







 本文详细介绍了一种利用Python爬虫技术从京东网站抓取商品数据的方法,包括构造搜索URL、解析商品列表、筛选关键信息及存储数据。通过具体实例展示了如何获取商品标题、价格、店铺名称和链接。
本文详细介绍了一种利用Python爬虫技术从京东网站抓取商品数据的方法,包括构造搜索URL、解析商品列表、筛选关键信息及存储数据。通过具体实例展示了如何获取商品标题、价格、店铺名称和链接。
利用Python爬取京东任意商品数据
今天给大家展示爬取京东商品数据
首先呢还是要分思路的,我分为以下几个步骤:
第一步:得到搜索指定商的url
第二步:获得搜索商品列表信息
第三步:对得到的商品数据进行分析筛选
第四步:保存筛选后的数据
第一步:
进入京东官网后,比如搜索手机,F12打开开发者工具,进行抓包,发现以下是我们所需要的:
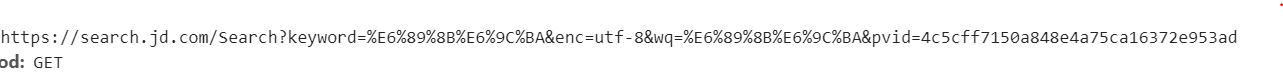
也就是
https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&wq=%E6%89%8B%E6%9C%BA&pvid=4c5cff7150a848e4a75ca16372e953ad
很显然,其中一些参数去掉也无妨,那就测试一下,发现如果是只剩下
https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA
时,得到的搜索结果并不是手机而是乱码,所以必须吧enc=utf-8给加上,其实这个就是编码格式问题,最终的精简url为
https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8
keyword中就是“手机”这个字符经过utf-8编码后的字符,那么第一步就结束了
第二步:
这一步就是要获取众多商品列表了,通过审查元素即可得到商品列表是在这:
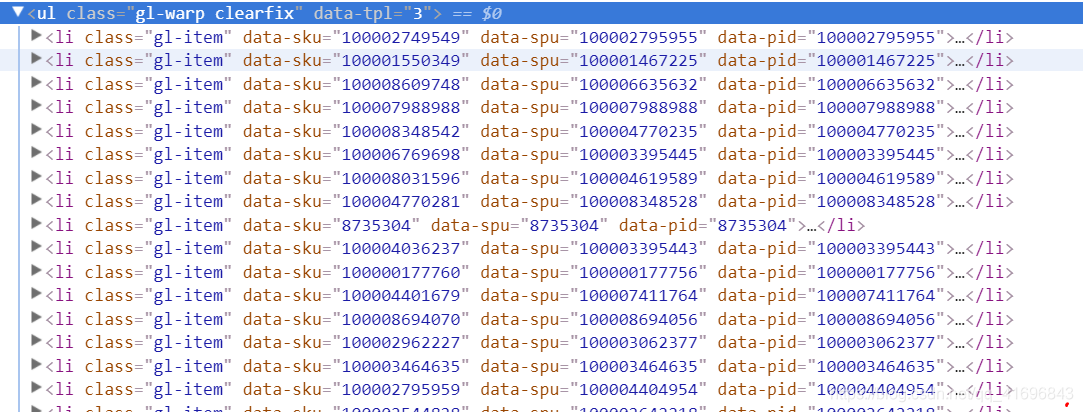
既然知道数据在哪,那么我就用xpath(正则、bs4都可以哟)来进行获取,代码如下:
shangpin_list = res.xpath('//ul[@class="gl-warp clearfix"]/li')
第三步:
既然得到了列表,那么我们就要对数据进行筛选,首先我们先获得商品标题吧,发现其商品标题在下面这个位置(以后有钱了我也要买个T.T):
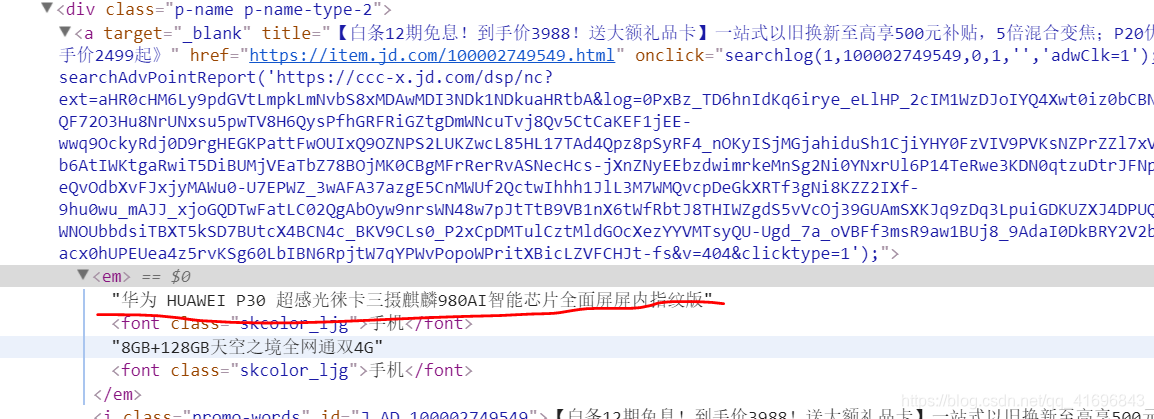
我们可以用xpath进行筛选出来,代码如下:
name = message.xpath('div[@class="gl-i-wrap"]/div[@class="p-name p-name-type-2"]/a/em/text()')
即可得到本页面所有关于搜索“手机”关键字的商品标题,同样的方法,也可以找到商品价格、店铺名称、链接等,代码如下:
价格:
price = message.xpath('div[@class="gl-i-wrap"]/div[@class="p-price"]/strong/i/text()')
店铺名称:
shopname = message.xpath('div[@class="gl-i-wrap"]/div[@class="p-shop"]/span/a/@title')
注意:在爬取店铺信息时会出现以下情况:
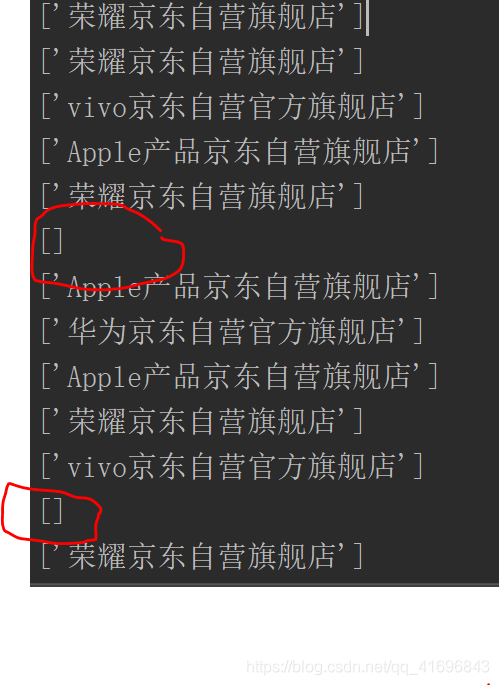
这是爬虫失误了么,其实并不是,仔细对比发现这些值为空的都是京东官方旗舰店的店铺,所以在这里需要自己手动加个判断哟
商品链接:
href = message.xpath('div[@class="gl-i-wrap"]/div[@class="p-name p-name-type-2"]/a/@href')
将这些数据我为了方便就将其存入一个字典,方便存储嘛哈哈,那么第三步就完成了。
第四步:
到了最后的存储环节了是不是贼激动,这里我用with对数据进行存储,代码如下:
def save_message(message_dict):
for message in message_dict:
with open("D:\英雄时刻\{name}.txt".format(name="京东商品"),"a",encoding="utf-8") as f:
f.write("价格:"+message["price"]+" 链接:"+message["href"]+" 店铺名称:"+message["shopname"]+" 商品标题:"+message["name"]+"\n")
那么爬取京东商品数据到这就完毕了,当然,在此基础上还可以用for循环进行指定商品关键字下的多个页面的数据收集,最好带上代理IP哟。
该总结仅用于交流研究使用,请勿用于违法行为哟,不然会被进场叔叔请去喝茶的,哈哈,最后还是老样子,上完整代码:
import requests
from lxml import html
from urllib.parse import quote #编码转换函数
def change_name(name):#编码转换
cname = quote(name,encoding="utf-8")
return cname
#手机经过utf-8编码为:%E6%89%8B%E6%9C%BA
def get_allmessage(names):#
cname = change_name(names)
url = "https://search.jd.com/Search?keyword="+cname+"&enc=utf-8"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"}
response = requests.get(url,headers=header)
response.encoding = "utf-8"
res = html.fromstring(response.text)
shangpin_list = res.xpath('//ul[@class="gl-warp clearfix"]/li')
print(len(shangpin_list))
get_message(shangpin_list)
def get_message(shangpin_list):#数据筛选
message_dict = []
for message in shangpin_list:
name = message.xpath('div[@class="gl-i-wrap"]/div[@class="p-name p-name-type-2"]/a/em/text()')
#print(name[0])
price = message.xpath('div[@class="gl-i-wrap"]/div[@class="p-price"]/strong/i/text()')
if price == []:
price = ["预约中"]
#print(price[0])
shopname = message.xpath('div[@class="gl-i-wrap"]/div[@class="p-shop"]/span/a/@title')
#print(shopname[0])
href = message.xpath('div[@class="gl-i-wrap"]/div[@class="p-name p-name-type-2"]/a/@href')
#print(href[0])
if shopname == []:
message_dict.append({
"name":name[0],
"price":price[0],
"shopname":'京东官方旗舰店',
"href":href[0]
})
else:
message_dict.append({
"name": name[0],
"price": price[0],
"shopname": shopname[0],
"href": "https:"+href[0]
})
save_message(message_dict)
def save_message(message_dict):#数据的存储
for message in message_dict:
with open("D:\英雄时刻\{name}.txt".format(name="京东商品"),"a",encoding="utf-8") as f:
f.write("价格:"+message["price"]+" 链接:"+message["href"]+" 店铺名称:"+message["shopname"]+" 商品标题:"+message["name"]+"\n")
if __name__ == "__main__":
name = input("请输入商品名称:")
get_allmessage(name)

















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









