




 本文介绍了如何使用决策树算法对心脏病进行诊断。通过分析克利夫兰医学研究中心的数据,建立基于信息熵和基尼指数的决策树模型,并进行预剪枝,最终发现预剪枝的基尼指数决策树在ROC曲线和预测准确率上表现最佳。
本文介绍了如何使用决策树算法对心脏病进行诊断。通过分析克利夫兰医学研究中心的数据,建立基于信息熵和基尼指数的决策树模型,并进行预剪枝,最终发现预剪枝的基尼指数决策树在ROC曲线和预测准确率上表现最佳。
基于决策树算法的心脏病诊断
目录
前言
提到机器学习常用的算法,决策树必须榜上有名。决策树算法可以处理离散型和连续型数据,且数据预处理成本较低,一般不需要对数据进行标准化、缺失值处理等;同时,相比神经网络的黑箱操作,决策树算法具有较好的可读性,可以对决策树的处理过程进行可视化…决策树的以上优点使其被广泛应用于各个领域的数据分析与数据挖掘。但决策树也存在一点的缺点,例如容易过拟合,导致泛化能力不强,一般可以通过对决策树进行剪枝或者集成随机森林来解决,特别是随机森林,可以说是当前比较受欢迎的机器学习算法!
决策树算法有许多中,一般比较有名的ID3算法(基于信息熵)、C4.5算法(基于信息增益率)、CART算法(基于基尼指数),常用剪枝操作有预剪枝和后剪枝。同样,本文不对算法理论作具体介绍,建议想学习理论的读者最好使用机器学习的相关书籍(推荐周志华《机器学习》、李航《统计学习方法》)来学习。
本文将介绍决策树算法在心脏病诊断中的应用。
基于决策树的心脏病诊断
机器学习在医疗卫生领域也有较多的应用,例如在疾病诊断方面,有时预测准确率高于人为判断。
本文将根据克利夫兰医学研究中心的心脏病患者数据,建立心脏病诊断模型,用于预测诊断是否患有心脏病。
数据指标具体如下:

(本文数据来源于和鲸社区)
导入相关库
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
读取并查看数据基本情况
打印数据特征
首先将数据特征打印出来,方便查看
fea1 = ['ATTR1','ATTR2','ATTR3','ATTR4','ATTR5','ATTR6','ATTR7','ATTR8','ATTR9','ATTR10','ATTR11','ATTR12','ATTR13','ATTR14']
fea2 = ['年龄','性别','胸痛类型','静息血压','血浆类固醇含量','空腹血糖','静息心电图结果','最高心率','运动型心绞痛','运动引起的ST下降',\
'最大运动量时心电图ST的斜率','使用荧光染色法测定的主血管数','THAL','患病情况']
fea = zip(fea1,fea2)#打包函数zip()
for i in fea:
print (i)
输出:
(‘ATTR1’, ‘年龄’)
(‘ATTR2’, ‘性别’)
(‘ATTR3’, ‘胸痛类型’)
(‘ATTR4’, ‘静息血压’)
(‘ATTR5’, ‘血浆类固醇含量’)
(‘ATTR6’, ‘空腹血糖’)
(‘ATTR7’, ‘静息心电图结果’)
(‘ATTR8’, ‘最高心率’)
(‘ATTR9’, ‘运动型心绞痛’)
(‘ATTR10’, ‘运动引起的ST下降’)
(‘ATTR11’, ‘最大运动量时心电图ST的斜率’)
(‘ATTR12’, ‘使用荧光染色法测定的主血管数’)
(‘ATTR13’, ‘THAL’)
(‘ATTR14’, ‘患病情况’)
读取数据
data = pd.read_csv('data.csv',names = fea1)
data.head()
输出:
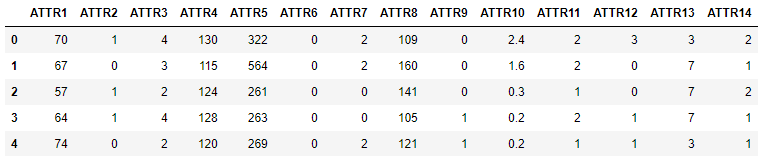
这里因变量“ATTR14”的具体数值为1(不存在心脏病)和2(存在心脏病),后期需要将其转化为0、1变量或1、-1形式的变量(若不进行处理后期模型评估时会报错,函数无法识别哪些是正例,哪些是负例)。
data.shape
输出:
(270, 14)
数据包括14个特征、270条记录。
data.info()
输出:
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 270 entries, 0 to 269
Data columns (total 14 columns):
ATTR1 270 non-null int64
ATTR2 270 non-null int64
ATTR3 270 non-null int64
ATTR4 270 non-null int64
ATTR5 270 non-null int64
ATTR6 270 non-null int64
ATTR7 270 non-null int64
ATTR8 270 non-null int64
ATTR9 270 non-null int64
ATTR10 270 non-null float64
ATTR11 270 non-null int64
ATTR12 270 non-null int64
ATTR13 270 non-null int64
ATTR14 270 non-null int64
dtypes: float64(1), int64(13)
memory usage: 29.6 KB
数据无缺失值。
数据转换
将因变量转换为0-1变量
data['ATTR14'] = data['ATTR14'].replace(1,0) #1替换为0
data['ATTR14'] = data['ATTR14'].replace(2,1) #2替换为1
data.head()
输出:
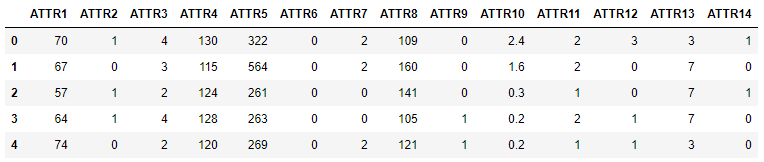
“ATTR14”列已经转换为0-1变量。
数据探索
plt.rcParams["font.sans-serif"]=["SimHei"] #支持中文显示
plt.rcParams["axes.unicode_minus"]=False #支持负号显示
data.hist 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2910
2910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









