






数据科学基础考试参考——南京工业# 数据科学
——made by njtech_计2104 melody
目录
文章目录
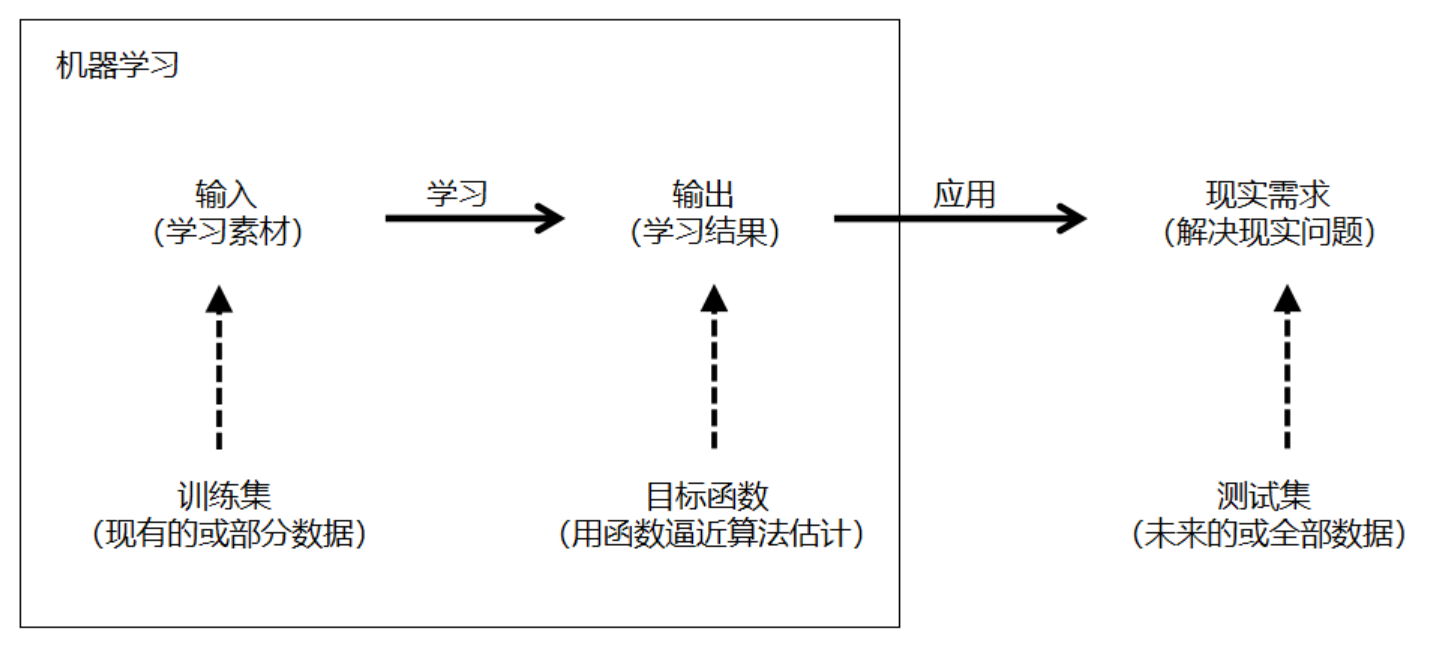
课程介绍
-
通过本课程的学习,使学生掌握数据科学领域中的基本概念和知识以及前沿技术,学习数据处理方面的技术知识,培养学生具备应用数据科学理论和实践知识去解决实际应用中涉及数据处理、分析和决策,培养学生解决大数据实践应用问题的能力奠定基础。
-
具体课程目标如下:
- 课程目标1:掌握数据科学基础理论,基本知识
- 课程目标2:掌握数据预处理、数据统计和机器学习等数据处理相关的基本方法。
- 课程目标3:掌握数据使用方法和数据在实际中的应用知识
-
考核标准:
10% 出勤率/课堂反馈 + 10% 平时作业 + 80% 期末考试(闭卷)
课程PPT目录:
- 数据&数据基础理论(废话篇)
- 数据准备和数据模型
- 数据预处理
- 数据统计
- 机器学习
- 数据计算
- 推荐系统
题库及解析
选择题(30分)
-
下列属于数据的是:( )。
A)符号 B)语音 C)视频 D)以上都是
【解析】数据可以包括各种形式的信息,例如符号、语音和视频。符号可以是文字、数字或其他标志,语音是一种声音信号,视频是一种图像信号。因此,所有选项A、B和C都属于数据的形式。
-
下列关于数据和智能 (智慧)描述错误的是:( )。
A)数据是描述现实世界的记录。
B)数据是人工智能的基础。
C)数据能直接产生人工智能。
D)智能是指利用知识去预测、解释、发现等。【解析】选项C描述错误。数据本身不能直接产生人工智能。数据是描述现实世界的记录,它可以被用作训练和喂养给人工智能系统,但数据本身并不具备智能。智能是指一种能力或特征,涉及到利用知识去预测、解释、发现等。数据是构建和训练人工智能系统的基础,但智能是通过对数据的分析、处理和理解而实现的。因此,选项C是描述错误的。
-
下列属于大数据的特征的是: ( )。
A)速度慢
B)价值密度低
C)类型少
D)以上均不是
【解析】大数据的主要特征通常被概括为5V:体积(Volume)、速度(Velocity)、多样性(Variety)、真实性(Veracity)和价值(Value)。选项B中的"价值密度低"正是大数据的一个关键特点。因为大数据通常包含大量的无关或冗余信息,因此其价值密度相对较低。这就意味着,从大数据中提取出有价值的信息需要进行大量的数据处理和分析。
-
下列关于大数据时代的新理念的描述正确的是: ( )
A)海量数据面前,客户关注的是数据计算的“效率”,而不是盲目追求“精度”
B)大数据时代,只需对大数据进行查询及可以达到“基于复杂算法的智能计算的效果”。
C)大数据时代,业务正从业务数据化向数据业务化转变
D)以上都正确。【解析】以上所有选项都描述了大数据时代的新理念,而且这些描述都是正确的。
A)海量数据面前,客户关注的是数据计算的"效率",而不是盲目追求"精度"。在大数据时代,处理大规模数据的速度和效率变得尤为重要,因为数据量庞大,传统的精确计算可能变得不切实际或耗时过长。因此,对于客户而言,更关注的是如何以更高效的方式处理大数据,而不是一味地追求绝对精确性。
B)大数据时代,只需对大数据进行查询即可达到"基于复杂算法的智能计算的效果"。大数据时代的技术和工具使得对大规模数据进行查询和分析更加容易和高效,可以应用复杂的算法和技术来挖掘数据中的有价值信息,从而实现智能计算的效果。
C)大数据时代,业务正从业务数据化向数据业务化转变。传统上,业务主要关注自身的业务数据,但在大数据时代,越来越多的业务开始意识到数据的价值,并将数据作为业务的核心资产和驱动力。数据不仅仅是业务的附属物,而是业务发展和创新的关键要素。因此,业务正逐渐从业务数据化向数据业务化的转变。
因此,以上所有选项都正确。
-
下列关于数据科学含义理解正确的是: ( )
A)教据科学是以“数据”尤其是“大数据"为研究对象。
B)数据科学是以实现“从数据到信息”、“从教据到知识"和(或)从数据到智慧”的转化为主要研究目的
C)数据科学是将“现实世界”映射到“数据世界”之后,在“数据层次”上研究“现实世界”的问题
D)以上描述均正确【解析】以上所有选项都正确描述了数据科学的含义。
A)数据科学是以"数据"尤其是"大数据"为研究对象。数据科学关注数据的获取、存储、处理和分析,其中大数据是数据科学领域的一个重要研究方向。
B)数据科学是以实现"从数据到信息"、"从数据到知识"和(或)"从数据到智慧"的转化为主要研究目的。数据科学旨在从大量的数据中提取有用的信息,进一步推导出知识,并实现智能化的应用和决策支持。
C)数据科学是将"现实世界"映射到"数据世界"之后,在"数据层次"上研究"现实世界"的问题。数据科学通过采集和分析现实世界中的数据,将现实世界的问题和现象转化为数据问题,并利用数据科学的方法和技术来解决这些问题。
因此,以上所有选项都正确。
-
NoSQL是指:()
A)Not only SQL
B)No SQL
C) Netwockc of SQL
D)以上均不是【解析】NoSQL是指"Not only SQL",即不仅限于传统关系型数据库SQL的一种数据库分类。NoSQL数据库是指那些不使用SQL作为主要查询语言的非关系型数据库。NoSQL数据库的设计目标通常包括高可扩展性、高性能、灵活的数据模型和易于分布式部署等特点。因此,选项A)"Not only SQL"是正确的定义。选项B)"No SQL"是一种错误的拼写,选项C)"Netwockc of SQL"是无意义的术语。选项D)"以上均不是"也不准确。
-
下列关于键值数据库的描述正确的是: ( )
A)其数据模型是键/值对, 键是:一个字符串对象,值可以是任意类型的数据。
B)适合涉及频繁读写、拥有简单数据模型的应用。
C)优点是查找快速,扩展性好,灵活性好,大量写操作时性能高。
D)以上均是。【解析】以上所有选项都正确描述了键值数据库的特点和优点。
A)键值数据库的数据模型是键/值对,其中键通常是字符串对象,值可以是任意类型的数据。这种简单的数据模型使得键值数据库非常易于理解和使用。
B)键值数据库适合那些需要频繁读写操作、并且拥有相对简单数据模型的应用。由于其简单性和高效性,键值数据库常用于缓存、会话存储和轻量级存储等场景。
C)键值数据库的优点包括查找快速、扩展性好和灵活性好。由于数据是通过键进行查找,键值数据库可以快速定位和检索数据。另外,键值数据库的分布式存储和扩展能力也非常强,可以应对高并发和大规模数据的存储需求。此外,键值数据库在大量写操作时通常具有较高的性能。
因此,以上所有选项都正确。
-
下列哪种数据库可以成为理想的缓冲层解决方案? ( )。
A)关系数据库
B)键值数据库
C)Oracle
D)列族数据库【解析】键值数据库可以成为理想的缓冲层解决方案。缓冲层的主要目标是提供快速的读取和写入操作,以减轻对底层存储系统的负载,并提高整体性能。键值数据库以其简单的数据模型和高效的读写操作而闻名,适合用作缓冲层解决方案。
A)关系数据库通常使用表格结构和SQL查询语言,虽然它们可以用于缓冲层,但相对于键值数据库来说,可能会增加一些复杂性和性能开销。
C)Oracle是一种关系数据库管理系统(RDBMS),虽然它可以用于缓冲层,但对于特定的缓冲需求来说,可能会过于复杂和重量级。
D)列族数据库是一种以列为基本单位进行存储和查询的数据库类型,尽管在某些场景下也可以用于缓冲层,但相对于键值数据库,其复杂性和学习成本可能较高。
因此,选项B)键值数据库是成为理想的缓冲层解决方案的最佳选择。
-
下列关于列族数据库的描述正确的是: ( ).
A)其缺点是功能较少, 大都不支持强事务致性。
B)适合涉分布式数据存储与管理。
C)优点是查找速度快,可扩展性强,容易进行分布式扩展,复杂性低。
D)以上描述都对。【答案】D)以上描述都对。
【解析】以上所有选项都正确描述了列族数据库的特点和优缺点。
A)列族数据库的缺点之一是功能较少,大多数列族数据库不支持强事务一致性。这意味着在一些应用场景下,列族数据库可能不适合需要严格事务处理的需求。
B)列族数据库适用于分布式数据存储和管理。由于其设计和优化用于大规模数据的存储和处理,列族数据库在处理分布式环境中的数据时具有优势。
C)列族数据库的优点包括快速查找速度、强大的可扩展性和容易进行分布式扩展。列族数据库以列为基本单位进行存储和查询,这种结构使得查询具有高效的查找速度。同时,列族数据库的设计支持水平扩展和分布式部署,使其能够应对大规模数据和高并发访问的需求。另外,相对于一些其他数据库类型,列族数据库的复杂性较低。
因此,以上所有选项都是正确的描述。
-
下列哪个不属于列族数据库? ( )-
A)Cassandra
B)BigTable
C)HBase
D)Redis【解析】Redis不属于列族数据库。
A)Cassandra是一个开源的分布式列族数据库系统,设计用于处理大规模数据的分布式存储和高可用性需求。
B)BigTable是Google开发的基于列族模型的分布式数据库系统,用于存储大规模结构化数据。
C)HBase是基于Hadoop的列族数据库,旨在提供在大数据集群上存储和处理海量数据的能力。
这些选项中,A)Cassandra、B)BigTable和C)HBase都属于列族数据库,而D)Redis则是一种开源的内存数据库,其数据模型不是基于列族的。
因此,选项D)Redis不属于列族数据库。
-
下列关于文档数据库的插述正确的是:()
A)其数据模型是健(名)/值,值(value)是版本化的文档
B)主要应用于存储、索引并管理面向文档的数据或者类似的半结构化数据
C)其缺点是缺乏统一的查询语法
D)以上均正确【解析】选项D是正确的,因为A、B和C选项都正确地描述了文档数据库的特性。
A选项指出,文档数据库的数据模型是键(名)/值对,其中的值是版本化的文档。这意味着,数据库中的每一个元素都是一个键值对,键是唯一的,而值可以是一个文档。版本化的文档可以有助于数据的追踪和管理。
B选项提到,文档数据库主要用于存储、索引和管理面向文档的数据或类似的半结构化数据。这是因为文档数据库可以方便地存储和查询包含多种不同属性的数据。
C选项表明,文档数据库的一个缺点是缺乏统一的查询语法。虽然文档数据库在数据存储和查询方面具有优势,但由于缺乏统一的查询语言,使用者需要根据具体的数据库系统学习和使用特定的查询语言,这增加了使用文档数据库的复杂性。
-
下列哪个属于图形数据库?()
A)Neo4J
B)Redis
C)HBase
D)Oracle【解析】选项A是正确的。Neo4J是一种图形数据库,它能够将数据存储为图形结构,这使得它非常适合处理复杂的关系网络。在图形数据库中,数据项以节点和边的形式存储,节点代表实体,边代表实体之间的关系。Neo4J可以高效地执行对复杂关系的查询。
而Redis是一种键值对数据库,HBase是一种列式存储数据库,Oracle是一种关系型数据库,它们都不是图形数据库。
-
下列关于图形数据库的描述错误的是: ( ).
A)其数据模型是图结构。
B)专门用于 处理具有高度相互关联关系的数据。
C)灵活性高,支持复杂的图形算法,可用于构建复杂的关系图谱。
D)可以支持大规模的数据规模。【解析】选项D)描述错误。图形数据库可以支持大规模的数据规模,因为其设计目标之一就是处理具有高度相互关联关系的数据,并支持复杂的图形算法。图形数据库的数据模型是图结构,其中节点表示实体,边表示实体之间的关系。它们被广泛应用于构建和查询复杂的关系图谱,如社交网络分析、推荐系统、知识图谱等。
因此,选项D)错误地表示图形数据库不支持大规模的数据规模,实际上图形数据库可以有效地处理大规模的数据。
-
数据准备包括以下哪些过程? ( )。
A)数据特征化
B)数据清洗
C)数据集成
D)以上都是。【解析】数据准备包括以下过程:
A)数据特征化:这是对数据进行分析和理解的过程,确定数据的特征和属性,包括数据类型、数据范围、数据分布等。
B)数据清洗:这是对数据进行预处理和清理的过程,包括处理缺失值、异常值、重复值,进行数据格式转换等,以确保数据的质量和一致性。
C)数据集成:这是将来自不同数据源的数据合并为一个统一的数据集的过程,通常涉及数据字段映射、数据合并、数据重塑等操作。
因此,以上所有选项都是数据准备过程的一部分,所以答案是D)以上都是。
-
对数据进行处理的动机是什么? ( )
A)原始数据存在质量问题。
B)数据不符合计算的要求。
C)数据量增长快且过大。
D)A和B都是数据处理的动机。【解析】对数据进行处理的动机可以是多方面的,常见的包括:
A)原始数据存在质量问题:原始数据可能包含错误、缺失值、异常值或噪声等问题,这些问题可能会影响数据的准确性和可靠性。数据处理可以通过清洗、校正和修复等操作来解决这些质量问题,以提高数据的质量。
B)数据不符合计算的要求:在进行特定的计算、分析或建模任务时,数据可能需要经过转换、整理或归一化等处理,以满足计算的要求和数据的规范。数据处理可以根据具体任务和需求,对数据进行预处理、特征工程等操作,使其适合进行后续的分析和应用。
C)数据量增长快且过大:随着数据的不断增长,原始数据可能会变得庞大且难以处理。数据处理可以包括对数据进行压缩、抽样、分区等操作,以便有效地管理和处理大规模数据集。
因此,以上选项A和B都是数据处理的动机。
-
下列关于探索性分析 (EDA)的描述错误的是:()
A)EDA 是对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索.
B)EDA 是通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。
C)与传统统计学中的验证性分析相比,EDA不需要事先假设,而验证性分析需要事先提出假设。
D)在一般数据科学项目中,验证性分析在先,而探索分析在后。【答案】D)在一般数据科学项目中,验证性分析在先,而探索分析在后。
【解析】选项D描述错误。在一般的数据科学项目中,通常是先进行探索性分析(EDA),然后才进行验证性分析。探索性分析是一种用于理解数据、发现结构和规律的方法,通过作图、制表、计算特征量等手段,以尽量少的先验假定对数据进行探索。探索性分析帮助数据科学家熟悉数据,发现数据中的趋势、异常、相关性等。
相比之下,验证性分析是在已经进行了初步探索性分析的基础上,提出明确的假设并进行检验。验证性分析旨在验证事先提出的假设或模型,并进行统计推断和假设检验。
因此,选项D描述错误,探索性分析通常在验证性分析之前进行。
-
下列关于“机器学习中训练经验的选择需要注意哪些问题”的描述错误的是:()。
A). 训练经验能否为系统的决策提供直接或间接的反馈。
B)训练经验能否被学习系统控制。
C)训练集的分布是否与实际数据集具有相似的分布
D)训练集是否可以随机选择抽取。【解析】选项D描述错误。在机器学习中,训练经验的选择需要注意许多问题,包括:
A)训练经验能否为系统的决策提供直接或间接的反馈:训练经验应该包含对系统决策的反馈信息,以便系统能够根据这些反馈进行学习和改进。
B)训练经验能否被学习系统控制:训练经验应该能够被学习系统控制和处理,以便系统能够有效地学习和适应不同的情境和任务。
C)训练集的分布是否与实际数据集具有相似的分布:训练集应该从与实际数据集具有相似分布的样本中抽取,以便学习系统在真实场景中能够表现良好。
D)训练集是否可以随机选择抽取:训练集的选择应该是有目的性的,根据特定的需求和目标来选择样本,而不是随机选择抽取。
因此,选项D描述错误。在训练经验的选择中,应该是有目的性地选择样本,而非随机选择抽取。
-
下列关于机器学习中目标函数的选择描述正确的是:
A)在许多实际问题的结果过程中,学习目标函数(T)是一个十分困难的任务,无法找到准确的目标函数(T)
B)一般采用函数逼近(Function approximatin)的方法,仅希望学习到一个近似的目标函数(V)
C)近似函数(V)的设计应避免采用“不可操作的方法”。
D)以上选项均正确。【解析】以上所有选项都正确描述了机器学习中目标函数的选择。
A)在许多实际问题中,确定准确的目标函数是一个十分困难的任务。由于问题的复杂性和不确定性,很难找到一个完美的目标函数,因此在实际应用中通常采用近似的目标函数。
B)在机器学习中,常常采用函数逼近的方法,希望学习到一个近似目标函数。由于问题的复杂性和数据的限制,很难精确地表示目标函数,因此使用近似函数来代替实际目标函数。
C)近似函数的设计应避免采用不可操作的方法。这意味着设计的近似函数应该是可计算和可操作的,能够在实践中应用和优化。
因此,以上所有选项都正确,选项D)是正确的。
-
下了关于基于实例的学习方法的描述错误的是:()。
A)基于实例学习方法 (nstace badeamine的基本思路就是看新增实钢与存体的实侧的关系,并据此把一个目标函数值赋给新增实例。
B)基于实例学习方法中, 分类新实例的开销较小。
C)基于实例学习方法的优点在于并不是在整个实例空间上一次性地估计目标函数,而是针对每个待分类新实例做出局部性且相异性的估计。
D)基于实例学习方法的特点是将从实例中泛化工作推迟到必需分类新的实例时。【解析】选项B是错误的。在基于实例的学习方法中,每个新实例都需要与存储的先前实例进行比较,以确定其分类或预测。这意味着,当新实例需要分类时,必须执行一次全面的搜索,以找到与新实例最相似的已存实例。因此,这个过程的计算开销较大,特别是当实例库规模很大时。因此,说“基于实例学习方法中,分类新实例的开销较小”是错误的。
-
下列属于基于实例的学习方法的是:()。
A)k-近邻
B)局部加权回归法
C)k-means
D)A和B均是。【解析】下列选项属于基于实例的学习方法:
A)k-近邻(k-nearest neighbors):k-近邻算法根据样本之间的相似度,将待分类的新实例归类为与其最接近的k个已知类别实例中的多数类别。
B)局部加权回归法(Locally Weighted Regression):局部加权回归法通过考虑周围实例的权重来进行回归预测,权重通常基于与目标实例的距离或相似度。
C)k-means并不属于基于实例的学习方法,它是一种聚类算法,用于将相似的实例划分为k个不同的类别。
因此,只有选项A和B属于基于实例的学习方法,所以答案是D)A和B均是。
-
下列关于人工神经网络描述错误的是: ( ).
A)人工神经网络的神经元相互之间都可能有连接。
B)实现“人工神经元” 的方法较多,如感知器(Percepto)、线性单元(Liner Unt)和Sigmoid单元。
C)线性单元(Linear Unit)是最简单的“人工神经元”。
D)人工神经网络也是由一系列比较简单的“人工神经元”相互连接的方式形成网状结构。【解析】选项C描述错误。线性单元并不是最简单的人工神经元,而是一种特定类型的人工神经元,其输出是输入的线性组合。最简单的人工神经元是感知器(Perceptron),它接受输入并生成输出,具有阈值激活函数。
A)人工神经网络的神经元之间可以相互连接,这些连接可以是有向的或无向的,并且可以具有不同的权重。
B)感知器、线性单元和Sigmoid单元都是实现人工神经元的方法。感知器是最早的人工神经元模型,线性单元是一种特定类型的人工神经元,Sigmoid单元则使用Sigmoid激活函数。
D)人工神经网络是由一系列相互连接的人工神经元组成的网络结构,这些连接形成了网状结构,用于传递和处理信息。
因此,选项C描述错误。
-
在实际应用中,下列哪个是人工神经网络的学习算法? ( )
A)梯度下降算法
B)反向传播算法
C)Apriori算法
D)A和B均是。【解析】在实际应用中,梯度下降算法和反向传播算法是人工神经网络的常用学习算法。
A)梯度下降算法是一种优化算法,用于更新神经网络的权重和偏置,以最小化损失函数。它通过计算损失函数对参数的梯度,并沿着梯度方向更新参数,逐步调整网络的权重和偏置。
B)反向传播算法是一种基于梯度的学习算法,用于训练多层前馈神经网络。它通过计算输出层与目标之间的误差,并将误差从输出层向后传播到隐藏层,然后根据误差梯度调整网络的权重和偏置。
C)Apriori算法是一种用于关联规则挖掘的算法,与人工神经网络的学习无直接关系。
因此,选项A和B都是人工神经网络的学习算法,所以答案是D)A和B均是。
-
以下关于BP算法缺点描述正确的是:()。
A)算法计算量超大。
B)可能出现局部极小的问题。
C)算法的收敛速度慢。
D)以上均正确。【解析】以下关于BP(反向传播)算法的缺点描述正确:
A)算法计算量超大:BP算法中需要进行前向传播和反向传播的计算,随着网络规模和层数的增加,计算量会显著增加,尤其是在大型网络中。
B)可能出现局部极小的问题:BP算法在优化过程中可能会陷入局部极小点,无法找到全局最优解。这是由于梯度下降方法在非凸优化问题中容易受到局部极小值的影响。
C)算法的收敛速度慢:BP算法的收敛速度可能较慢,尤其在一些复杂的问题中。这是由于BP算法的参数调整是基于局部梯度的,且可能存在学习率选择不当等因素。
因此,以上选项A、B和C都正确,所以答案是D)以上均正确。
下列关于增强 (强化)学习描述错误的是: ().
A)增强学习主要研究的是如何协助自治Agent (或机器人)的学习活动,进而达到选择最优动作的目的。
B)增强学习的学习任务 是学习一个控制策略n:S-A,使回报总和的期望值最大。
C)增强学习的学习任务要使得后面的回报值随着他们的延迟指数增加。
D)Q 函数(Q-leaming)是增强学习中最基本的方法之一。【答案】C)增强学习的学习任务要使得后面的回报值随着它们的延迟指数增加。
【解析】选项C描述错误。增强学习的学习任务并不是要使得后面的回报值随着延迟指数增加,而是要通过学习一个控制策略,使得回报总和的期望值最大化。
A)增强学习主要研究如何辅助自主Agent或机器人的学习活动,从而达到选择最优动作的目的。
B)增强学习的学习任务是学习一个控制策略π:S → A,使得回报总和的期望值最大。控制策略π在给定状态下选择最优的动作来最大化累积回报。
D)Q函数(Q-learning)是增强学习中最基本的方法之一。Q函数是一个状态-动作值函数,它衡量在给定状态下采取某个动作所获得的预期回报。
因此,选项C描述错误。
-
下面关于k-近邻算法和k-Means算法的描述正确的是:()。
A)k-Means用来聚类,而k近邻算法是用来做归类。
B)k-Means 用来归类,而k近部算法是用来做聚类。
C)k-Means和k-近邻算法都可以用来训练神经网络。
D)k-Means和k-近邻算法都可以用来逼近机器学习中的目标函数。【解析】选项A描述正确。
A)k-Means算法是一种聚类算法,它将数据点划分为K个不同的簇,每个簇由其内部的数据点组成。
k近邻算法是一种分类算法,它根据与待分类实例最近的k个邻居的标签进行分类。
B)选项B描述错误。k-Means算法是用来聚类,而k近邻算法是用来做归类(分类)。
C)选项C描述错误。k-Means和k-近邻算法通常不用于训练神经网络。这两种算法主要用于聚类和分类任务,与神经网络训练不直接相关。
D)选项D描述错误。k-Means和k-近邻算法通常不用于逼近机器学习中的目标函数。它们主要用于聚类和分类任务,而目标函数的逼近通常是通过其他优化算法来实现的。
因此,只有选项A)k-Means用来聚类,而k近邻算法是用来做归类,描述正确。
-
下列大数据计算平台组件描述错误的是:( ,。
A)HDFS是Hadoop的分布式文件系统。
B)Pig的核心是机器学习算法及其实现。
C)Pig较好地封装了MapReduce的处理过程,使程序员更加关注数据,而不是程序的执行过程。
D)Hive定义了一种类似 sQL的查询语言(HiveQL, HQL,将其转化为MapReduce任务在Hadoop上执行。【解析】选项B描述错误。
A)HDFS(Hadoop Distributed File System)是Hadoop的分布式文件系统,用于存储大规模数据,并提供高可靠性和容错性。
B)Pig是一个用于数据分析的平台组件,它提供了一种高级编程语言(Pig Latin),用于描述和执行数据处理任务。Pig的核心是数据流处理和数据转换,它并不是专注于机器学习算法及其实现。
C)Pig较好地封装了MapReduce的处理过程,使程序员更加关注数据的处理和分析,而不需要过多关注底层的执行过程。
D)Hive是建立在Hadoop之上的数据仓库基础架构,它定义了一种类似SQL的查询语言(HiveQL/HQL),可以将HiveQL查询转化为MapReduce任务,在Hadoop上执行。
因此,选项B描述错误,Pig的核心不是机器学习算法及其实现。
-
基于人口统计学的推荐机制只是简单的根据()发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户。
A)系统用户的基本信息。
B)物品或者内容的相关性。
C)用户的访问历史记录。
D)物品和用户之间的相似度。【解析】基于人口统计学的推荐机制主要是根据系统用户的基本信息来发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户。
人口统计学信息包括用户的基本属性,如年龄、性别、地理位置等。通过分析这些信息,可以找到与当前用户具有相似属性的其他用户,并将这些相似用户喜欢的物品推荐给当前用户。
选项B)物品或者内容的相关性描述的是基于物品或内容之间的相关性来进行推荐,不是基于人口统计学信息的推荐机制。
选项C)用户的访问历史记录描述的是基于用户的过去访问记录来进行推荐,不属于基于人口统计学的推荐机制。
选项D)物品和用户之间的相似度描述的是根据物品和用户之间的相似度来进行推荐,也不属于基于人口统计学的推荐机制。
因此,根据题目描述,基于人口统计学的推荐机制主要是根据系统用户的基本信息来发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户。选项A)系统用户的基本信息是正确的。
-
下列关于数据的理解错误的是:()。
A)数据的形 式是多样化的,如社交网络数据,物联网数据等。
B)数据分析一直在发展,并能助推现代社会的商业、技术等各方面的发展。
C)数据分析预测能给帮我们看清一切,不会带来负面的影响。
D)以上均不正确。【解析】选项C描述错误。
A)数据的形式是多样化的,包括社交网络数据、物联网数据等。不同领域和应用场景下产生的数据具有不同的形式和特点。
B)数据分析一直在发展,并在商业、技术等各个领域推动现代社会的发展。数据分析的应用可以帮助揭示隐藏的信息、发现趋势、提供决策支持等。
C)选项C描述错误。尽管数据分析可以提供有价值的预测和见解,但它并不是万能的,也不是完全没有负面影响的。数据分析可能受到数据质量问题、误差和偏差、隐私和安全风险等因素的影响。此外,错误的数据分析和错误的解读也可能导致误导和错误的决策。
D)选项D描述不正确,因为选项A和B是正确的。
因此,选项C描述错误。
-
下列关于大数据与常规数据的描述正确的是: ( )
A)规模庞大是大数据的一个特征,而常规数据规模相对较小。
B)大数据流变化频案,而常规数据增长速度较慢。
C)大数据种类繁多,有非结构化、半结构化等类型的数据。
D)以上都正确“【解析】下列描述关于大数据与常规数据的特征都是正确的:
A)规模庞大是大数据的一个特征,大数据通常具有大量的数据量,远远超过了常规数据的规模。
B)大数据流变化频繁,大数据的产生速度非常快,而常规数据的增长速度相对较慢。
C)大数据种类繁多,大数据包含多种类型的数据,包括非结构化数据(如文本、图像、视频等)、半结构化数据(如日志文件、XML文件等)等。
因此,以上所有描述都是正确的,选项D)以上都正确。
-
下列不是爬虫行为的是: ( )。
A)载入
B)解析
C)压缩
D)存储【解析】选项C描述的是"压缩",而不是爬虫行为。
A)载入:指的是爬虫程序从网络上下载或获取网页或其他数据。
B)解析:指的是爬虫程序对下载的网页进行解析,提取所需的信息,如链接、文本内容等。
D)存储:指的是将爬取的数据存储到本地或数据库等持久化的存储介质中。
选项C)压缩与爬虫行为无关,不属于爬虫的常规行为。爬虫的主要任务是获取、解析和存储数据,而压缩是对数据进行压缩处理的操作。
因此,选项C)压缩不是爬虫行为。
-
下列关于关系型数据库系统的说法错误的是:()。
A)关系必须是规范化的,满足一定的规范条件,即数据是有结构的.
B)关系型数据库是大数据时代处理数据存储的得力工具。
C)建立索引可加快查询速度。
D)SQL是关系数据库的标准语言。【解析】选项B描述错误。
A)关系必须是规范化的,满足一定的规范条件,即数据是有结构的。关系型数据库通过表格的形式存储数据,每个表格具有预定义的列和行,数据按照关系模型进行组织。
C)建立索引可以加快查询速度。关系型数据库可以使用索引来提高数据的访问效率,通过索引可以快速定位到满足查询条件的数据。
D)SQL(Structured Query Language)是关系数据库的标准语言,用于执行数据定义、查询、操纵和控制等操作。
B)关系型数据库并非是大数据时代处理数据存储的得力工具。虽然关系型数据库在处理结构化数据和小到中等规模的数据时非常有效,但对于大数据的处理,关系型数据库可能面临性能瓶颈。在大数据时代,通常会使用分布式存储和处理系统来处理大规模和非结构化数据。
因此,选项B描述错误。
-
以下关于图形数据库Neo4j特点的说法错误的是:( ).
A)Neo4j是基于C#的开源图形数据库
B)数据以一种针对图形网络进行过优化的格式保存在磁盘上。
C)Neo4j既可作为无需任何管理开销的内嵌数据库使用,也可以作为单独的服务器使用。
D)自适应规模的Neo4j无需任何额外的工作便可以处理包含数十亿节点、关系和属性的图【解析】选项A描述错误。
A)Neo4j不是基于C#的开源图形数据库,而是基于Java的开源图形数据库。
B)数据以一种针对图形网络进行过优化的格式保存在磁盘上。Neo4j使用基于属性图模型的存储方式,将数据以节点和关系的形式组织,并通过索引进行快速访问。
C)Neo4j既可作为无需任何管理开销的内嵌数据库使用,也可以作为单独的服务器使用。Neo4j提供了嵌入式模式和服务器模式两种使用方式,可以根据需求选择合适的部署方式。
D)自适应规模的Neo4j无需任何额外的工作便可以处理包含数十亿节点、关系和属性的图。Neo4j具有良好的可扩展性和性能,能够处理大规模的图数据,支持处理包含数十亿节点、关系和属性的图。
因此,选项A)Neo4j是基于C#的开源图形数据库描述错误。
-
下列哪个选项不是数据质量的基本属性? ( ).
A)数据的正确性
B)数据的完整性
C)数据的一致性
D)数据量的大小【解析】选项D描述的是数据的大小,而不是数据质量的基本属性。
数据质量的基本属性包括:
A)数据的正确性:数据准确地反映了所描述的现实世界的特征和事实。
B)数据的完整性:数据没有缺失、遗漏或不完整的部分,包含了所需的全部信息。
C)数据的一致性:数据在不同的数据源、数据集或数据项之间保持一致,没有矛盾或冲突。
D)数据量的大小描述的是数据的规模或容量,并不是数据质量的基本属性。
因此,选项D)数据量的大小不是数据质量的基本属性。
-
有关统计学规律在数据质量检验中的应用,下列说法正确的是: ( ).
A)可以明确指出数据中存在的错误
B)使用统计学规律可以判定数据是否真的存在问题。
C)统计学规律率可以揭示数据存在何种问题。
D)综合不同的技术方案进行交叉检验可帮助我们确认数据质量。【解析】选项D)综合不同的技术方案进行交叉检验可帮助我们确认数据质量是正确的。
A)统计学规律可以帮助识别数据中存在的错误,但不能明确指出错误的具体位置和性质,需要进一步的分析和检验。
B)使用统计学规律可以提供一定的指示,但并不能判定数据是否真的存在问题,还需要综合其他因素进行综合判断。
C)统计学规律可以揭示数据中存在的一些问题,但并不能涵盖所有可能的问题,仍需要其他方法和技术来全面评估数据质量。
D)综合不同的技术方案进行交叉检验是一种常用的方法,可以通过多个角度和方法对数据进行验证和确认,从而提高数据质量的可靠性。
因此,选项D)综合不同的技术方案进行交叉检验可帮助我们确认数据质量是正确的。
-
以下哪些方法是数据鉴别的常用方法?()。
A)消息鉴别码
B)Hash 函数
C)数字签名
D)以上选项均是。【解析】选项A)消息鉴别码、选项B)Hash函数、选项C)数字签名都是数据鉴别的常用方法。
A)消息鉴别码(Message Authentication Code,MAC)是一种基于密钥的算法,用于验证消息的完整性和真实性。
B)Hash函数是一种将输入数据映射为固定长度哈希值的算法,通过比较哈希值来验证数据的一致性。
C)数字签名是使用私钥对数据进行加密的过程,用于验证数据的来源和完整性。
这些方法在数据安全和完整性保护方面发挥着重要作用,可以用于确保数据的可信性和防止数据被篡改。
因此,选项D)以上选项均是数据鉴别的常用方法。
-
以下有关探索性和验证性数据分析的说法正确的是:()。
A)验证性分析在尽量少的先验假定下进行探索。
B)探索性分析需要事先提出假设,以发掘数据之间的关系。
C)一般数据科学项目中,探索性分析在先,验证性分析在后。
D)验证性分析对已有的数据通过作图、制表、方程拟合、计算特征量等手段验证数据的质量。【解析】选项C描述正确。
A)验证性分析并不是在尽量少的先验假定下进行探索,而是在已有的假设或理论基础上对数据进行验证。
B)探索性分析是一种无需事先提出假设的数据分析方法,旨在通过作图、探索性统计等手段发现数据之间的关系、模式和趋势。
C)一般数据科学项目中,通常会先进行探索性分析,以了解数据的特征、关系和规律,然后基于探索性分析的结果进行验证性分析,对已有的假设或理论进行验证和推断。
D)验证性分析并不是通过作图、制表、方程拟合、计算特征量等手段验证数据的质量,而是验证数据的相关假设或理论的准确性和可靠性。
因此,选项C)一般数据科学项目中,探索性分析在先,验证性分析在后,描述正确。
-
下列选项中不是数据审计方法的是:()。
A)预定义审计
B)探索性审计
C)自定义审计
D)可视化审计。【解析】选项B描述的是"探索性审计",而不是常见的数据审计方法之一。
数据审计是对数据的检查和评估过程,旨在确保数据的完整性、准确性、一致性和可靠性。常见的数据审计方法包括:
A)预定义审计:基于事先定义的规则和标准对数据进行审计,如数据完整性约束、数据一致性规则等。
C)自定义审计:根据特定的业务需求和数据要求,自定义审计规则和方法进行数据审计,满足特定的审计目标。
D)可视化审计:利用可视化工具和技术对数据进行审计,以图表、图形、仪表盘等形式展示数据的审计结果和趋势。
选项B)探索性审计并不是常见的数据审计方法之一,它描述的是一种探索性数据分析方法,用于发现数据中的模式、关系和趋势,而不是针对数据的审计目的。
因此,选项B)探索性审计不是数据审计方法。
-
以下哪些选项是噪声数据的存在形式?()
A)错误数据
B)虚假数据
C)异常数据
D)以上选项均是【解析】噪声数据是指数据中存在的不符合真实情况或干扰分析结果的数据。以下选项描述了噪声数据的不同存在形式:
A)错误数据:指数据中的错误、不准确或误差较大的数据。
B)虚假数据:指故意制造或伪造的数据,与真实情况不符。
C)异常数据:指与其他数据明显不同或超出正常范围的数据,可能是数据采集或记录过程中的异常情况引起的。
因此,选项D)以上选项均是噪声数据的存在形式。
-
以下哪个数据分布方式不是连续性随机变量的典型分布方式? ( ).
A)泊松分布
B)正态分布
C)卡方分布
D)t分布。【答案】A)泊松分布。
【解析】选项A)泊松分布不是连续性随机变量的典型分布方式,而是离散性随机变量的一种常见分布。泊松分布用于描述在一定时间或空间范围内事件发生的次数的概率分布。
B)正态分布(也称为高斯分布)是连续性随机变量的最常见分布方式,具有钟形曲线的形状。
C)卡方分布是连续性随机变量的一种常见分布,常用于统计推断中。
D)t分布是连续性随机变量的一种常见分布,特别适用于小样本情况下对总体均值的推断。
因此,选项A)泊松分布不是连续性随机变量的典型分布方式。
-
根据训练经验的控制程度(即对施教者的依赖程度),可以将学习中的控制活动分为:()
A)不控制
B)部分控制
C)完全控制
D)以上选项均是。【解析】根据训练经验的控制程度,学习中的控制活动可以分为不控制、部分控制和完全控制三种情况。
A)不控制:指学习过程中没有对施教者的依赖或干预,学习者自主进行学习活动。
B)部分控制:指学习过程中施教者对学习者进行一定程度的引导、监督或干预,但学习者仍保有一定的自主性。
C)完全控制:指学习过程中施教者对学习者的学习活动进行全面的引导、监督和干预,学习者的行为完全受施教者控制。
因此,根据训练经验的控制程度,学习中的控制活动可以涵盖不控制、部分控制和完全控制,选项D)以上选项均是。
-
基于实例的学习方法有时也被称为学习法。( )
A)消极
B)积极
C)主动
D)自动【解析】选项A是正确的。基于实例的学习方法有时也被称为"消极"学习,因为它不会立即从实例中进行学习或构造一个全局的模型。相反,它会在查询时从相关实例中进行学习,因此称为"消极"。这种方法的一个优点是可以处理具有大量输入属性的问题,但其缺点是查询的计算成本较高。
-
线性拟合问题中容易出现的问题有哪些? ( )。
A)欠拟合
B)过拟合
C)完全拟合
D)A和B均是【解析】在线性拟合问题中,容易出现的问题有欠拟合和过拟合。
A)欠拟合(Underfitting)指模型无法捕捉到数据中的真实模式或关系,导致模型的预测能力较差。
B)过拟合(Overfitting)指模型过度拟合训练数据,过于复杂地适应了训练数据中的噪声和细节,导致在新数据上的预测性能下降。
C)完全拟合是指模型恰好能够完全匹配训练数据,但可能无法泛化到新的数据。
因此,选项D)A和B均是描述了在线性拟合问题中容易出现的问题。
-
以下关于决策树学习特点中错误的是:()。
A)具有较为特定的应用场景
B)使用的前提条件较为宽松
C)训练数据中允许包含错误
D)训练数据中可以存在缺少属性值的实例。【解析】选项B描述错误。
决策树学习具有以下特点:
A)具有较为特定的应用场景:决策树学习适用于分类和回归等任务,可以应用于各种领域和问题。
B)使用的前提条件较为严格:决策树学习需要有足够的训练数据,特征属性需要具有一定的信息量,且数据之间存在一定的关联性。
C)训练数据中允许包含错误:决策树学习可以容忍训练数据中的错误或噪声,但过多的错误可能会影响模型的性能。
D)训练数据中可以存在缺少属性值的实例:决策树学习可以处理训练数据中存在缺失属性值的情况,常用的方法是利用其他属性进行推断或填充缺失值。
因此,选项B)使用的前提条件较为宽松描述错误,应为较为严格。
-
人工神经网络的连接方式不包括下列哪层? ( )。
A)输入层
B)输出层
C)转化层
D)隐含层【解析】人工神经网络的连接方式包括输入层、输出层和隐含层。
A)输入层:接收外部输入的数据,并将其传递给下一层进行处理。
B)输出层:输出神经网络对输入数据的处理结果。
C)转化层并不是人工神经网络的一种常见术语或连接方式。
D)隐含层(也称为隐藏层)是人工神经网络中介于输入层和输出层之间的一层或多层神经元组成的层,用于进行数据的中间转化和处理。
因此,选项C)转化层不是人工神经网络的一种连接方式。
简答题(25分)
-
请简述结构化数据、非结构化数据与半结构化数据的区别与联系?
结构化数据
- 即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现
- 先有结构、再有数据
非结构化数据(包含半结构化)
- 包括所有格式的办公文档、文本、图片等
半结构化数据
- 介于完全结构化数据(如关系型数据库、面向对象数据库中的数据)和完全无结构的数据(如声音、图像文件等)之间
- 例:HTML 文档属于半结构化数据
- 它一般是自描述的,数据的结构和内容混在一起,没有明显的区分
- 先有数据,再有结构
-
数据科学的基本流程是什么?
-
定义问题:这是数据科学项目的初始阶段,主要是为了理解业务目标,确定具体要解决的问题。
-
数据收集:在确定了要解决的问题后,数据科学家会从各种来源(数据库、文件、网络、API接口等)收集需要的数据。
-
数据清洗与预处理:这个阶段的目的是消除数据中的错误和不一致性,这通常包括处理缺失值、异常值,以及进行数据转换、规范化等。
-
数据探索与分析:在这个阶段,数据科学家会使用各种统计分析和可视化工具来理解数据的基本特性,发现数据之间的关系,以及识别可能的模式和趋势。
-
特征工程:在这个阶段,数据科学家会通过创建新的特征(例如,根据已有特征进行组合、转换等)来提取更多的信息,以帮助建立更好的模型。
-
建立模型:这个阶段,数据科学家会使用适当的算法和技术(例如,决策树、随机森林、支持向量机、神经网络等)来构建预测或分类模型。
-
模型评估与优化:在这个阶段,数据科学家会使用不同的评价指标(例如,准确率、精确率、召回率、F1得分、ROC曲线下的面积等)来评估模型的性能,并根据结果进行模型调优。
-
部署与监控:最后,构建的模型会被部署到生产环境中,并持续监控模型的性能,以确保其在新的数据上依然表现良好。
-
-
对于大数据而言,传统的关系数据库有什么问题?为什么?
关系数据库的关键特性包括:完善的事务机制,高效的查询机制, 但是,关系数据库引以为傲的两个关键特性,到了大数据时代却成了鸡肋,主要表现在以下几个方面:
- 网站系统通常不要求严格的数据库事务
- 并不要求严格的读写实时性
- 通常不包含大量复杂的 SQL 查询(去结构化,存储空间换取更好的查询性能)
因此传统数据库无法满足大数据时代的要求:
- 无法满足海量数据的管理需求
- 无法满足数据高并发的需求
- 无法满足高可扩展性和高可用性的需求
-
NoSql类型的数据库有哪四大类型?请解释其中1种
NoSQL(Not Only SQL)类型的数据库主要有四大类,分别是:键值存储数据库,列存储数据库,文档数据库和图形数据库。
-
键值存储数据库:这是最简单的NoSQL数据库类型。每个数据项都存储为一个键值对。键是唯一的,值则可以采取多种形式。这种类型的数据库具有高度的扩展性和灵活性。一些典型的键值存储数据库包括Redis、Riak和DynamoDB。
-
列存储数据库:也被称为宽列存储,它使用键仍然存在,但它们指向多个列。这些列被组织成列族,每个列族可以有任意数量的列。列存储数据库适合处理大量数据和大量列,且可以很容易地进行水平扩展。一些典型的列存储数据库包括Cassandra和HBase。
-
文档数据库:在文档数据库中,数据被存储为一个文档,通常采用JSON或者XML格式。每个文档都有一个唯一的键,该键用于检索文档,文档内部的数据可以用查询语言进行访问和操作。文档数据库适合存储非结构化或半结构化的数据,因为它们提供了非常灵活的数据模型。一些典型的文档数据库包括MongoDB和CouchDB。
-
图形数据库:图形数据库是专门为处理图形数据而设计的,它们可以存储节点、边以及这些实体之间的关系。图形数据库非常适合处理复杂的关系查询,例如社交网络分析、路径查找等。一些典型的图形数据库包括Neo4j和JanusGraph。
-
-
什么是ETL 为什么需要ETL?
ETL是数据处理过程中的一种常用方法,代表"Extract, Transform, Load"(提取,转换,加载)的三个阶段。
- 提取(Extract):这是从各种数据源(包括关系数据库、非结构化数据源等)获取数据的过程。在这个阶段,系统会读取不同的数据格式和结构,然后将这些数据提取出来供后续处理。
- 转换(Transform):在这个阶段,对提取出来的数据进行清洗、标准化、集成和转化,以满足目标系统的数据要求。这可能包括数据的格式转换、单位转换、编码转换,也可能包括复杂的业务规则处理。
- 加载(Load):这是将转换后的数据加载到目标系统(如数据仓库)的过程。在这个阶段,经过转换处理的数据被写入到目标数据库中,以便进行后续的数据查询和分析。
为什么需要ETL:
- 数据一致性:企业内部的数据可能来源于各种各样的系统,这些系统可能有各自的数据格式和标准。ETL可以帮助将这些数据转换为统一的格式,从而保证数据的一致性。
- 数据质量:ETL过程中的转换阶段可以帮助改善数据质量。比如,数据清洗可以去除重复数据,纠正错误的数据,从而提高数据质量。
- 数据集成:ETL过程可以帮助集成来自不同源的数据,为企业提供一个全面的数据视图,这对于数据分析和决策支持非常重要。
- 性能优化:ETL过程中,可以根据目标系统的查询需求对数据进行适当的预处理,如数据聚合,数据索引等,这样可以优化查询性能,提高数据分析的效率。
-
噪声数据处理有哪些方法?请至少给出两种方法
-
分箱 Binning
-
聚类 Clustering
-
回归 Regression
-
-
什么是数据脱敏?实现数据脱敏的原则是什么(请给出至少两个原则)
数据脱敏是一种保护敏感信息的技术,它通过修改、屏蔽或删除数据中的敏感信息(如身份证号、电话号码、邮箱地址、银行账号等)来防止这些信息被不必要的或恶意的第三方获取,从而保护用户的隐私和数据安全。
数据脱敏的原则是:单向性、无残留、易于实现
-
在K-means聚类算法中,如何确定k个族的初始质心
-
随机选择:这是最简单的方法,就是从数据集中随机选择k个样本作为初始的质心。
-
贪心策略:首先随机选择一个样本作为第一个质心,然后对于2到k个质心,每次都选择离已选质心集合最远的一个数据点。
-
层次聚类法:首先使用层次聚类算法(如凝聚型或分裂型)进行聚类,
-
分布式选择:在大数据场景下,可以在各数据分片上分别使用K-means++等方法选择初始质心,然后将各分片的初始质心聚合,再从中选择k个作为全局的初始质心。
-
人工选择:在某些应用场景下,如果对数据有深入的理解,也可以人工选择初始质心。例如,在空间聚类中,可以根据地理位置的分布特性来选择。
参考自PPT《04》- 65
-
-
什么是机器学习?机器学习的基本思路是什么?机器学习有什么应用?
机器学习是计算机从数据中学习模式和规律,从而自动进行预测,分类和识别,无需明确编程。
机器学习可以分为监督学习,无监督学习,半监督学习和强化学习等多种类型。
-
监督学习:在监督学习中,模型在已知输入和输出的数据集(称为训练数据集)上进行训练。然后,模型被用于预测新的、未知的数据的输出。
-
无监督学习:在无监督学习中,模型在没有已知输出的数据集上进行训练。这种类型的学习试图找出数据的内在结构和模式。
-
半监督学习:半监督学习是监督学习和无监督学习的结合体,训练数据包含已标记和未标记的数据。
-
强化学习:强化学习是机器通过与环境的交互学习行为的过程。这种类型的学习依赖于奖励(或惩罚)机制来指导模型做出最优决策。
机器学习的应用广泛且多样,包括以下几个重要的领域:
- 推荐系统:许多电子商务网站、音乐和电影流媒体服务都使用机器学习来推荐用户可能感兴趣的产品或内容。例如,Netflix和Spotify都使用机器学习来分析用户的观看或收听习惯,从而推荐相似的内容。
- 自然语言处理:机器学习广泛应用于文本翻译,情感分析,语音识别和生成,聊天机器人等领域。例如,Google翻译和Siri就使用了这种技术。
-
-
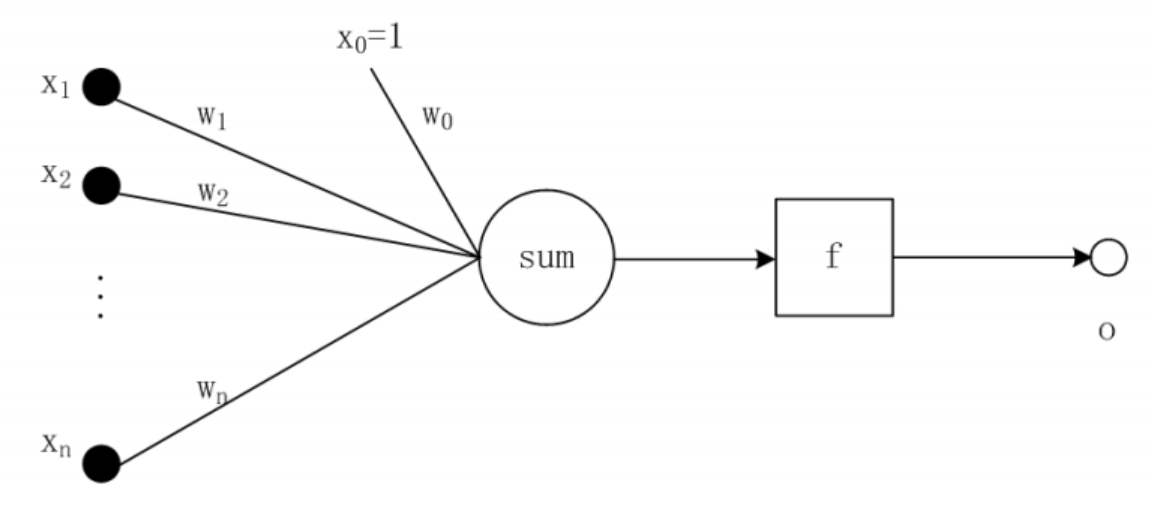
人工神经网络的最基本的组成是什么 什么是感知器 请解释并画出示意图
“人工神经元”是人工神经网络的最基本的组成部分。
感知器(Perceptron)是实现人工神经元的一种方法
-
解释多层网络的bp算法,只需要从大体上解释思路
-
初始化网络权重:这些权重通常是随机选取的,可以使网络学习到多种多样的特征。
-
前向传播:输入数据在网络中从输入层传递到隐藏层,然后再到输出层。
-
计算误差:一旦数据通过网络传递并生成了预测输出,我们就可以根据真实的目标输出和预测输出计算误差(损失函数)。
-
反向传播误差:从输出层开始,逐层向后计算误差,以得到每个权重对总误差的贡献。(应用链式法则)
-
更新权重:按照一定的学习速率更新权重以最小化损失函数。
-
重复迭代:以上过程会在多个训练周期(Epoch)中反复执行。
-
-
人工神经网络适合解决哪些类别的问题(请给出至少2种类别)
-
实例是采用“属性-值”(实际上就是特征)对表示
-
目标函数的输出可能是离散值、实数值或者由若干实数属性或离散属性组成的向量
-
训练数据可能包含错误
-
可容忍长时间的训练
-
需要快速求出目标函数值
-
不需要人类理解目标函数
-
-
什么是贝叶斯学习?其本质是什么?请给出你的理解
贝叶斯学习是一种基于贝叶斯定理的机器学习方法,它在处理统计推断和不确定性问题方面有其独特的优势。
贝叶斯学习的本质是:考虑已知数据的条件下,对参数或者模型的不确定性进行量化。
贝叶斯学习的核心思想是,先设定一个先验概率,这个先验概率表示在看到数据之前,我们对模型参数的信念。然后,当我们观察到新的数据时,我们可以使用贝叶斯定理来更新我们对模型参数的信念,**得到一个后验概率。**这个后验概率取决于我们的先验概率和观察到的数据。
贝叶斯学习的优势之一是,它能够更好地处理过拟合问题。因为在贝叶斯框架下,我们不是选择一个单一的模型或参数,而是考虑了所有可能的模型和参数,用它们的概率分布来表示。
-
请对比UserCF协同过滤算法和ItemCF协同过滤算法 分析他们的适用范围和优缺点
-
UserCF算法推荐的是那些和目标用户有共同兴趣爱好的其他用户所喜欢的物品
-
ItemCF算法推荐的是那些和目标用户之前喜欢的物品类似的其他物品
-
UserCF算法的推荐更偏向社会化,而ItemCF算法的推荐更偏向于个性化
-
UserCF缺点:随着用户数目的增大,用户相似度计算复杂度越来越高。
-
ItemCF缺点:倾向于推荐与用户已购买商品相似的商品,往往会出现多样性不足、推荐新颖度较低的问题
-
-
关系数据库和nosql有什么优点和缺点
关系数据库和 NoSQL 数据库各自有其优点和缺点,选择哪一种依赖于特定应用的需求。
关系数据库(例如 MySQL,PostgreSQL,Oracle 等):
优点:
- 结构化查询语言(SQL):这是一种强大的查询语言,可以进行复杂的查询。
- 事务处理:关系数据库可以支持事务处理(ACID原则:原子性、一致性、隔离性和持久性),这对于需要保证数据一致性的应用至关重要。
- 成熟稳定:关系数据库已经存在了几十年,它们经过了时间的考验,并有大量的工具、文档和社区支持。
缺点:
- 扩展性:关系数据库通常在单个服务器上运行,这意味着水平扩展(将数据分布在多个服务器上)是一个挑战。
- 灵活性:关系数据库需要预定义的模式,这使得在动态和快速发展的应用中对数据结构的更改变得困难。
NoSQL 数据库(例如 MongoDB,Cassandra,Redis 等):
优点:
- 扩展性:NoSQL 数据库通常支持水平扩展,即将数据分布在多个服务器上,这使得它们能够处理大规模的数据。
- 灵活性:许多 NoSQL 数据库支持无模式数据,这使得它们在处理复杂或不规则的数据时具有更高的灵活性。
缺点:
- 一致性:为了实现可扩展性,许多 NoSQL 数据库选择放宽一致性要求(基于CAP理论)。
- 成熟度:相比于关系数据库,NoSQL 数据库的历史较短,工具和支持可能没有那么全面。
-
什么是数据预处理?(请从为什么要对数据进行预处理,以及数据的预处理需要做哪些事这两个方面阐述你的理解)
数据预处理是将原始数据转化为更适合数据分析或机器学习模型使用的形式的过程。这是大多数机器学习项目中的一个重要步骤,因为质量好的数据是提高模型性能的关键。
为什么要对数据进行预处理?
-
质量问题:原始数据往往存在各种问题,比如缺失值、噪声、异常值、重复数据等。
-
数据一致性:在很多情况下,数据来自不同的来源,可能有不同的格式、度量单位等。
-
提高模型性能:很多机器学习算法要求数据具有特定的特性,比如正态分布、均匀分布等。对数据进行预处理,可以帮助改善这些特性,从而提高模型的性能。
数据预处理需要做哪些事?
- 数据清洗:这包括处理缺失值、消除噪声和异常值、去除重复数据等。
- 数据特征化:这包括特征选择、特征提取、特征构造等,这些都是为了改善模型的性能。
- 数据集成:数据可能来自多个数据源,需要将它们合并到一个统一的数据集中。
- 数据转化:这包括规范化、标准化以及其他的转换方法,以改善数据的分布特性。
- 数据序列化和反序列化:这是指将数据结构或对象状态转换为可以存储或传输的形式,以便稍后在相同或另一台机器上重建。
-
-
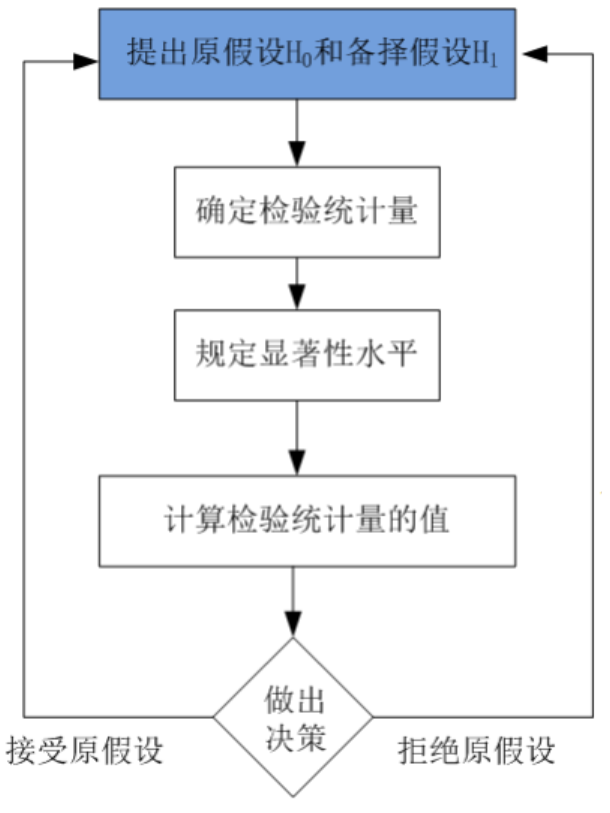
什么是假设检验?假设检验的标准步骤有哪些(可用文字或图表进行描述)?
假设检验是一种统计方法,用于决定一个关于总体参数的假设是否成立。这个过程涉及到假设的提出以及基于样本数据对这个假设的检验。
-
在k-Means聚类算法中:k个簇的质心是如何被最终确定下来的?
在K-Means算法中,k个簇的质心是通过以下步骤确定的:
- 初始化:首先,随机选择K个数据点作为初始质心。
- 分配数据点到最近的簇:对于数据集中的每个点,计算它到所有K个质心的距离,并将其分配到最近的簇中。
- 更新质心:对于每个簇,计算所有属于这个簇的数据点的平均值,然后将这个平均值作为新的质心。
- 迭代:重复步骤2和步骤3,直到质心的位置不再显著改变,或者达到预设的最大迭代次数。在这个过程中,质心会逐渐移到一个位置,使得它是其簇内所有数据点的平均位置,即最小化其簇内所有数据点到它的距离。
设计题(30分)
-
市想应用已有的购物数据做关联规则分析。假设经过初步统计后,有如下表所示的购物记录。
购物者 ID 所购商品。 1 面包, 牛奶, 啤酒, 尿布 2 面包, 尿布, 可乐。 3 牛奶,面包,尿布 4 牛奶,啤酒 5 面包, 啤酒, 鸡蛋 6 牛奶,尿布,可乐 \begin{array}{|c|l|} \hline \text { 购物者 ID } & {\text { 所购商品。 }} \\ \hline \text { 1 } & \text { 面包, 牛奶, 啤酒, 尿布 } \\ \hline \text { 2 } & \text { 面包, 尿布, 可乐。 } \\ \hline \text { 3 } & \text { 牛奶,面包,尿布 } \\ \hline \text { 4 } & \text { 牛奶,啤酒 } \\ \hline \text { 5 } & \text { 面包, 啤酒, 鸡蛋 } \\ \hline \text { 6 } & \text { 牛奶,尿布,可乐 } \\ \hline \end{array} 购物者 ID 1 2 3 4 5 6 所购商品。 面包, 牛奶, 啤酒, 尿布 面包, 尿布, 可乐。 牛奶,面包,尿布 牛奶,啤酒 面包, 啤酒, 鸡蛋 牛奶,尿布,可乐
请应用已知的关联规则分析算法来分析表中的数据,找出三级频繁项集,并说明应用的分析算法的原理是什么?【解】
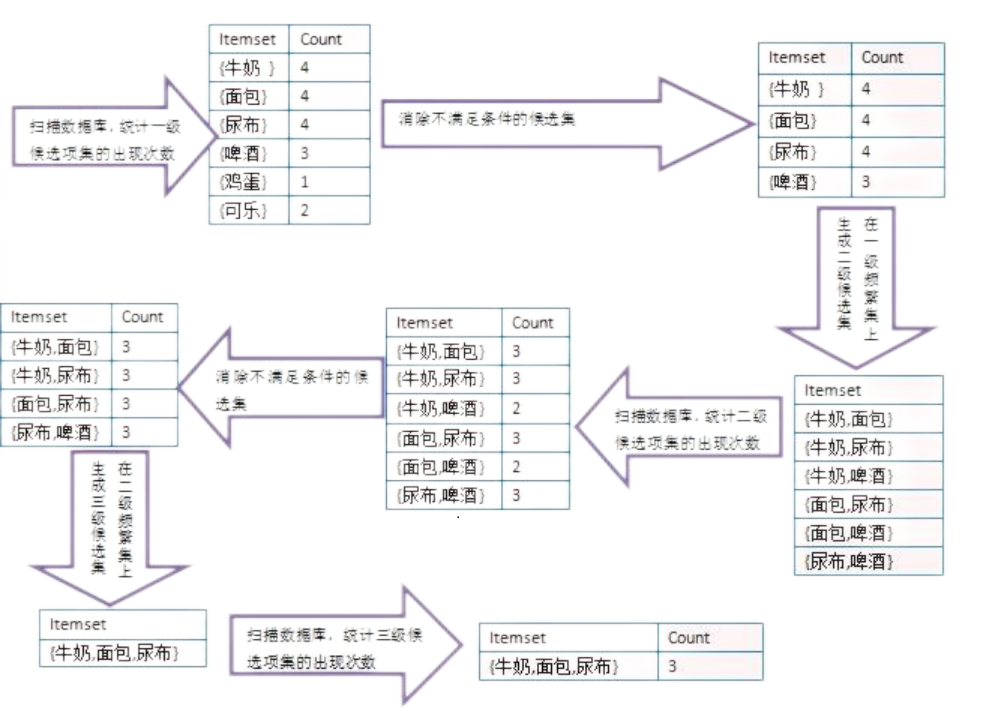
应用 A p r i o r i \mathrm{Apriori} Apriori 算法,定律如下:
- 如果一个集合是频繁项集,则它的所有子集都是频繁项集。
- 如果一个集合不是频繁项集,则它的所有超集都不是频繁项集
-
显示的是一个房间平面图。共有5个房间,标号为{0,1,2,3,4)。5号为整个房间的出口,也就的地所在。先需要用增强学习的Q函数(Q-leaming) 方法来训练一一个agent, 始之能够学习何走向5号目的地的最佳路径。图2是对应的房间状态转移图(包括权重)。假设Q-leaming中的学习参数为0.8,根据状态转移图,请给出 R e w a r d \mathrm{Reward} Reward 矩阵
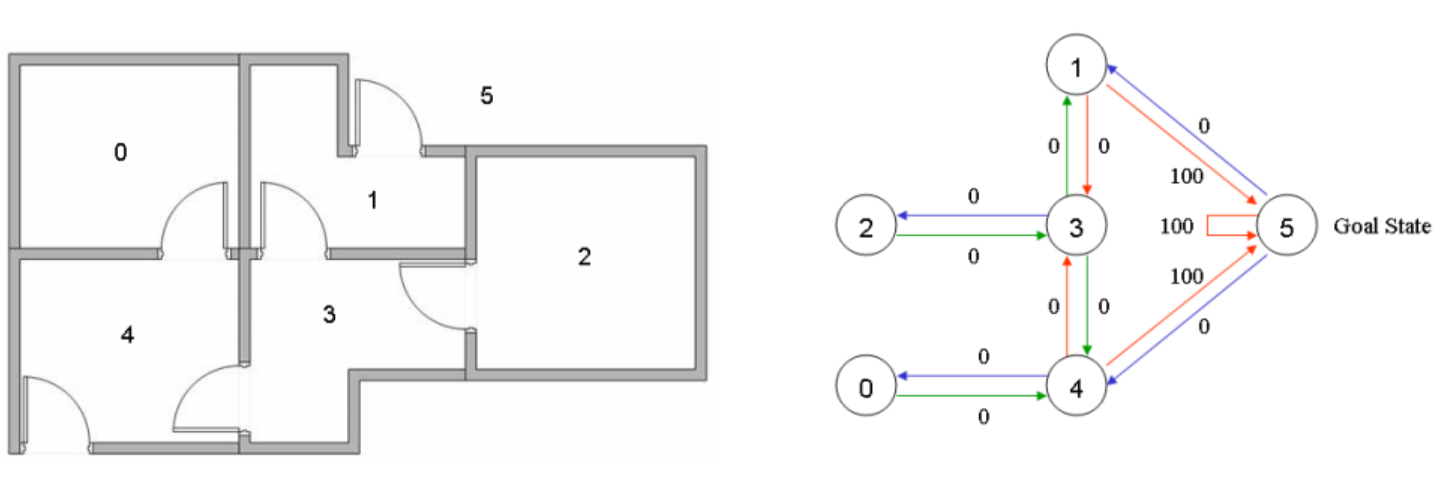
【解析】
Q-learning是一种无模型的强化学习算法,它试图通过“试错”(trial-and-error)来找到最优策略,即最大化累积奖励的策略。它包括一个状态空间,一个动作空间,以及一个Q-table用于存储每个(state, action)对的预期奖励。在每一步,Q-learning算法选择一个动作,观察结果状态并收集的奖励(Reward),然后更新Q-table。
R图(R-Table,即Reward Table)类似于Q图,表示的是智能体在每个状态下执行每个动作后实际获得的即时奖励。在R图中,每一行代表一个状态,每一列代表一个动作,每个元素R(s, a)代表智能体在状态s下执行动作a后获得的奖励。
A c t i o n 0 1 2 3 4 5 0 1 2 3 4 5 [ − 1 − 1 − 1 − 1 0 − 1 − 1 − 1 − 1 0 − 1 100 − 1 − 1 − 1 0 − 1 − 1 − 1 0 0 − 1 0 − 1 0 − 1 − 1 0 − 1 100 − 1 0 − 1 − 1 0 100 ] \mathrm{Action}\\ \quad\quad0\quad \quad 1 \quad \space2 \quad \quad3 \quad \quad4 \quad\quad 5 \\ \begin{gathered} 0 \\ 1 \\ 2 \\ 3 \\ 4 \\ 5 \end{gathered}\left[\begin{array}{rrrrrr} -1 & -1 & -1 & -1 & 0 & -1 \\ -1 & -1 & -1 & 0 & -1 & 100 \\ -1 & -1 & -1 & 0 & -1 & -1 \\ -1 & 0 & 0 & -1 & 0 & -1 \\ 0 & -1 & -1 & 0 & -1 & 100 \\ -1 & 0 & -1 & -1 & 0 & 100 \end{array}\right] Action01 2345012345 −1−1−1−10−1−1−1−10−10−1−1−10−1−1−100−10−10−1−10−10−1100−1−1100100
举个例子,在R图中,R(1,5) 表示agent从1走到5获得的奖励(Reward)为100,而R(1,3)表示agent从1走到3的奖励为0(奖励是根据权重图写出来的)接着我们初始化Q图为 6 × 6 6\times 6 6×6 全零矩阵
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ] \left[ \begin{array}{rrrrrr} 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \end{array}\right] 000000000000000000000000000000000000
在每一步,我们根据以下公式更新Q值:Q ( s t a t e , a c t i o n ) = R ( s t a t e , a c t i o n ) + α ∗ max Q ( n e x t _ s t a t e , a c t i o n ) \mathrm{Q(state, action) = R(state, action) + \alpha * \max{Q(next\_state, action)}} Q(state,action)=R(state,action)+α∗maxQ(next_state,action)
其中 α \alpha α 是学习参数(0.8)接下来每次迭代可以自行假设从哪个房间出发(实际应用就是以某种概率选取)
-
agent从房间1出发,则有房间3和5两个状态选择,假设先选择房间5作为房间1的下一个状态,因为房间5是目的地,此轮episode训练结束。
Q ( 1 , 5 ) = R ( 1 , 5 ) + 0.8 ∗ max { Q ( 5 , 1 ) , Q ( 5 , 4 ) , Q ( 5 , 5 ) } = 100 + 0.8 ∗ max { 0 , 0 , 0 } = 100. \begin{aligned} Q(1,5) & =R(1,5)+0.8 * \max \{Q(5,1), Q(5,4), Q(5,5)\} \\ & =100+0.8 * \max \{0,0,0\} \\ & =100 . \end{aligned} Q(1,5)=R(1,5)+0.8∗max{Q(5,1),Q(5,4),Q(5,5)}=100+0.8∗max{0,0,0}=100. -
agent选择从房间3出发,经过房间1,然后选择目的房间5,此轮episode训练结束。
Q ( 3 , 1 ) = R ( 3 , 1 ) + 0.8 = max { Q ( 1 , 3 ) , Q ( 1 , 5 ) } = 0 + 0.8 max { 0 , 100 } = 80 Q ( 1.5 ) = R ( 1 , 5 ) + 0.8 = max { Q ( 5 , 1 ) , Q ( 5 , 4 ) , Q ( 5 , 5 ) } = 100 + 0.8 max { 0 , 0 , 0 } = 100 \begin{aligned} Q(3,1) & =R(3,1)+0.8=\max \{Q(1,3), Q(1,5)\} \\ & =0+0.8\max \{0,100\} \\ & =80 \\ Q(1.5)& =R(1,5)+0.8=\max \{Q(5,1), Q(5,4), Q(5,5)\} \\ & =100+0.8\max \{0,0,0\} \\ & =100 \end{aligned} Q(3,1)Q(1.5)=R(3,1)+0.8=max{Q(1,3),Q(1,5)}=0+0.8max{0,100}=80=R(1,5)+0.8=max{Q(5,1),Q(5,4),Q(5,5)}=100+0.8max{0,0,0}=100 -
…
如此迭代数次之后就能得到Q图,由此可以解读出最佳路径:由于目的地是房间5,因此我们可以从任何一个房间开始,查看Q图,选择Q值最大的动作,直到到达房间5。这样就可以得到从起始房间到房间5的最佳路径。例如,如果在房间1的Q值中,去房间5的Q值最大,那么我们就选择去房间5的动作。如果在房间3的Q值中,去房间1的Q值最大,那么我们就选择去房间1的动作,然后再按照房间1的最大Q值选择下一个动作,这样就形成了一条路径。
【解】
A c t i o n 0 1 2 3 4 5 s t a t e 0 1 2 3 4 5 [ − 1 − 1 − 1 − 1 0 − 1 − 1 − 1 − 1 0 − 1 100 − 1 − 1 − 1 0 − 1 − 1 − 1 0 0 − 1 0 − 1 0 − 1 − 1 0 − 1 100 − 1 0 − 1 − 1 0 100 ] \mathrm{Action}\\ \quad\quad\quad\quad0\quad \quad 1 \quad \quad2 \quad \quad3 \quad \quad4 \quad\quad 5 \\ \mathrm{state}\quad \begin{gathered} 0 \\ 1 \\ 2 \\ 3 \\ 4 \\ 5 \end{gathered}\left[\begin{array}{rrrrrr} -1 & -1 & -1 & -1 & 0 & -1 \\ -1 & -1 & -1 & 0 & -1 & 100 \\ -1 & -1 & -1 & 0 & -1 & -1 \\ -1 & 0 & 0 & -1 & 0 & -1 \\ 0 & -1 & -1 & 0 & -1 & 100 \\ -1 & 0 & -1 & -1 & 0 & 100 \end{array}\right] Action012345state012345 −1−1−1−10−1−1−1−10−10−1−1−10−1−1−100−10−10−1−10−10−1100−1−1100100
-
-
通过把报纸的每页分别扫描为电子版图片,美国纽约时报实现了电子化所有的报纸文档。但是这些电子化的报纸并没有每份把报纸整合为张完整的报纸。 因为需要把这些报纸的电子版放到网上,所以需要对每份报纸进行整合(也就是需要把每份报纸对应的每页电子版图片合并为一张大图片,以便放到网上方便览)。但这些图片数量极其庞大(约有1500G),单个计算机在短时间内无法完成该任务。请你设计一种计算模式能在较短的时间内完成该项报纸整合任务。
1)请给出你设计的计算 模式或者已有的适合该任务的计算模式(也就是编程模型)以及该技术的基本原理或结构。
2)在该计算模式下,请你给出报纸整合任务的步骤。
【解】在处理这种大数据问题时,我们通常使用分布式计算模型,比如Hadoop的MapReduce或者Spark框架。在这种模式下,数据被分散到许多不同的节点上进行处理,然后再将结果集中起来。这可以大大提高处理大量数据的能力。
1)技术选择:Spark框架
基本原理:Spark是一个大数据处理工具,它提供了一个快速、通用的计算系统。Spark的核心是一个计算引擎,它支持任务调度、内存管理和错误恢复。用户可以使用Spark的高级API来处理数据,包括SQL查询、流式计算、机器学习和图计算。Spark支持在许多不同的系统上运行,包括Hadoop、Kubernetes和Mesos等。
2)报纸整合任务的步骤:
(1)数据准备:首先,将所有报纸的电子版图片上传到分布式文件系统(比如Hadoop HDFS)中。每份报纸的所有页面图片应当组织在同一个文件夹中,以报纸的日期或者其他唯一标识命名。
(2)数据处理:
-
读取数据:在Spark中,我们首先需要读取分布式文件系统中的数据。这可以通过使用Spark的API完成。我们可以创建一个RDD(弹性分布式数据集),每个元素对应一份报纸的所有页面图片。
-
数据处理:在每个RDD的元素上(也就是每份报纸),我们需要执行图片合并操作。这个操作可以通过使用Spark的map操作完成。在map操作中,我们对每份报纸的所有页面图片执行合并操作,生成一张大图片。
-
结果保存:将处理后的结果保存回分布式文件系统中。这可以通过使用Spark的save操作完成。
-
-
已知6部电影的类型(样本集及每个样本的分类标签)及其中出现的亲吻次数和打斗次数(特征信息),如下表所示。现有一部为未分类的电影,知道其中的打斗次数和接吻次数分别为18和90。
电影名称。 打斗镜头。 接吻镜头 电影类型 电影 A 3 104 爱情片 电影 B 2 100 爱情片 电影 C 1 81 爱情片 电影 D 101 10 动作片 电影 E 99 5 动作片 电影 F 98 2 动作片 \begin{array}{|c|c|c|c|} \hline \text { 电影名称。 } & \text { 打斗镜头。 } & \text { 接吻镜头 } & \text { 电影类型 } \\ \hline \text { 电影 } \mathrm{A} & 3 & 104 & \text { 爱情片 } \\ \hline \text { 电影 } \mathrm{B} & 2 & 100 & \text { 爱情片 } \\ \hline \text { 电影 } \mathrm{C} & 1 & 81 & \text { 爱情片 } \\ \hline \text { 电影 } \mathrm{D} & 101 & 10 & \text { 动作片 } \\ \hline \text { 电影 } \mathrm{E} & 99 & 5 & \text { 动作片 } \\ \hline \text { 电影 } \mathrm{F} & 98 & 2 & \text { 动作片 } \\ \hline \end{array} 电影名称。 电影 A 电影 B 电影 C 电影 D 电影 E 电影 F 打斗镜头。 3211019998 接吻镜头 104100811052 电影类型 爱情片 爱情片 爱情片 动作片 动作片 动作片
请应用己知的方法给该未分类的电影分类(即确定该电影是爱情片还是动作片)。
注:若所用方法中有参数k,令k=4。【解】这个问题可以用K近邻算法(K-Nearest Neighbors,简称KNN)来解决。KNN是一种分类算法,它的思想是找出新样本最近的k个已分类样本,然后看看这些样本中哪一类别的样本最多,新样本就被判定为那个类别。
具体步骤如下:
-
计算未分类电影(打斗次数18,接吻次数90)到每个已分类电影的距离。在此例中,我们可以使用欧几里得距离(Euclidean distance)。
-
找出距离最近的k个已分类电影。这里,k=4。
-
看看这4部电影中哪种类型的电影最多,那么未分类电影就被判定为那个类型。
计算距离的公式为:
距离 = ( 打斗次数 1 − 打斗次数 2 ) 2 + ( 接吻次数 1 − 接吻次数 2 ) 2 距离 = \sqrt{(打斗次数1 - 打斗次数2)^2 + (接吻次数1 - 接吻次数2)^2} 距离=(打斗次数1−打斗次数2)2+(接吻次数1−接吻次数2)2计算出未分类电影到每部已分类电影的距离如下:
- 电影A的距离 = ( 18 − 3 ) 2 + ( 90 − 104 ) 2 = 20.5 \sqrt{(18 - 3)^2 + (90 - 104)^2} = 20.5 (18−3)2+(90−104)2=20.5
- 电影B的距离 = ( 18 − 2 ) 2 + ( 90 − 100 ) 2 = 18.9 \sqrt{(18 - 2)^2 + (90 - 100)^2} = 18.9 (18−2)2+(90−100)2=18.9
- 电影C的距离 = ( 18 − 1 ) 2 + ( 90 − 81 ) 2 = 20.2 \sqrt{(18 - 1)^2 + (90 - 81)^2} = 20.2 (18−1)2+(90−81)2=20.2
- 电影D的距离 = ( 18 − 101 ) 2 + ( 90 − 10 ) 2 = 115.3 \sqrt{(18 - 101)^2 + (90 - 10)^2} = 115.3 (18−101)2+(90−10)2=115.3
- 电影E的距离 = ( 18 − 99 ) 2 + ( 90 − 5 ) 2 = 117.4 \sqrt{(18 - 99)^2 + (90 - 5)^2} = 117.4 (18−99)2+(90−5)2=117.4
- 电影F的距离 = ( 18 − 98 ) 2 + ( 90 − 2 ) 2 = 118.9 \sqrt{(18 - 98)^2 + (90 - 2)^2} = 118.9 (18−98)2+(90−2)2=118.9
所以,距离最近的4部电影是A, B, C, F。其中,A, B, C是爱情片,F是动作片。因此,未分类的电影被判定为爱情片。
-
-
假设我们有下表一组数据,X是流逝的秒数,Y值是随时间变换的一个数值。
X Y 1 23 1.2 17 3.2 12 4 27 5.1 8 \begin{array}{|c|c|} \hline \mathrm{X} & Y \\ \hline 1 & 23 \\ \hline 1.2 & 17 \\ \hline 3.2 & 12 \\ \hline 4 & 27 \\ \hline 5.1 & 8 \\ \hline \end{array} X11.23.245.1Y231712278
请用课程中学到的方法解答:当时间X是6.5秒时,Y值为多少? .
注:若所用方法中有参数k,令k=2。【解】
这个问题可以使用KNN(怎么又是KNN,是懂出题的)来解决。
具体步骤如下:
-
计算未知时间X(6.5秒)到每个已有时间点的距离。在此例中,我们可以使用绝对值来计算距离。
-
找出距离最近的k个已有时间点。这里,k=2。
-
计算这k个时间点对应的Y值的平均值或加权平均值,那么未知时间点的Y值就被预测为这个值。
计算距离的公式为:
距离 = ∣ X 1 − X 2 ∣ 距离 = |X1 - X2| 距离=∣X1−X2∣
计算出未知时间点到每个已有时间点的距离如下:- 时间点1的距离 = |6.5 - 1| = 5.5
- 时间点1.2的距离 = |6.5 - 1.2| = 5.3
- 时间点3.2的距离 = |6.5 - 3.2| = 3.3
- 时间点4的距离 = |6.5 - 4| = 2.5
- 时间点5.1的距离 = |6.5 - 5.1| = 1.4
所以,距离最近的2个时间点是5.1和4。它们对应的Y值分别是8和27。
distance Nearest Neigbor Value 5.5 5.3 3.3 2.5 27 1.4 8 \begin{array}{c|c} \text { distance } & \text { Nearest Neigbor Value } \\ \hline 5.5 & \\ 5.3 & \\ 3.3 & \\ 2.5 & 27 \\ 1.4 & 8 \\ \end{array} distance 5.55.33.32.51.4 Nearest Neigbor Value 278
然后,我们计算这两个时间点对应的Y值的平均值,得到:(8 + 27) / 2 = 17.5。因此,当时间X是6.5秒时,Y值预测为17.5。
-
-
某工厂利用两种燃料生产三种不同产品 A、 B、C,每消耗一吨燃料与产出产品A、B、C有下列关系:
产品 A 产品 B 产品 C 燃料甲 (Mt) 。 F 1 A F 1 B F 1 C 燃料乙 (Dt)。 F 2 A F 2 B F 2 C \begin{array}{|c|c|c|c|} \hline &产品A & \text { 产品 } B \text { } & \text { 产品 } C \\ \hline \text { 燃料甲 (Mt) 。 } & F_{1 A} & F_{1B} & F_{1 C} \\ \hline \text { 燃料乙 (Dt)。 } & F_{2A} & F_{2B} & F_{2C} \\ \hline \end{array} 燃料甲 (Mt) 。 燃料乙 (Dt)。 产品AF1AF2A 产品 B F1BF2B 产品 CF1CF2C
己知每吨燃料甲与乙的价格比为2:3,现需要三种产品A、B、C 各 W A , W B , W C W_A,W_B,W_C WA,WB,WC 吨。工厂希望合理使用两种燃料,使该厂生产成本最低。。
请使用线性规划的方法,列出相关线性方程。假设该厂使用燃料甲x吨,燃料乙y吨。燃料甲的价格为每吨2t元,燃料乙的价格为每吨3t元。
所以生产成本为 z = 2 t x + 3 t y . z=2tx+3ty. z=2tx+3ty.
列出线性约束条件:
F 1 A x + F 2 A y ≥ W A F 1 B x + F 2 B y ≥ W B F 1 C x + F 2 C y ≥ W C \begin{aligned} & F_{1 A} x+F_{2 A} y\ge W_A \\ & F_{1 B} x+F_{2 B} y\ge W_B \\ & F_{1 C} x+F_{2 C} y\ge W_C \end{aligned} F1Ax+F2Ay≥WAF1Bx+F2By≥WBF1Cx+F2Cy≥WC -
某医疗研究机构开发了一种新的药物,并声称它可以显著降低患者的血压。为验证这一声明,研究人员随机选择了100名患有高血压的患者,将他们分为两组,一组接受了新药物治疗,另一组接受了安慰剂治疗。经过治疗一段时间后,测得两组患者的平均血压如下:
新药物组. 安慰剂组. 样本数 50 50. 平均血压 (mmHg) 135 140 样本标准差 8 9 \begin{array}{|c|c|c|} \hline \text { } & \text { 新药物组. } & \text { 安慰剂组. } \\ \hline \text { 样本数 } & 50 & 50 . \\ \hline \text { 平均血压 (mmHg) } & 135 & 140 \\ \hline \text { 样本标准差 } & 8 & 9 \\ \hline \end{array} 样本数 平均血压 (mmHg) 样本标准差 新药物组. 501358 安慰剂组. 50.1409
假设两组患者的血压服从正态分布,问在显著性水平a=0.05时,是否有足够的证据支持该药物具有千预血压的作用?。(注:经查表已得题目中需要用到的检验置信水平临界值在2.58以上为非常显著,在1.96以下为不显著,在两者之间为显著)【解】我们可以使用独立样本Z检验。首先,我们可以设置原假设H0和备择假设H1。
原假设H0:新药物组和安慰剂组的平均血压没有差异;
备择假设H1:新药物组的平均血压低于安慰剂组。
接下来,我们可以计算Z统计量。两个独立样本的Z检验统计量的公式为:
μ 1 ‾ − μ 2 ‾ ( σ 1 2 n 1 ) + ( σ 2 2 n 2 ) \frac{\overline{\mu_1}-\overline{\mu_2}}{\sqrt{\left(\frac{\sigma_1^2}{n_1}\right)+\left(\frac{\sigma_2^2}{n_2}\right)}} (n1σ12)+(n2σ22)μ1−μ2
其中, μ 1 \mu_1 μ1 和 μ 2 \mu_2 μ2 分别是新药物组和安慰剂组的平均血压, σ 1 \sigma_1 σ1 和 σ 2 \sigma_2 σ2 分别是新药物组和安慰剂组的样本标准差, n1和n2是两组的样本大小。代入计算得到 ∣ Z ∣ = 2.94 > 2.58 |Z|=2.94>2.58 ∣Z∣=2.94>2.58 ,故该药品有非常显著的效果
-
某公司在电商平台上销售其服务,经长期观察发现,不同定价的相关服务成交量有所不同。经数据汇总整理得到下表所示记录:
单价 (元) 91 88 73 62 55 41 销量 (件) 420 450 410 480 460 430 \begin{array}{|l|l|l|l|l|l|l|} \hline \text { 单价 (元) } & 91 & 88 & 73 & 62 & 55 & 41 \\ \hline \text { 销量 (件) } & 420 & 450 & 410 & 480 & 460 & 430 \\ \hline \end{array} 单价 (元) 销量 (件) 914208845073410624805546041430
假设该公司想要推出款新的相关服务。 拟定价为65元,希望预测其销量。请用课程中学到的知识尝试预测该服务可能得销量。注:如使用的算法存在参数 k \mathrm{k} k,令 k = 3 \mathrm{k} = 3 k=3
【解】 计算所有单价点到65的距离,例如,第一个产品的单价为91,距离是 ∣ 65 − 91 ∣ = 26 |65-91|=26 ∣65−91∣=26 . 逐一计算得下表。
单价(元) 91 88 73 62 55 41 距离 26 23 8. 3 10 24 \begin{array}{|l|l|l|l|l|l|l|} \hline \text { 单价(元) } & 91 & 88 & 73 & 62 & 55 & 41 \\ \hline \text { 距离 } & 26 & 23 & 8 . & 3 & 10 & 24 \\ \hline \end{array} 单价(元) 距离 91268823738.62355104124
因为k-3,所以得到价格为73、62和55的产品离目标点最近,得到销量的值分别为410、 480和460,在这种情况下,我们可以简单的使用平均值来计算:
销量 = 410 + 480 + 460 3 = 450 销量=\frac{410+480+460}{3}=450 销量=3410+480+460=450基于一种叫做"kNN"(How old are you ?)的算法。这个算法基于一个观察:相似的事物应该有相似的属性。所以,我们可以通过找出和目标最相似的几个已知对象来预测目标的属性。在这个例子中,我们用这个方法来预测新服务的销量。
这个算法的步骤大致如下:
- 计算目标(在这里是65元的定价)与所有已知对象(在这里是各个定价)之间的距离。这里我们采用的是欧几里得距离,即直接的绝对差值。
- 选择距离最近的k个对象。这里k=3,所以我们选择了定价为73、62和55的服务。
- 对这k个对象的属性(在这里是销量)求平均值,作为对目标属性的预测。所以预测的销量是 (410+480+460)/3 = 450。
-
某厂购买台新的机器, 生产零件长度规定为 10cm.为检验机器性能是否良好,质检员随机抽取了25 件产品,测得平均长度为9.8cm,标准差为0.4cm.假设生产的零件长度服从正态分布,问在显著性水平 a = 0.05 a=0.05 a=0.05 时,该机器的性能是否良好?
(注:经查表已得题目中需要用到的检验置信水平临界值为2.064)。【解】
在这个问题中,我们需要进行单样本t检验。因为我们不知道总体的标准差,所以需要用样本标准差来估计,因此使用t检验而非Z检验。我们已经知道:
- 假设的总体均值 μ0 = 10 cm (因为生产的零件规定长度为10cm)
- 样本平均值 X̄ = 9.8 cm
- 样本标准差 s = 0.4 cm
- 样本数量 n = 25
我们的原假设是:H0:μ = μ0,即机器生产的零件长度平均值为10cm。
对立假设为:H1:μ ≠ μ0,即机器生产的零件长度平均值不为10cm。
我们需要计算t统计量,其公式为:
t = X ‾ − μ 0 s n t = \frac{{\overline{X } - \mu_0}}{{\dfrac{s}{\sqrt{n}}}} t=nsX−μ0
代入我们已知的数值,我们得到:
t = (9.8 - 10) / (0.4/√25) = -0.2 / 0.08 = -2.5
我们的t值-2.5的绝对值为2.5,这个值大于临界值2.064。因此,我们在α=0.05的显著性水平下拒绝原假设,也就是说,我们有足够的证据表明该机器的性能并不良好,因为它生产的零件的平均长度与规定的10cm有显著的差异。
实践设计题(15分)
Q:在双十一中,淘宝是如何缓解双十一带来的购物压力的?
A:
-
预测和分析需求:这方面可以利用一些预测模型,如时间序列分析模型(例如ARIMA、LSTM等),或者基于用户行为的机器学习模型(如随机森林、梯度提升模型等)。这些模型可以从历史销售数据中找出模式和趋势,用于预测双十一时的需求。这可以帮助淘宝更好地管理库存,避免热销商品的缺货或滞销商品的过剩。
-
优化搜索和推荐:淘宝可以使用各种推荐系统算法,如基于内容的推荐,协同过滤,或深度学习模型如神经网络。这些系统可以根据用户的历史行为和喜好,提供个性化的商品推荐,帮助用户在大量商品中快速找到他们感兴趣的商品,从而降低用户的选择压力。
-
流量管理:淘宝可以使用机器学习模型,如回归模型,神经网络等,来预测访问流量的峰值。这些预测可以帮助淘宝提前做好服务器和网络的准备,以避免在流量高峰期出现崩溃或缓慢的情况。
-
动态定价和优惠:淘宝可以使用数据科学中的最优化技术,如线性规划,动态规划等,结合价格敏感度模型(例如线性回归,逻辑回归等),来确定最优的定价和折扣策略。这不仅可以帮助淘宝最大化利润,也可以吸引更多的消费者进行购买。
-
预售策略:淘宝可以使用关联规则挖掘,如Apriori算法,FP-Growth等,来发现那些经常一起购买的商品。这可以帮助淘宝确定哪些商品在双十一前应该一起预售,以便在节日当天减轻购物压力。
这部分没有题,只给了个推荐系统的提示,所以这里简要的学习下推荐系统
推荐系统
推荐系统是一种信息过滤系统,用于预测用户可能对哪些商品或服务感兴趣。推荐系统的主要目标是使用各种算法和数据处理技术,来为用户提供他们可能感兴趣的产品、信息或服务。
推荐系统在许多在线应用中都得到了广泛的应用,例如电子商务网站(例如Amazon和淘宝)、音乐和电影流媒体服务(例如Spotify和Netflix)等。当用户在这些平台上浏览或购买商品时,推荐系统会根据用户的历史行为和其他相关信息(例如用户的地理位置、时间、设备等),为用户推荐他们可能感兴趣的其他商品。
长尾理论(The Long Tail)是由《连线》杂志编辑克里斯·安德森在2004年首次提出的,他在2006年又出版了一本名为《长尾理论》的书来进一步阐述这一理论。这个理论主要描述了在互联网环境下,一种全新的商业模式和消费模式的出现。
传统的经济模式倾向于专注于大众市场,也就是"头部"产品,这些产品的销售量非常大,可以通过规模经济带来大量的利润。然而,长尾理论指出,在线零售商(如亚马逊或Netflix)可以通过降低存储和分发成本,使得大量销量相对较低的"尾部"产品也能够得以生存并带来利润。
这个"长尾"就是指那些小众的、特殊需求的产品或服务,这些产品在传统的零售模式中可能由于销量太小而无法在市场中生存。然而,在互联网的环境下,由于存储和分发的成本大大降低,这些小众的产品可以满足一部分消费者的特殊需求,而累积起来的销量和利润也可能非常可观。
长尾理论的出现,改变了传统的商业模式和营销策略,使得企业开始重视小众市场,提供更为个性化的产品和服务,满足消费者的多样化需求。同时,这种模式也使得消费者可以从更广阔的商品和服务中进行选择,大大提高了消费者的满意度。
推荐系统主要有以下几种类型:
- 基于内容的推荐系统(Content-Based):这类推荐系统主要基于用户之前对某类商品或内容的偏好,为用户推荐类似的商品或内容。比如,如果一个用户经常听某种类型的音乐,那么基于内容的推荐系统就会推荐这类音乐给用户。
- 协同过滤推荐系统(Collaborative Filtering):这类推荐系统主要是基于用户的行为数据,例如用户的购买记录、评分、点击行为等,来预测用户可能对哪些商品感兴趣。协同过滤又可以分为用户基于用户(User-Based)和基于物品(Item-Based)的协同过滤。基于用户的协同过滤会找到与目标用户有相似兴趣的其他用户,然后推荐这些相似用户喜欢的产品给目标用户。而基于物品的协同过滤则是为用户推荐和他们以前购买或喜欢的产品相似的产品。
- 混合推荐系统(Hybrid):这类推荐系统结合了基于内容的推荐和协同过滤推荐的方法,以提高推荐的准确性。
推荐系统的数据源
一般情况下,推荐引擎所需要的数据源包括:
- 要推荐物品或内容的元数据,例如关键字,基因描述等
- 系统用户的基本信息,例如性别,年龄等
- 用户对物品或者信息的偏好,根据应用本身的不同,可能包括用户对物品的评分,用户查看物品的记录,用户的购买记录等。
用户的偏好信息可以分为两类:
(1)显式的用户反馈:这类是用户在网站上自然浏览或者使用网站以外,显式的提供反馈信息,例如,用户对物品的评分,或者对物品的评论。
(2)隐式的用户反馈:这类是用户在使用网站是产生的数据,隐式的反应了用户对物品的喜好,例如,用户购买了某物品,用户查看了某物品的信息等等
基于内容的推荐系统
基于内容的推荐系统(Content-Based Recommendation Systems)的核心思想是,如果一个用户在过去对某一类型的物品或内容表现出了兴趣,那么他/她在未来也有可能对相似类型的物品或内容感兴趣。
工作流程通常包括以下步骤:
- 对物品进行特征化:为每个物品建立一个特性描述符,这些描述符可以是物品的元数据,例如书的作者、电影的导演,或者经过处理的内容数据,例如对书的描述或电影剧本进行自然语言处理得到的关键词。
- 建立用户兴趣模型:根据用户的行为历史(例如,用户看过哪些书、看过哪些电影等),以及可能的反馈(例如评级、评论等),来估计用户对不同特性的兴趣程度。
- 计算物品和用户模型的匹配程度:为了推荐物品,系统会计算每个物品特性描述符和用户兴趣模型之间的匹配程度或相似度。
- 推荐高匹配度的物品:推荐系统会将计算得到的相似度或匹配程度高的物品推荐给用户。
举个例子:用户天天听《雪Distance》,那他大概率会刷到王琳凯的歌,因为都是答辩
协同过滤推荐系统
协同过滤推荐系统(Collaborative Filtering Recommendation Systems)是一种常见的推荐系统算法,其核心思想是基于用户的行为来预测他们对未知物品的兴趣或者评价。
具体来说,如果一个用户A和用户B在过去有相似的行为(例如喜欢相同的电影或购买相同的商品),那么我们可以推断他们有相似的兴趣。因此,如果用户A对某个物品表示出兴趣(例如给一个电影高分或购买了一个商品),而用户B还未对这个物品做出行为,那么我们就可以推荐这个物品给用户B。
协同过滤推荐系统主要有两种类型:基于用户的协同过滤和基于物品的协同过滤。
-
基于用户的协同过滤(UserCF)首先会找到和目标用户兴趣相似的用户群体(也被称为邻居),然后推荐这些邻居喜欢的,而目标用户还未接触过的物品。例如,如果用户A和用户B都喜欢看《权力的游戏》和《冰与火之歌》,并且用户A最近开始看《巨人的陨落》,那么我们就可以推荐《巨人的陨落》给用户B。
UserCF算法的推荐更偏向社会化:适合应用于新闻推荐、微博话题推荐等应用场景,其推荐结果在新颖性方面有一定的优势。随着用户数目的增大,用户相似度计算复杂度越来越高。而且UserCF推荐结果相关性较弱,难以对推荐结果作出解释,容易受大众影响而推荐热门物品。
-
基于物品的协同过滤(ItemCF)则是对于一个物品,找到和它最相似的物品集合,然后推荐这个集合中的物品给喜欢目标物品的用户。例如,如果用户A喜欢看《权力的游戏》,而《权力的游戏》和《冰与火之歌》被很多用户共同喜欢,那么我们就可以推荐《冰与火之歌》给用户A。
ItemCF算法的推荐更偏向于个性化:适合应用于电子商务、电影、图书等应用场景,可以利用用户的历史行为给推荐结果作出解释,让用户更为信服推荐的效果。倾向于推荐与用户已购买商品相似的商品,往往会出现多样性不足、推荐新颖度较低的问题。
这种推荐系统的优点是它可以发现用户的新兴趣,而不仅仅局限于他们过去的行为。然而,它也有一些问题,比如冷启动问题(对于新用户或新物品,由于没有足够的行为数据,很难做出准确的推荐),以及稀疏性问题(由于用户和物品的数量都可能非常大,用户和物品之间的行为矩阵往往非常稀疏,这也会导致推荐的困难)。
基于图的推荐系统
基于图的推荐模型(Graph-Based Recommendation Model)是一种使用图数据结构来描述用户和物品之间关系的推荐系统算法。在这种模型中,用户和物品都被视为图中的节点,而用户的行为(如购买、观看或评分)则被视为连接用户和物品的边。
基于图的推荐模型的基本思想是,通过图的遍历算法(如深度优先搜索或广度优先搜索)、路径分析(如最短路径或最长路径)、以及图的聚类算法等,来发现用户可能感兴趣的新物品。具体的算法和方法可能会根据具体的应用和需求有所不同。
例如,一个简单的基于图的推荐模型可能会使用以下的步骤:
-
根据用户的历史行为,构建一个用户-物品的二分图。在这个图中,用户和物品都是节点,如果一个用户曾经购买过一个物品,那么就在这两个节点之间添加一条边。
-
对于一个目标用户,找出和他有直接连接(即他曾经购买过)的所有物品节点。
-
然后,对于这些物品节点,找出和它们有直接连接的其他用户节点(除了目标用户以外)。
-
最后,对于这些用户节点,找出和它们有直接连接的其他物品节点(除了目标用户已经购买过的物品以外)。这些物品就是我们可以推荐给目标用户的物品。
基于图的推荐模型的优点是,它可以发现用户的新兴趣,而不仅仅局限于他们过去的行为。而且,由于图的结构可以很好地表示用户和物品之间的复杂关系,因此基于图的推荐模型通常可以提供比其他方法更好的推荐结果。然而,处理大规模的图通常需要大量的计算和存储资源,这可能会成为这种模型的一个挑战。
基于位置的推荐算法
基于位置的推荐算法(Location-Based Recommendation Algorithms)是一种利用用户的地理位置信息来进行推荐的系统。这类推荐系统认为,用户的地理位置对他们的兴趣和行为有重要影响,因此在推荐时考虑用户的位置信息可以提高推荐的准确性和满意度。
基于位置的推荐算法的基本思想是,用户在相似地理位置的行为具有一定的相关性。因此,如果我们知道用户在某个位置的行为(例如他们在某个餐馆的评价或他们在某个商店的购物记录),那么我们就可以预测他们在相似位置可能的行为,并据此进行推荐。
例如,假设我们有一个推荐餐馆的应用。用户可以在这个应用上查看餐馆的信息,评价餐馆,并查看其他用户的评价。对于这样一个应用,一个基于位置的推荐算法可能会使用以下的步骤:
-
首先,根据用户的位置(例如他们的GPS坐标或他们所在的城市),找出离他们最近的餐馆。
-
然后,对于这些餐馆,找出在过去被其他在同一地理位置的用户高度评价的餐馆。
-
最后,将这些餐馆推荐给用户。
这种推荐系统的优点是,它可以提供与用户当前的上下文(例如他们的位置和时间)相关的推荐,因此通常可以提供更满意的推荐结果。然而,它也有一些挑战,比如如何准确地获取和处理用户的位置信息,以及如何处理用户位置变化带来的影响等。

















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









