






 该论文提出了一种利用深度学习获取嵌入特征,然后通过简单聚类方法进行语音分割和分离的技术。通过训练神经网络以产生紧凑的簇,可以有效地从混合语音信号中分离出各个说话者的语音。实验表明,这种方法在两说话者混合的语音中提高了约6dB的信号质量,并且有望扩展到三说话者甚至更多源的场景。研究还探讨了潜在的改进方向,包括网络结构的优化和对不同音频类型的泛化能力提升。
该论文提出了一种利用深度学习获取嵌入特征,然后通过简单聚类方法进行语音分割和分离的技术。通过训练神经网络以产生紧凑的簇,可以有效地从混合语音信号中分离出各个说话者的语音。实验表明,这种方法在两说话者混合的语音中提高了约6dB的信号质量,并且有望扩展到三说话者甚至更多源的场景。研究还探讨了潜在的改进方向,包括网络结构的优化和对不同音频类型的泛化能力提升。
Deep clustering: Discriminative embeddings for segmentation and separation
2015
论文链接:Deep clustering: Discriminative embeddings for segmentation and separation
目录
Deep Learning Embedding Clustering
Abstract
-
为了获得两个最好的分类的结果,我们使用一个目标函数来 训练嵌入,以一个类独立的方式产生 一个理想的 成对亲和矩阵;
-
避免了频谱分解的高成本,产生了紧凑的簇,服从于简单的聚类方法
-
因此,分段隐式编码在 embeddings,并且可以通过聚类来decoded
-
初步实验表明,该方法能够有效分离语音:对含有两说话者混合的声谱图特征进行训练,对一组没有混合的声谱图特征进行测试,可以推断出掩码函数,从而提高了约6dB的信号质量
-
证明了该框架可推广至三说话者混合模型
-
该框架 可以在不使用类标签的情况下使用,因此有可能对不同声音类型集进行训练,并将其推广到新来源
-
希望未来的工作将任意声音的分割,扩展到麦克风阵列方法以及图像分割和其他领域。
Introduction
-
听觉场景分析:寻求在混合信号中识别与单个声源相对应的音频信号分量。(可以看作分割问题)
-
分割问题:
-
通过索引的特征集在信号中形成一组“元素”,每个元素携带(通常是多维)关于部分信号的信息。对于音频信号,它们可能以时频坐标为单位进行定义。
-
然后通过 将元素分割成组或分区来解决分割问题。
-
经典的聚类分割问题是 在某个特定领域,制定基于简单的目标函数上定义的两两关系,而整个输入的分区可能取决于复杂的处理
-
分割问题可大致分为基于类的分割问题:学习类标签;基于分区的分割问题:学习标签分区,不需要对象类标签( 优点:未知对象可以被分割)。
-
重点是单通道音频领域,使用分割作为掩码,可以提取目标信号的部分,没有被其他信号损坏。
-
-
单通道语音分离可以根据分类器或生成模型将声谱图的时频要素分割成目标说话人主导的区域。
-
基于类方法的 局限性:
-
存在大量未被良好定义的类
-
用于分离源的基于类的深度网络模型需要在输出节点中显式地表示输出类和对象实例(导致复杂性)
-
不太好在计算上扩展到更一般的分割任务
-
-
人类似乎能解决基于分割的问题:知觉完形理论。其试图解释知觉分组的特征,如接近和相似
-
将感知分组理论应用与音频分割一般成为计算机听觉场景分析(CASA)
-
光谱聚类(机器学习)利用信号元素特征之间的局部亲和测度,利用归一化亲和矩阵的谱分解优化各种目标函数
-
与传统聚类算法(如k-means)相比,谱聚类算法的优点是不要求点围绕中心原型紧密聚类,并且可以找到任意拓扑的聚类,只要它们构成连通的子图。
-
由于使用的对偶函数的局部形式,在难以聚类的谱问题中,亲和矩阵具有稀疏的块对角线结构,不能直接服从于中心聚类,当对角线亲和结构密集时,这个方法可以很好工作
-
在中央聚类之前,光谱聚类强大但计 算成本高昂的特征空间变换步骤通过“ 增肥”块(fattening)结构来解决这一问题。
-
基于亲和度的方法:多核学习方法引入到用于组合独立亲和度测试的权重中后,我们可以在分区标签可用的基于分区的分段任务中使用它们,但不需要特定的类标签
-
输入特性包括一个双高音跟踪模型,以改进基于内核的特性的相对简单性,以牺牲通用性为代价
-
建议使用深度学习获得嵌入特性(embeddings)
-
自由关联深度网络获得的无监督嵌入,与相对简单的聚类算法一起使用,最近被证明在某些情况下优于光谱聚类方法
-
嵌入方法的诱人之处在于,所有的分区及排列都可以用网络的定维输出隐式表示
通过混合信号并观察它们在光谱优势模式来获得分区标签,在以这种方式训练的混合说话者的数据库上进行训练,尽管只训练了两说话者的混合音频,在不做任何修改下,该模型仍有希望分离出三说话者的能力
Deep Learning Embedding Clustering
定义一个x为原始输入信号,
 ,对于音频信号,n可以是一个时频指标
,对于音频信号,n可以是一个时频指标
 ,其中t表示信号帧和f个频率,其中
,其中t表示信号帧和f个频率,其中
 是对应时频bin处复谱图的值
是对应时频bin处复谱图的值
我们假设存在对元素n进行合理划分的区域,我们希望找到这样的区域,例如对每个区域分别进一步处理特征
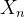 。在音频源分离的情况下,例如,这些区域可能被定义为每个源占主导地位的时频集箱,和估计这样一个分区将使我们能够构建时频掩码(masks)应用于
,导致了时频表示,可以倒获得孤立的来源。(???)
。在音频源分离的情况下,例如,这些区域可能被定义为每个源占主导地位的时频集箱,和估计这样一个分区将使我们能够构建时频掩码(masks)应用于
,导致了时频表示,可以倒获得孤立的来源。(???)
为了估计partition,我们寻找一个k维的embedding V,

以θ为参数,这样在嵌入空间中进行一些简单聚类很可能导致划分为{1,2,...,N},接近目标。在这项工作中,
 是基于一个深度神经网络,该网络是整个输入信号x的全局函数,一般来说,输入特性可能与Xn完全不同。因此我们的转换可以考虑输入的全局属性,并且嵌入可以被认为是一个排列和基数无关的编码网络的估计信号划分。我们考虑一个单位范数的嵌入,使
是基于一个深度神经网络,该网络是整个输入信号x的全局函数,一般来说,输入特性可能与Xn完全不同。因此我们的转换可以考虑输入的全局属性,并且嵌入可以被认为是一个排列和基数无关的编码网络的估计信号划分。我们考虑一个单位范数的嵌入,使

其中
 , vn为元素n的嵌入第k维的值。为了简化符号,我们省略V对θ的依赖关系。
, vn为元素n的嵌入第k维的值。为了简化符号,我们省略V对θ的依赖关系。
我们的方法可以被认为是直接优化一个低秩的亲和矩阵,从而使处理更有效,参数调整到低秩结构,而不是遵循谱聚类的全秩模型的低秩近似。
语音分离实验
配置
目标:
从多个扬声器的混合中分离每个语音信号
同性说话者的混合是最困难的,因为声音的高音在相同的范围
-
从WSJ0训练集中随机选择不同的说话者的话语,并以0~5dB的不同信噪比(SNR)将其混合,生成 30小时的两说话人混合的 训练集
-
其中22.5h考虑了性别混合的平衡
-
7.5只使用了女性混合说话者
-
-
类似地从训练集生成 10h交叉验证集,用于优化一些调谐参数,并评估闭合扬声器实验的源分离性能
-
类似地,使用WSJ0开发集和评估集地16个说话者(与训练、验证集不同的说话者)的话语生成 5h评估数据
-
在处理之前所有数据都被采样到8khz,以减少计算和内存成本
-
输入特征X为混合语音的对数短时傅里叶谱,以32ms的窗长,8ms的窗移和汉明(hann)窗平方根计算
-
为了保证局部一致性,根据所提出的模型对混合语音进行长度为100帧的分割,大致相当于语音中一个单词的长度,并分别进行处理,输出embedding V。
-
在对网络进行训练时,使用理想二值掩码来构建目标
-
为了避免分离过程中由于沉默区域而产生的问题,在训练过程中使用了每个时间频率单元的 二进制权值,只保留那些单元,使每个源在该单元上的幅度大于源最大幅度的某个比率(这个二进制权重引导神经网络忽略那些对所有资源都不重要的bins)
训练
-
在给定输入X和理想亲和矩阵YY'的条件下训练模型中的网络
-
网络结构有两个双向长短记忆(BLSTM)层,然后是一个前馈层。
-
每个BLSTM有600个隐藏单元,前导层对应于嵌入维度(即K)。
-
采用动量0.9的随机梯度下降,固定学习速率10-5
-
每步更新,在权重添加一个均值为零、方差为0.6的高斯噪声
-
准备了几个用于语音分离实验的网络,使用5-60个不同的嵌入维度
-
探索了两种不同的激活函数(logistic和tanh)来形成vn、k的不同范围的embedding V
-
对于每一个嵌入维数,确定相应的权重网络初始化随机从划痕根据正态分布于零均值和方差0.1双曲正切激活和整个训练集
语音分离程序
-
在测试阶段,通过为每个说话者构造一个 基于时频掩码的时域语音信号来实现语音分离
-
通过对embedding V的行向量进行聚类得到每个源扬声器的时频掩码,其中V在每段(100帧)中由所提出的模型输出
-
簇的数量与扬声器的数量相对应
-
通过连接所有片段的embedding V,对整个话语进行k均值聚类;每个每段内光谱聚类
-
标准的语音分离方法,采用 监督稀疏非负矩阵分解(SNMF)作为基线;SNMF可分开不同性别的说话者,对于同性混合不太行。为了使SNMF获得最大可能优势,我们使用一个Oracle在测试时给它提供在混合环境中实际扬声器训练过的基本函数
-
输入特征为8帧左右幅度谱
结果和讨论
结果
-
这里的谱聚类使用外积核,而不是一个局部和函数
-
K=20,40,60性能相似,说明系统可以在较大参数值范围内运行
-
由于tanh网络比logistics有更大的embedding空间,所有大多数实验tanh
-
在训练数据更加均衡的情况下,该系统对同性分离的表现更好
可改进的点
-
利用深度展开技术将聚类步骤结合到嵌入的BLSTM网络中,可以与嵌入共同训练分离,可能产生更好的结果
-
具有不同时间和频率依赖性的替代体系结构,如深度卷积神经网络,或层次递归嵌入网络,可能在学习和正则化方面有所帮助
-
在更多不同音频类型的数据库上扩大训练,以及应用到其他领域















 2609
2609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









