






前排提示:思路篇移步用户购物性别标签,这里是进行后续调优的思路!
调优手段
针对算法模型调优来说:
第一个方法:特征数据
将特征中转化为操作,封装至管道Pipeline中
第二个方法:算法超参数
比如这对决策树分类算法来说,至少要调整三个超参数:
参数【不纯度度量】: entropy、gini
参数【树的深度】: maxDepth
参数【树的叶子数目】: maxBins
需要调整上述三个参数,找到合适的组合,训练出最佳模型
调优思路
使用决策树训练模型时,可以调整相关超参数,结合训练验证(Train-Validation Split)或交叉验证(Cross-Validation),获取最佳模型
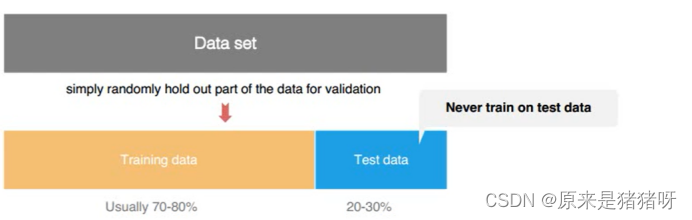
- 训练验证:训练表示使用训练数据集训练模型,验证表示使用验证数据集验证模型(评估)
将数据集划分为两个部分,静态的划分,一个用于训练模型,一个用于验证模型
通过评估指标,获取最佳模型,超参数设置比较好
- 交叉验证:将数据集动态划分为训练集和验证集
将数据集划分为两个部分,动态的划分为K个部分的数据集,其中1份数据集为验证数据集,其他K-1份数据为训练数据集,调整参数训练模型
实际项目中建议使用,但成本较高
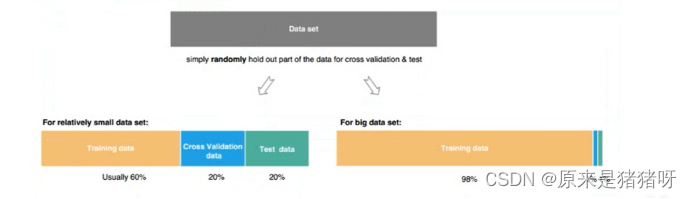
Cross Validation
无论使用何种验证方式通过调整算法超参数来进行模型调优,需要使用工具类ParamGridBuilder,将超参数封装大Map集合中,代码如下所示:
Import org.apache.spark.ml.tuning.ParamGridBuilder
Val paramGrid: Array[ParamMap] = new ParamGridBuilder()
.addGrid(lr.regParam, Array(0.1, 0.01))
.addGrid(lr.elasticNetParam, Array(0.0, 0.5, 1.0))
.build()如果使用训练验证TrainValidationSplit方式获取最佳模型,代码如下,其中需要传递模型评估器:
Val trainValidationSplit = new TrainValidationSplit()
.setEstimator(lr)
.setEvaluator(new RegressionEvaluator)
.setEstimatorParamMaps(paramGrid)
// 80%的数据将用于训练,剩下的20%用于验证
.setTrainRatio(0.8)如果式交叉验证CrossValidator方式模型调优,获取最佳模型,首先要理解何为K折交叉验证。
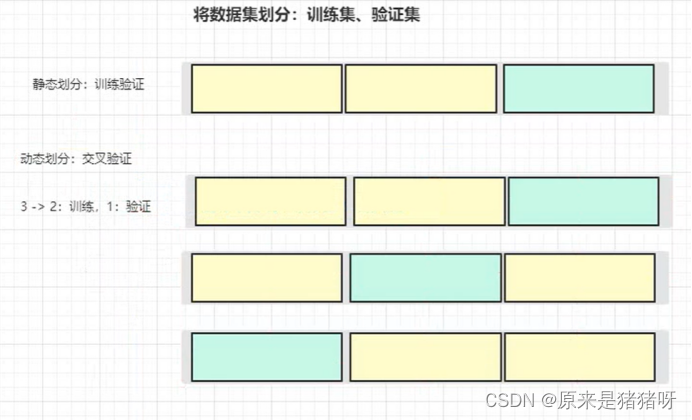
交叉验证(Cross Validation):
将拿到的训练数据分为训练和验证集。
交叉验证的目的:
为了让被评估的模型更加准确可信。
以下图为例:K = 4
将数据分成4份,其中一份作为验证集。
然后经过4次(组)的测试,每次都更换不同的验证集。
即得到4组模型的结果,取平均值作为最终结果,又称为4折交叉验证。
我们之前知道数据分为训练集和测试集,但是为了让训练得到模型结果更加准确。做以下处理:
训练集:训练集+验证集
测试集:测试集

模型工具类代码
import cn.itcast.tags.config.ModelConfig
import cn.itcast.tags.utils.HdfsUtils
import org.apache.hadoop.conf.Configuration
import org.apache.spark.internal.Logging
import org.apache.spark.ml.{Model, Pipeline, PipelineModel}
import org.apache.spark.ml.classification.{DecisionTreeClassificationModel, DecisionTreeClassifier}
import org.apache.spark.ml.clustering.{KMeans, KMeansModel}
import org.apache.spark.ml.evaluation.{BinaryClassificationEvaluator, MulticlassClassificationEvaluator}
import org.apache.spark.ml.feature.{VectorAssembler, VectorIndexer}
import org.apache.spark.ml.param.ParamMap
import org.apache.spark.ml.tuning.{CrossValidator, CrossValidatorModel, ParamGridBuilder, TrainValidationSplit, TrainValidationSplitModel}
import org.apache.spark.sql.DataFrame
import org.apache.spark.storage.StorageLevel
/**
* 算法模型工具类:专门依据数据集训练算法模型,保存及加载
*/
object MLModelTools extends Logging {
/**
* 加载模型,如果模型不存在,使用算法训练模型
* @param dataframe 训练数据集
* @param mlType 表示标签模型名称
* @return Model 模型
*/
def loadModel(dataframe: DataFrame, mlType: String, clazz: Class[_]): Model[_] = {
// 获取算法模型保存路径
val modelPath = s"${ModelConfig.MODEL_BASE_PATH}/${clazz.getSimpleName.stripSuffix("$")}"
// 1. 判断模型是否存在,存在直接加载
val conf: Configuration = dataframe.sparkSession.sparkContext.hadoopConfiguration
if(HdfsUtils.exists(conf, modelPath)){
logWarning(s"正在从【$modelPath】加载模型.................")
mlType.toLowerCase match {
case "rfm" => KMeansModel.load(modelPath) // 加载返回
case "rfe" => KMeansModel.load(modelPath) // 加载返回
case "psm" => KMeansModel.load(modelPath) // 加载返回
case "usg" => PipelineModel.load(modelPath)
}
}else{
// 2. 如果模型不存在训练模型,获取最佳模型及保存模型
logWarning(s"正在训练模型.................")
val bestModel = mlType.toLowerCase match {
case "rfm" => trainBestKMeansModel(dataframe, kClusters = 5)
case "rfe" => trainBestKMeansModel(dataframe, kClusters = 4)
case "psm" => trainBestKMeansModel(dataframe, kClusters = 5)
case "usg" => trainBestPipelineModel(dataframe)
}
// 保存模型
logWarning(s"保存最佳模型.................")
bestModel.save(modelPath)
// 返回模型
bestModel
}
}
/**
* 调整算法超参数,获取最佳模型
* @param dataframe 数据集
* @return
*/
def trainBestKMeansModel(dataframe: DataFrame, kClusters: Int): KMeansModel = {
// TODO:模型调优方式二:调整算法超参数 -> MaxIter 最大迭代次数, 使用训练验证模式完成
// 1.设置超参数的值
val maxIters: Array[Int] = Array(5, 10, 20)
// 2.不同超参数的值,训练模型
dataframe.persist(StorageLevel.MEMORY_AND_DISK)
val models: Array[(Double, KMeansModel, Int)] = maxIters.map{ maxIter =>
// a. 使用KMeans算法应用数据训练模式
val kMeans: KMeans = new KMeans()
.setFeaturesCol("features")
.setPredictionCol("prediction")
.setK(kClusters) // 设置聚类的类簇个数
.setMaxIter(maxIter)
.setSeed(31) // 实际项目中,需要设置值
// b. 训练模式
val model: KMeansModel = kMeans.fit(dataframe)
// c. 模型评估指标WSSSE
val ssse = model.computeCost(dataframe)
// d. 返回三元组(评估指标, 模型, 超参数的值)
(ssse, model, maxIter)
}
dataframe.unpersist()
models.foreach(println)
// 3.获取最佳模型
val (_, bestModel, _) = models.minBy(tuple => tuple._1)
// 4.返回最佳模型
bestModel
}
/**
* 采用K-Fold交叉验证方式,调整超参数获取最佳PipelineModel模型
* @param dataframe 数据集
* @return
*/
def trainBestPipelineModel(dataframe: DataFrame): PipelineModel = {
// a. 特征向量化
val assembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("color", "product"))
.setOutputCol("raw_features")
// b. 类别特征进行索引
val vectorIndexer: VectorIndexer = new VectorIndexer()
.setInputCol("raw_features")
.setOutputCol("features")
.setMaxCategories(30)
// c. 构建决策树分类器
val dtc: DecisionTreeClassifier = new DecisionTreeClassifier()
.setFeaturesCol("features")
.setLabelCol("label")
.setPredictionCol("prediction")
// 构建Pipeline管道对象,组合模型学习器(算法)和转换器(模型)
val pipeline: Pipeline = new Pipeline()
.setStages(Array(assembler, vectorIndexer, dtc))
// TODO: 创建网格参数对象实例,设置算法中超参数的值
val paramGrid: Array[ParamMap] = new ParamGridBuilder()
.addGrid(dtc.impurity, Array("gini", "entropy"))
.addGrid(dtc.maxDepth, Array(5, 10))
.addGrid(dtc.maxBins, Array(32, 64))
.build()
// f. 多分类评估器
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
// 指标名称,支持:f1、weightedPrecision、weightedRecall、accuracy
.setMetricName("accuracy")
// TODO: 创建交叉验证实例对象,设置算法、评估器和数据集占比
val cv: CrossValidator = new CrossValidator()
.setEstimator(pipeline) // 设置算法,此处为管道
.setEvaluator(evaluator) // 设置模型评估器
.setEstimatorParamMaps(paramGrid) // 设置算法超参数
// TODO: 将数据集划分为K份,其中1份为验证数据集,其余K-1份为训练收集,通常K>=3
.setNumFolds(3)
// 传递数据集,训练模型
val cvModel: CrossValidatorModel = cv.fit(dataframe)
// TODO: 获取最佳模型
val pipelineModel: PipelineModel = cvModel.bestModel.asInstanceOf[PipelineModel]
// 返回获取最佳模型
pipelineModel
}
}USG通过调优后的代码
import cn.itcast.tags.models.{AbstractModel, ModelType}
import cn.itcast.tags.tools.{MLModelTools, TagTools}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.{DecisionTreeClassificationModel, DecisionTreeClassifier}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{VectorAssembler, VectorIndexer, VectorIndexerModel}
import org.apache.spark.ml.param.ParamMap
import org.apache.spark.ml.tuning.{ParamGridBuilder, TrainValidationSplit, TrainValidationSplitModel}
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.{Column, DataFrame, SparkSession}
import org.apache.spark.sql.functions._
/**
* 挖掘类型标签模型开发:用户购物性别标签模型
*/
class UsgTagModel extends AbstractModel("用户购物性别USG", ModelType.ML){
/*
378 用户购物性别
379 男 0
380 女 1
381 中性 -1
*/
override def doTag(businessDF: DataFrame, tagDF: DataFrame): DataFrame = {
val session: SparkSession = businessDF.sparkSession
import session.implicits._
/*
root
|-- cordersn: string (nullable = true)
|-- ogcolor: string (nullable = true)
|-- producttype: string (nullable = true)
*/
//businessDF.printSchema()
//businessDF.show(10, truncate = false)
//tagDF.printSchema()
/*
+---+----+----+-----+
|id |name|rule|level|
+---+----+----+-----+
|379|男 |0 |5 |
|380|女 |1 |5 |
|381|中性 |-1 |5 |
+---+----+----+-----+
*/
//tagDF.filter($"level".equalTo(5)).show(10, truncate = false)
// 1. 获取订单表数据tbl_tag_orders,与订单商品表数据关联获取会员ID
val ordersDF: DataFrame = spark.read
.format("hbase")
.option("zkHosts", "bigdata-cdh01.itcast.cn")
.option("zkPort", "2181")
.option("hbaseTable", "tbl_tag_orders")
.option("family", "detail")
.option("selectFields", "memberid,ordersn")
.load()
//ordersDF.printSchema()
//ordersDF.show(10, truncate = false)
// 2. 加载维度表数据:tbl_dim_colors(颜色)、tbl_dim_products(产品)
// 2.1 加载颜色维度表数据
val colorsDF: DataFrame = {
spark.read
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url",
"jdbc:mysql://bigdata-cdh01.itcast.cn:3306/?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC")
.option("dbtable", "profile_tags.tbl_dim_colors")
.option("user", "root")
.option("password", "123456")
.load()
}
/*
root
|-- id: integer (nullable = false)
|-- color_name: string (nullable = true)
*/
//colorsDF.printSchema()
//colorsDF.show(30, truncate = false)
// 2.2. 构建颜色WHEN语句
val colorColumn: Column = {
// 声明变量
var colorCol: Column = null
colorsDF
.as[(Int, String)].rdd
.collectAsMap()
.foreach{case (colorId, colorName) =>
if(null == colorCol){
colorCol = when($"ogcolor".equalTo(colorName), colorId)
}else{
colorCol = colorCol.when($"ogcolor".equalTo(colorName), colorId)
}
}
colorCol = colorCol.otherwise(0).as("color")
// 返回
colorCol
}
// 2.3 加载商品维度表数据
val productsDF: DataFrame = {
spark.read
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url",
"jdbc:mysql://bigdata-cdh01.itcast.cn:3306/?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC")
.option("dbtable", "profile_tags.tbl_dim_products")
.option("user", "root")
.option("password", "123456")
.load()
}
/*
root
|-- id: integer (nullable = false)
|-- product_name: string (nullable = true)
*/
//productsDF.printSchema()
///productsDF.show(30, truncate = false)
// 2.4. 构建商品类别WHEN语句
var productColumn: Column = {
// 声明变量
var productCol: Column = null
productsDF
.as[(Int, String)].rdd
.collectAsMap()
.foreach{case (productId, productName) =>
if(null == productCol){
productCol = when($"producttype".equalTo(productName), productId)
}else{
productCol = productCol.when($"producttype".equalTo(productName), productId)
}
}
productCol = productCol.otherwise(0).as("product")
// 返回
productCol
}
// 2.5. 根据运营规则标注的部分数据
val labelColumn: Column = {
when($"ogcolor".equalTo("樱花粉")
.or($"ogcolor".equalTo("白色"))
.or($"ogcolor".equalTo("香槟色"))
.or($"ogcolor".equalTo("香槟金"))
.or($"productType".equalTo("料理机"))
.or($"productType".equalTo("挂烫机"))
.or($"productType".equalTo("吸尘器/除螨仪")), 1) //女
.otherwise(0)//男
.alias("label")//决策树预测label
}
// 3. 关联订单数据,颜色维度和商品类别维度数据
val goodsDF: DataFrame = businessDF
// 关联订单数据:
.join(ordersDF, businessDF("cordersn") === ordersDF("ordersn"))
// 选择所需字段,使用when判断函数
.select(
$"memberid".as("userId"), //
colorColumn, // 颜色ColorColumn
productColumn, // 产品类别ProductColumn
// 依据规则标注商品性别
labelColumn
)
//goodsDF.printSchema()
//goodsDF.show(100, truncate = false)
// TODO: 直接使用标注数据,给用户打标签
//val predictionDF: DataFrame = goodsDF.select($"userId", $"label".as("prediction"))
// TODO: 实际上,需要使用标注数据(给每个用户购买每个商品打上性别字段),构建算法模型,并使用模型预测值性别字段值
//val featuresDF: DataFrame = featuresTransform(goodsDF)
//val dtcModel: DecisionTreeClassificationModel = trainModel(featuresDF)
//val predictionDF: DataFrame = dtcModel.transform(featuresDF)
// TODO: 使用数据集训练管道模型PipelineModel
//val pipelineModel: PipelineModel = trainPipelineModel(goodsDF)
//val predictionDF: DataFrame = pipelineModel.transform(goodsDF)
// TODO: 使用训练验证分割方式,设置超参数训练处最佳模型
//val pipelineModel: PipelineModel = trainBestModel(goodsDF)
//val predictionDF: DataFrame = pipelineModel.transform(goodsDF)
// TODO: 使用交叉验证方式,设置超参数训练获取最佳模型
/*
当模型存在时,直接加载模型;如果不存在,训练获取最佳模型,并保存
*/
val pipelineModel: PipelineModel = MLModelTools.loadModel(
goodsDF, "usg", this.getClass
).asInstanceOf[PipelineModel]
val predictionDF: DataFrame = pipelineModel.transform(goodsDF)
// 4. 按照用户ID分组,统计每个用户购物男性或女性商品个数及占比
val genderDF: DataFrame = predictionDF
.groupBy($"userId")
.agg(
count($"userId").as("total"), // 某个用户购物商品总数
// 判断label为0时,表示为男性商品,设置为1,使用sum函数累加
sum(
when($"prediction".equalTo(0), 1).otherwise(0)
).as("maleTotal"),
// 判断label为1时,表示为女性商品,设置为1,使用sum函数累加
sum(
when($"prediction".equalTo(1), 1).otherwise(0)
).as("femaleTotal")
)
/*
root
|-- userId: string (nullable = true)
|-- total: long (nullable = false)
|-- maleTotal: long (nullable = true)
|-- femaleTotal: long (nullable = true)
*/
//genderDF.printSchema()
//genderDF.show(10, truncate = false)
// 5. 计算标签
// 5.1 获取属性标签:tagRule和tagName
val rulesMap: Map[String, String] = TagTools.convertMap(tagDF)
val rulesMapBroadcast: Broadcast[Map[String, String]] = session.sparkContext.broadcast(rulesMap)
// 5.2 自定义UDF函数,计算占比,确定标签值
// 对每个用户,分别计算男性商品和女性商品占比,当占比大于等于0.6时,确定购物性别
val gender_tag_udf: UserDefinedFunction = udf(
(total: Long, maleTotal: Long, femaleTotal: Long) => {
// 计算占比
val maleRate: Double = maleTotal / total.toDouble
val femaleRate: Double = femaleTotal / total.toDouble
if(maleRate >= 0.6){ // usg = 男性
rulesMapBroadcast.value("0")
}else if(femaleRate >= 0.6){ // usg =女性
rulesMapBroadcast.value("1")
}else{ // usg = 中性
rulesMapBroadcast.value("-1")
}
}
)
// 5.3 获取画像标签数据
val modelDF: DataFrame = genderDF
.select(
$"userId", //
gender_tag_udf($"total", $"maleTotal", $"femaleTotal").as("usg")
)
//modelDF.printSchema()
//modelDF.show(100, truncate = false)
// 返回画像标签数据
modelDF
}
/**
* 针对数据集进行特征工程:特征提取、特征转换及特征选择
* @param dataframe 数据集
* @return 数据集,包含特征列features: Vector类型和标签列label
*/
def featuresTransform(dataframe: DataFrame): DataFrame = {
/*
// 1. 提取特征,封装值features向量中
// 2. 将标签label索引化
// 3. 将类别特征索引化
*/
// a. 特征向量化
val assembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("color", "product"))
.setOutputCol("raw_features")
val df1: DataFrame = assembler.transform(dataframe)
// b. 类别特征进行索引
val vectorIndexer: VectorIndexerModel = new VectorIndexer()
.setInputCol("raw_features")
.setOutputCol("features")
.setMaxCategories(30)
.fit(df1)
val df2: DataFrame = vectorIndexer.transform(df1)
// c. 返回特征数据
df2
}
/**
* 使用决策树分类算法训练模型,返回DecisionTreeClassificationModel模型
* @return
*/
def trainModel(dataframe: DataFrame): DecisionTreeClassificationModel = {
// a. 数据划分为训练数据集和测试数据集
val Array(trainingDF, testingDF) = dataframe.randomSplit(Array(0.8, 0.2), seed = 123L)
// b. 构建决策树分类器
val dtc: DecisionTreeClassifier = new DecisionTreeClassifier()
.setFeaturesCol("features")
.setLabelCol("label")
.setPredictionCol("prediction")
.setImpurity("gini") // 基尼系数
.setMaxDepth(5) // 树的深度
.setMaxBins(32) // 树的叶子数目
// c. 训练模型
logWarning("正在训练模型...................................")
val dtcModel: DecisionTreeClassificationModel = dtc.fit(trainingDF)
// d. 模型评估
val predictionDF: DataFrame = dtcModel.transform(testingDF)
println(s"accuracy = ${modelEvaluate(predictionDF, "accuracy")}")
// e. 返回模型
dtcModel
}
/**
* 模型评估,返回计算分类指标值
* @param dataframe 预测结果的数据集
* @param metricName 分类评估指标名称,支持:f1、weightedPrecision、weightedRecall、accuracy
* @return
*/
def modelEvaluate(dataframe: DataFrame, metricName: String): Double = {
// a. 构建多分类分类器
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
// 指标名称,
.setMetricName(metricName)
// b. 计算评估指标
val metric: Double = evaluator.evaluate(dataframe)
// c. 返回指标
metric
}
/**
* 使用决策树分类算法训练模型,返回PipelineModel模型
* @return
*/
def trainPipelineModel(dataframe: DataFrame): PipelineModel = {
// 数据划分为训练数据集和测试数据集
val Array(trainingDF, testingDF) = dataframe.randomSplit(Array(0.8, 0.2), seed = 123)
// a. 特征向量化
val assembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("color", "product"))
.setOutputCol("raw_features")
// b. 类别特征进行索引
val vectorIndexer: VectorIndexer = new VectorIndexer()
.setInputCol("raw_features")
.setOutputCol("features")
.setMaxCategories(30)
// c. 构建决策树分类器
val dtc: DecisionTreeClassifier = new DecisionTreeClassifier()
.setFeaturesCol("features")
.setLabelCol("label")
.setPredictionCol("prediction")
.setImpurity("gini") // 基尼系数
.setMaxDepth(5) // 树的深度
.setMaxBins(32) // 树的叶子数目
// TODO: 构建Pipeline管道对象,组合模型学习器(算法)和转换器(模型)
val pipeline: Pipeline = new Pipeline()
.setStages(Array(assembler, vectorIndexer, dtc))
// 训练模型,使用训练数据集
val pipelineModel: PipelineModel = pipeline.fit(trainingDF)
// f. 模型评估
val predictionDF: DataFrame = pipelineModel.transform(testingDF)
predictionDF.show(100, truncate = false)
println(s"accuracy = ${modelEvaluate(predictionDF, "accuracy")}")
// 返回模型
pipelineModel
}
/**
* 调整算法超参数,找出最优模型
* @param dataframe 数据集
* @return
*/
def trainBestModel(dataframe: DataFrame): PipelineModel = {
// a. 特征向量化
val assembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("color", "product"))
.setOutputCol("raw_features")
// b. 类别特征进行索引
val vectorIndexer: VectorIndexer = new VectorIndexer()
.setInputCol("raw_features")
.setOutputCol("features")
.setMaxCategories(30)
// c. 构建决策树分类器
val dtc: DecisionTreeClassifier = new DecisionTreeClassifier()
.setFeaturesCol("features")
.setLabelCol("label")
.setPredictionCol("prediction")
.setImpurity("gini") // 基尼系数
.setMaxDepth(5) // 树的深度
.setMaxBins(32) // 树的叶子数目
// 构建Pipeline管道对象,组合模型学习器(算法)和转换器(模型)
val pipeline: Pipeline = new Pipeline()
.setStages(Array(assembler, vectorIndexer, dtc))
// TODO: 创建网格参数对象实例,设置算法中超参数的值
val paramGrid: Array[ParamMap] = new ParamGridBuilder()
.addGrid(dtc.impurity, Array("gini", "entropy"))
.addGrid(dtc.maxDepth, Array(5, 10))
.addGrid(dtc.maxBins, Array(32, 64))
.build()
// f. 多分类评估器
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
// 指标名称,支持:f1、weightedPrecision、weightedRecall、accuracy
.setMetricName("accuracy")
// TODO: 创建训练验证分割实例对象,设置算法、评估器和数据集占比
val trainValidationSplit = new TrainValidationSplit()
.setEstimator(pipeline) // 算法,应用数据训练获取模型
.setEvaluator(evaluator) // 评估器,对训练模型进行评估
.setEstimatorParamMaps(paramGrid) // 算法超参数,自动组合算法超参数,训练模型并评估,获取最佳模型
// 80% of the data will be used for training and the remaining 20% for validation.
.setTrainRatio(0.8)
// 传递数据集,训练模型
val splitModel: TrainValidationSplitModel = trainValidationSplit.fit(dataframe)
// TODO: 获取最佳模型
val pipelineModel: PipelineModel = splitModel.bestModel.asInstanceOf[PipelineModel]
// 返回获取最佳模型
pipelineModel
}
}
object UsgTagModel {
def main(args: Array[String]): Unit = {
val tagModel = new UsgTagModel()
tagModel.executeModel(378L)
}
}(叠甲:大部分资料来源于黑马程序员,这里只是做一些自己的认识、思路和理解,主要是为了分享经验,如果大家有不理解的部分可以私信我,也可以移步【黑马程序员_大数据实战之用户画像企业级项目】https://www.bilibili.com/video/BV1Mp4y1x7y7?p=201&vd_source=07930632bf702f026b5f12259522cb42,以上,大佬勿喷)















 2330
2330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









