敏感,不同的初始聚类中心可能导致不同的聚类结果。为了解决这个问题,可以使用多次运行KMeans算法并选择最优结果的方法(如KMeans++或KMeans||)。
- KMeans算法中K的选择是主观的,通常需要根据数据的特性和业务需求来确定。可以使用一些评估指标(如轮廓系数、Calinski-Harabasz指数等)来帮助选择最优的K值。
- KMeans算法对噪声和异常值很敏感,因为它们可能会显著影响聚类中心的位置。在实际应用中,可能需要先对数据进行预处理,如去除噪声和异常值,或使用其他聚类算法(如DBSCAN、层次聚类等)来处理包含噪声和异常值的数据集。
算法描述:
KMeans算法又名K均值算法,其算法思想大致为:先认为集中随机选取K个样本作为簇中心,并计算所有样本与这K个“簇中心”的距离,对于每一个样本,将其划分为与其距离最近的“簇中心”所在的簇,对于新的簇,计算各个簇的新“簇中心”。
根据以上描述,KMeans的算法步骤为:

文字描述可能不太容易理解,下面我们给几个图像例子:
步骤流程图:
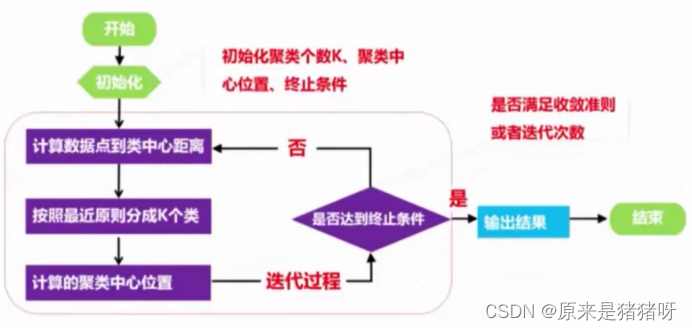
步骤抽象派作图:
形象化模型:
牧师-村民模型是K-Means的著名解释,代入再理解一下:

动画演示图:(建议科学上网)
Visualizing K-Means Clustering
不想动手也没关系,我还有图:
动画演示KMeans:
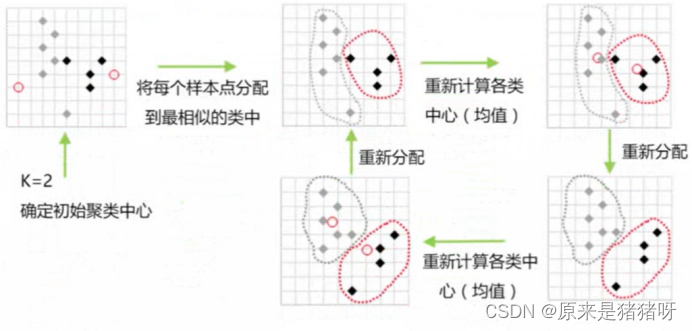
起始位置:四个簇中心点随机放置(代入模型就是牧师),白点就是村民,还未归属于任何一个簇。

第一次:(第一天,牧师在选好的地方布道,附近的村民会选择离他们最近的牧师去观看,白点变成了对应颜色的点,即归属于某个簇)
调整:(牧师根据第一天来的人的所在家位置,将簇中心的位置调整至他们家的中心位置【就比如红中心点现在就在红点的中心位置】,当牧师的位置调整后,有些人就发现:昨天去的牧师更近了,也有人发现离得更远了,还不如去另一个牧师那【也就是现在不在对应颜色区域的那些点】)
第二次:(于是乎,第二天的时候,人们依旧选择距离他们最近的牧师的位置,往后的每一天都是如此改变)
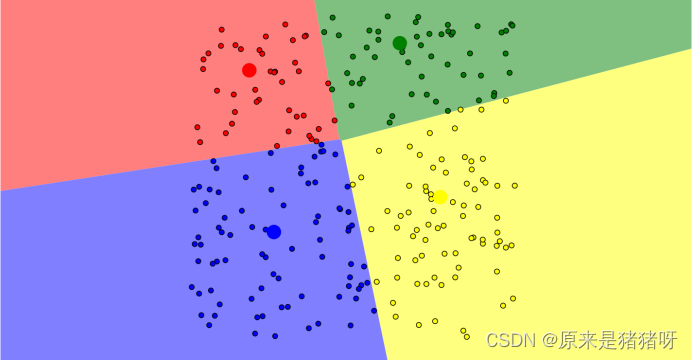
调整:

第三次:
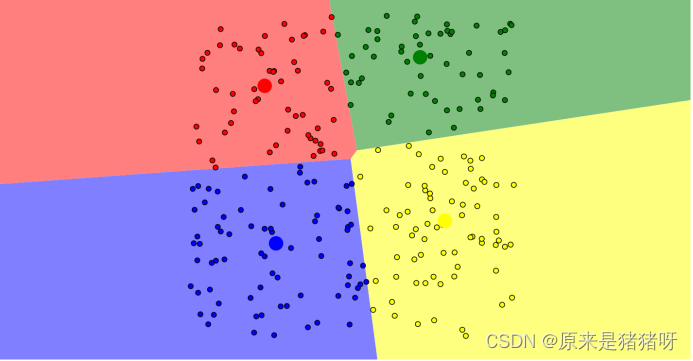
……
若干次迭代后,最终结果:
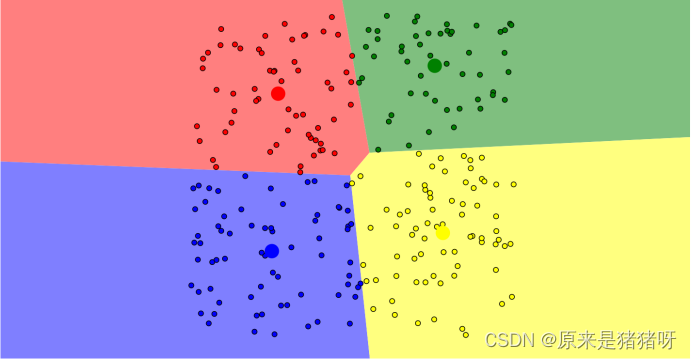
簇中心点的位置几乎不再改变,每个点也直接固定在了某个簇里,每个点都被划分到了某个簇中,得到最佳位置,对用户进行了划分!
结论:
所以,针对K-Means均值聚类算法来说,知道几个要点即可:
- K标识类簇个数,一开始随机初始化K个类簇中心点(K值的确定会讲,肘部法则,别急,我知道你很急,但你先别急,这个待会下面我再补充)
- 计算所有数据到K个类簇中心点的距离,默认使用欧氏距离,重新归属至距离最近的类簇中心点
- 对每个类簇计算新的中心点,采用均值Means方式
- 最终得到的簇划分于初始的簇中心息息相关,又因为初始簇中心点是随机选取的,所以最终求得的簇划分每一次都不一样。
KMeans聚类算法构建的模型:K个类簇中心的坐标(就是上述牧师的位置)。
KMeans聚类算法构建的任务:对数据进行预测以后,将数据归属到某个类簇中,返回K个类簇中心的坐标。
优点:
- 算法逻辑容易理解,聚类效果也还不错,虽说只是局部最佳,但往往这个局部最佳已经够用了
- 处理大数据集的时候该算法可以保证较好的伸缩性
- 当簇近似高斯分布时,效果拔群
- 算法复杂度不高
缺点:
- K(类簇数量)值需要人为设定,不同的K值得到的最终结果会不一样
- 对初始的簇中心很敏感,不同的初始值会得到不一样的结果
- 对异常值敏感
- 样本只能归为一类,无法担任多分类的任务
- 不适合过于离散的、样本类别不平衡的、非凸形状的分类
聚类模型评估:误差平方和SSE
在聚类算法中,**SSE(Sum of Squared Errors,误差平方和)**是一个重要的评估指标,用于衡量聚类效果的好坏。具体来说,SSE表示的是聚类结果中每个样本与其所在簇中心点之间的距离平方和。这个值越小,说明聚类效果越好,即数据点越紧密地聚集在它们的簇中心周围。
在K-means聚类算法中,SSE是常用的优化目标。K-means算法试图通过迭代的方式找到最优的簇中心,使得所有数据点到其所属簇中心的距离平方和最小。通过不断优化这个目标函数,K-means算法能够逐渐将数据划分为若干个紧凑的簇。
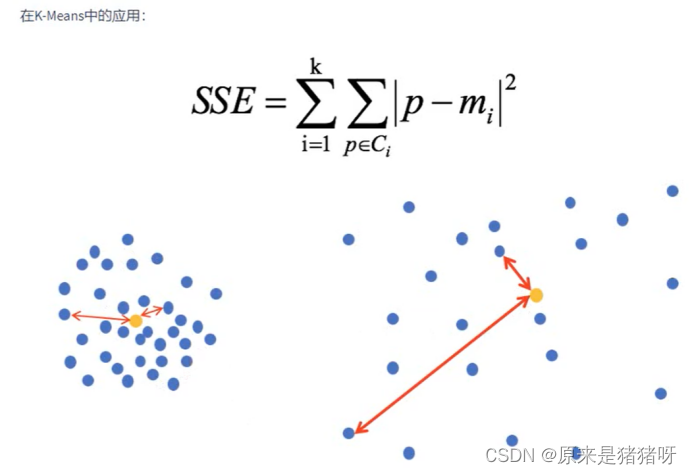
此外,SSE曲线也常用于评估聚类算法的性能和确定最佳的聚类数量。通过绘制不同聚类数量下的SSE值,可以观察SSE曲线的变化趋势,从而找到使SSE值显著降低的拐点,这个拐点通常对应着最佳的聚类数量。同时,SSE曲线还可以用于指导聚类算法的参数选择,如迭代次数、初始簇中心的选择等。
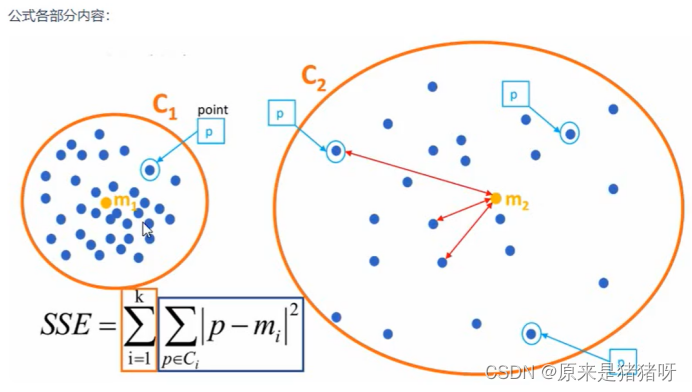
总之,SSE是聚类算法中一个重要的评估指标,它能够帮助我们了解聚类效果的好坏,并指导我们优化聚类算法和确定最佳的聚类数量。

KMeans++
产生原因
因为初始化的中心点太随机,对初始簇心比较敏感,导致结果不稳定,为了解决这个问题,就出现了KMeans++。
策略
KMeans++对初始质点的选择采取了以下策略:

用人话来说就是:
KMeans++就是选择离已选中心点最远的点,第一个在左上角,第二个点的位置就在距离第一个点最远的位置(一般都是对角距离),以保证最远距离,第三第四个点同样。这也比较符合常理,聚类中心当然是相互离得越远越好咯
但也有显而易见的缺点:由于簇中心选择过程中的内在有序性,在扩展方面存在着性能方面的问题(第k个聚类中心点的选择会依赖前k-1个聚类中心点的值)
总的来说,KMeans++会避免K个初始簇中心点聚集在一起,会充分散开
KMeans||算法
产生原因
KMeans++同样也有缺点,而KMeans||就是为了解决这个缺点而生的衍生算法,主要思想时:改变每次遍历时候的取样规则,冰凡按照KMeans++算法的 每次只取一个样本,而是每次获取K个样本,然后重复该取样操作O(logn)次(n是样本的个数),然后再将这些抽样出来的样本聚类出K个点,最后使用这K个点作为KMeans算法的初始聚簇中心点。
实践证明:一般五次重复采用就可以保证一个比较好的聚簇中心点。
策略

看完步骤,再回头看一下这个算法的名称:KMeans||,也叫做KMeans2,为啥叫这个呢?因为KMeans||算法使用了两次KMeans算法:
①使用原生态KMeans算法找K的点
②以找到K个点为初始类簇中心点,使用KMeans算法聚类

KMeans算法K值的确定
KMeans是一种非常非常常见的聚类算法,在处理聚类任务中经常用到,KMeans算法是一种原型聚类算法。那么,何为原型聚类呢?首先对原型进行初始化,然后对原型进行迭代更新求解,采用不同的原型表示、不同的求解方式将产生不同的结果。
KMeans聚类算法又叫做K均值聚类算法。对于样本集D={x1,x2,x3,……,xm},“k均值”算法就是针对聚类划分C={C1,C2,...,Ck},求最小平方误差:
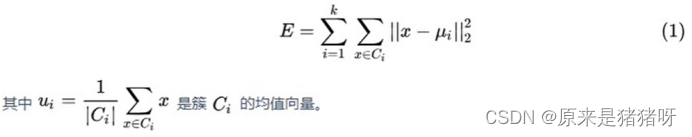
从上述公式可以看出,该公式刻画了簇内样本围绕簇均值向量的紧密程度,E值越小簇内样本相似度越高。
肘部方法
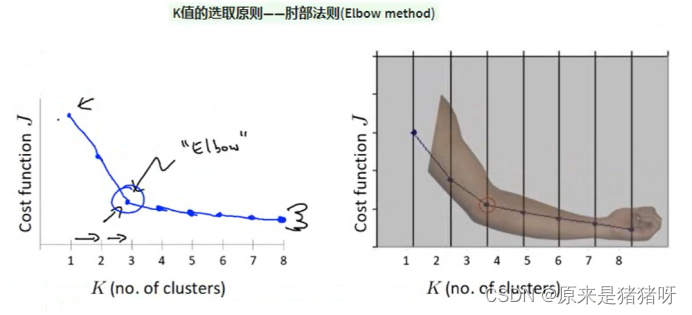
左上角的是误差平方和SSE与K值的关系图,可以看到K值越大,SSE值越小,当K值的影响对SSE影响仍然最大的点(其实也就是拐点),我们可以认为是最佳K值
- 对于n个点的数据集,迭代计算k from 1 to n,每次聚类完成后计算每个点到其所属的簇中心的距离的平方和;
- 平方和是会逐渐变小的,知道k时平方和为0,因为每个点都是它所在的簇中心本身;
- 在这个平方和变化过程中,会出现一个拐点,也就是“肘”的位置,下降率会突然变缓和的时候被认为是最佳的k值;
在决定什么时候停止训练时,肘形判据同样有效,数据通常会有更多的噪音,在增加分类无法带来更多回报时,停止增加类别。
轮廓系数法
针对聚类算法另一个评估指标,结合了聚类的凝聚度和分离度,用于评估聚类的效果:
(凝聚度:类簇之中的评估,所有点在中心点附近的程度,越聚集越好)
(分离度:类簇之间的评估,类簇之间的分散程度,约分散越好)
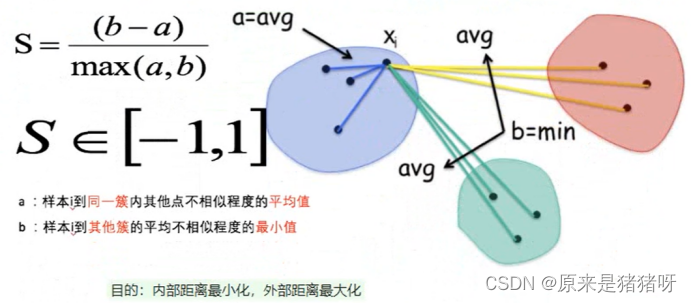
计算公式:
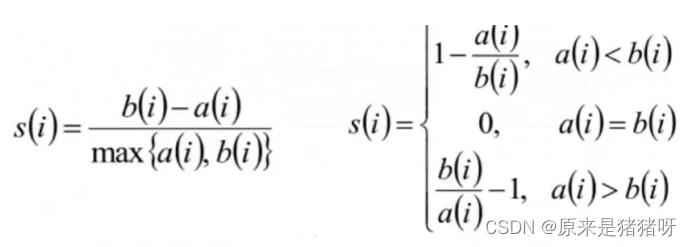
- 计算样本i到同簇其他样本的平均距离ai,ai越小样本i的簇内不相似度就越小,就越说明i应该背聚类到该簇(越说明你是他的人)
- 计算样本i到最近簇Cj的所有样本的平均距离bij,称样本i与最近簇Cj的不相似度,定义为样本i的簇间不相似度:bi = min{bi1,bi2,...,bik},bi越大,说明样本i越不属于其他簇(越说明你不是别人的人)
- 求出所有样本的轮廓系数后,再求平均值就得到了平均轮廓系数。平均轮廓系数的取值范围为[-1,1],系数越大,聚类效果越好。簇内样本的距离越近,簇间样本越远。

n_clusters分别为2,3,4,5,6时,SC系数如下,是介于[-1,1]之间的度量指标:
每次聚类后,每个样本都会得到一个轮廓系数,当它为1时,就说明这个点与周围簇的距离较远,结果非常合适;当他为0的时候,就说明最高点可能处在两个簇的边界上,当值趋近于-1时,暗含该点可能被误分了。
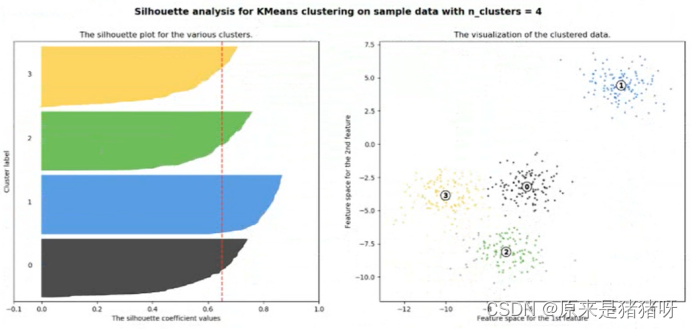
从平均SC系数结果来看,K去3,5,6是不好的,那么2和4呢?
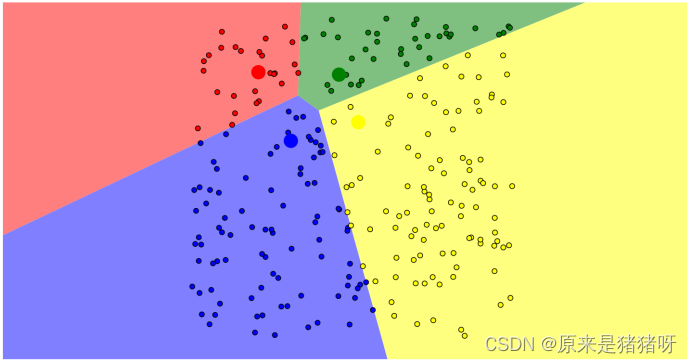
K=2的情况:n_clusters=2时,第0簇的宽度远宽于第1簇;

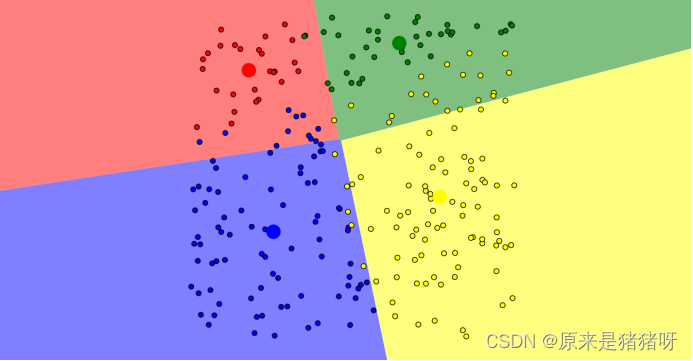
K=4的情况:n_clusters=2时,所聚的簇宽度相差不大,因此选择4作为最终聚类个数;
总结一句:轮廓系数法的作用是评估聚类效果的好坏,肘部法则的作用是选择最优聚类数目,我们最根本的目的是什么?获取一个最佳聚类效果对吧?
那么,轮廓系数法和肘部法完全可以结合使用。
① 可以通过肘部法则大致确定一个聚类数目的范围;
② 在这个范围内使用不同的聚类数目进行聚类,并计算每个聚类结果的轮廓系数;
③ 选择轮廓系数最高的聚类结果作为最终的聚类结果。
这样可以在保证聚类效果的同时,避免过多的计算成本。
(叠甲:大部分资料来源于黑马程序员,这里只是做一些自己的认识,分享经验,如果大家又不理解的部分请移步【黑马程序员_大数据实战之用户画像企业级项目】https://www.bilibili.com/video/BV1Mp4y1x7y7?p=201&vd_source=07930632bf702f026b5f12259522cb42,以上,大佬勿喷)















 1474
1474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









